

前言:我在2015年底写过一篇使用基本的Java网络编程抓取一个视频网站上2015年所有电影的下载链接的文章。但是以我现在看来当时的代码有的地方其逻辑无疑还是比较复杂的,因此在接触到更好用的工具(webmagic框架)之后就一直想将当初的代码重构一下,所以也就有了本篇文章
注:之前的那篇文章:[https://www.zifangsky.cn/244.html](https://www.zifangsky.cn/244.html)
一 思路分析
下面我将跟大家一起来分析下如何实现这样的一个爬虫:
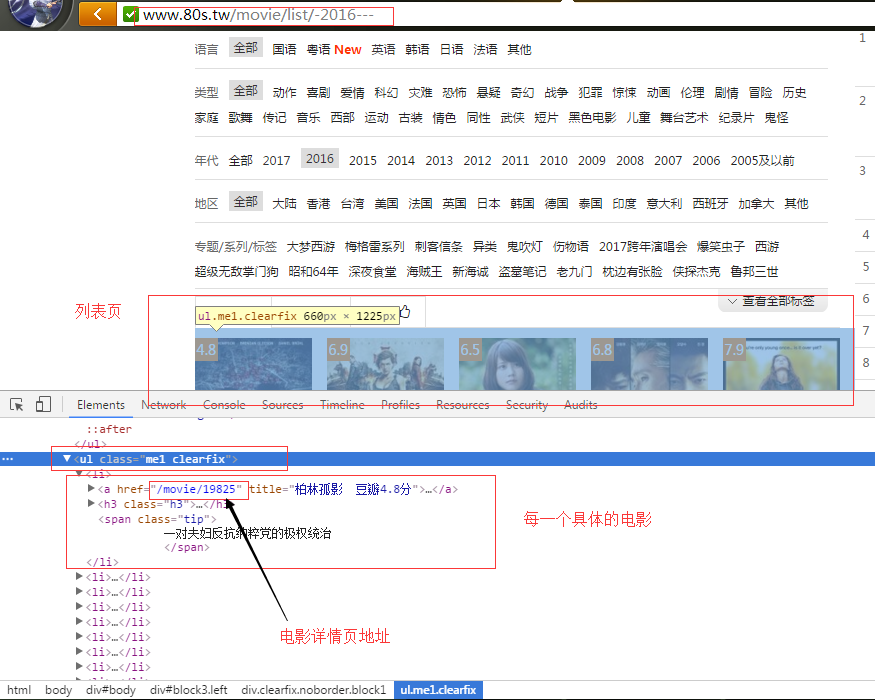
首先观察我们爬虫的起始页面是:http://www.80s.tw/movie/list/-2016—
同时在当前的电影列表页面,每个电影详情页的URL用XPath表达式来表示就是://ul[@class=’me1 clearfix’]/li/a/@href
注:关于XPath表达式的用法可以参考这里的介绍:www.w3school.com.cn/xpath/xpath…
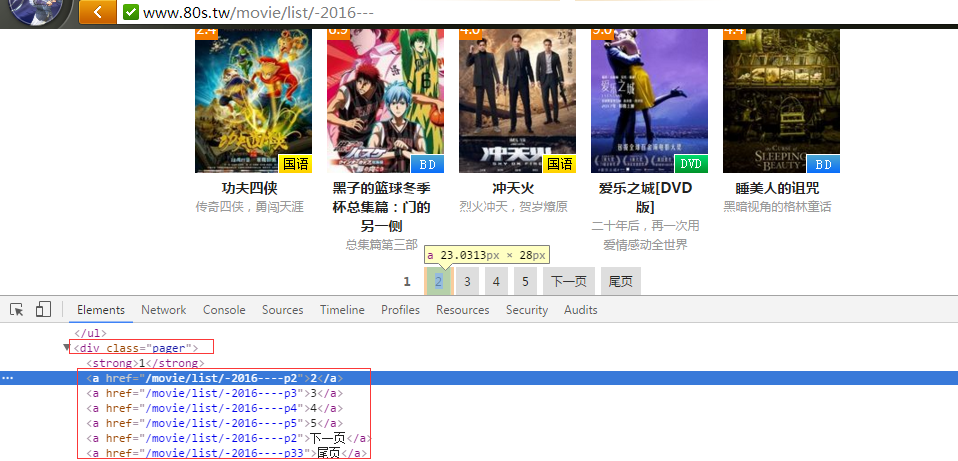
接着,我们继续观察该列表页最下面指向其他列表页的URL,可以发现这类URL如果用XPath表达式来表示就是:
//div[@class=’pager’]/a/@href
当然,上面我们介绍了电影列表页如何获取电影详情页以及其他列表页的XPath表达式。那么,如果是电影详情页面(PS:http://www.80s.tw/movie/17807 这种页面),我们该如何获取电影的名字和下载链接呢?下面我们就一起来分析下吧:
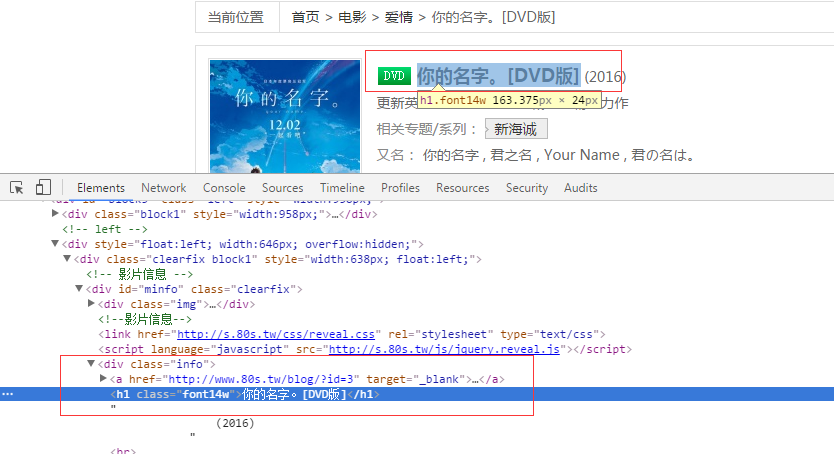
从上面的截图可以看出,很显然这里是一个很好的获取电影名字的地方。那么它对应的XPath表达式就是:
//div[@class=’info’]/h1/text()当然,如果你需要获取其他的如导演名字、电影简介之类的信息也可以根据同样的原理来获取
接下来我们再看看电影的下载链接该如何来获取:
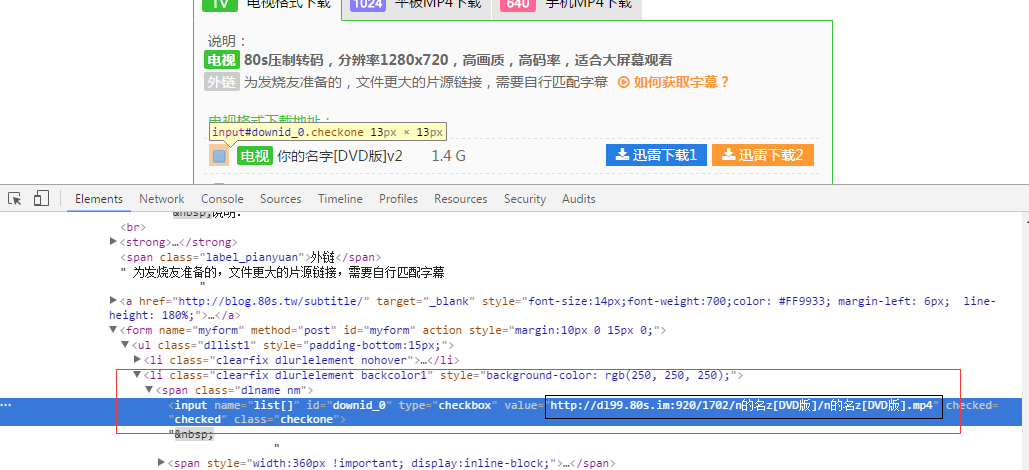
从上面的截图可以看出,这里出现了电影的下载地址,它对应的XPath表达式就是:
//li[@class=’clearfix dlurlelement backcolor1′]/span[@class=’dlname nm’]/input/@value
好了,我们上面已经将在代码中需要获取的关键信息的XPath表达式都找到了,接下来就可以正式写代码来实现了
二 代码实现
在代码实现部分我决定采用webmagic框架,因为这样比使用基本的的Java网络编程要简单得多
注:关于webmagic框架的一些基本用法可以参考我之前写过的这篇文章:www.zifangsky.cn/853.html
(1)爬虫的核心代码:
package cn.zifangsky.webmagic.movie;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
public class MovieSpider implements PageProcessor{
private Site site = Site.me().setTimeOut(30000).setRetryTimes(3)
.setSleepTime(1000).setCharset("UTF-8");
@Override
public Site getSite() {
Set<Integer> acceptStatCode = new HashSet<>();
acceptStatCode.add(200);
site = site.setAcceptStatCode(acceptStatCode).addHeader("Accept-Encoding", "/")
.setUserAgent(UserAgentUtils.radomUserAgent());
return site;
}
@Override
public void process(Page page) {
String url = page.getUrl().toString();
Pattern pattern1 = Pattern.compile("http://www.80s.tw/movie/list/-2016---(-p\\d*)?");
Matcher matcher1 = pattern1.matcher(url);
Pattern pattern2 = Pattern.compile("/movie/\\d+");
Matcher matcher2 = pattern2.matcher(url);
//列表页面
if(matcher1.find()){
//电影详情页URL集合
List<String> moviePageUrls = page.getHtml().xpath("//ul[@class='me1 clearfix']/li/a/@href").all();
if(moviePageUrls != null && moviePageUrls.size() > 0){
//将当前列表页的所有电影页面添加进去
page.addTargetRequests(moviePageUrls);
}
//当前列表页中的其他列表页的链接
List<String> listUrls = page.getHtml().xpath("//div[@class='pager']/a/@href").all();
if(listUrls != null && listUrls.size() > 0){
page.addTargetRequests(listUrls);
}
}else if(matcher2.find()){ //电影页面
//获取电影名字
String movieName = page.getHtml().xpath("//div[@class='info']/h1/text()").toString();
//获取电影播放链接
String movieUrl = page.getHtml().xpath("//li[@class='clearfix dlurlelement backcolor1']/span[@class='dlname nm']/input/@value").toString();
Movie movie = new Movie(movieName, movieUrl);
page.putField("movie", movie); //后面做数据的持久化
}
}
}代码中的XPath表达式都已经在上面专门介绍了,其他代码自行参考注释来理解即可,这里就不多做解释了
实体类Movie:
package cn.zifangsky.webmagic.movie;
public class Movie {
private String movieName;
private String movieLink;
public Movie() {
}
public Movie(String movieName, String movieLink) {
this.movieName = movieName;
this.movieLink = movieLink;
}
public String getMovieName() {
return movieName;
}
public void setMovieName(String movieName) {
this.movieName = movieName;
}
public String getMovieLink() {
return movieLink;
}
public void setMovieLink(String movieLink) {
this.movieLink = movieLink;
}
@Override
public String toString() {
return "Movie [movieName=" + movieName + ", movieLink=" + movieLink + "]";
}
}UserAgentUtils.java:
package cn.zifangsky.webmagic.movie;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class UserAgentUtils {
/**
* 从预定义的User-Agent列表中随机抽取一个返回
* @return
*/
public static String radomUserAgent(){
List<String> list = new ArrayList<>();
list.add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36");
list.add("Mozilla/5.0 (Windows NT 6.3; rv:36.0) Gecko/20100101 Firefox/36.04");
list.add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
list.add("Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:52.0) Gecko/20100101 Firefox/52.0");
list.add("Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/4.0; InfoPath.2; SV1; .NET CLR 2.0.50727; WOW64)");
list.add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36");
list.add("Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko");
list.add("Mozilla/4.0 (compatible; MSIE 6.0b; Windows NT 5.1)");
list.add("Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0");
list.add("Mozilla/5.0 (X11; Linux i686; rv:40.0) Gecko/20100101 Firefox/40.0");
list.add("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36");
list.add("Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)");
list.add("Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11");
list.add("Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25");
list.add("Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)");
list.add("Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1");
Random random = new Random();
return list.get(random.nextInt(list.size()));
}
}注:这个User-Agent信息可以省略
(2)数据的持久化:
package cn.zifangsky.webmagic.movie;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public class SaveDataPipeline implements Pipeline {
/**
* 爬虫数据的持久化
*/
@Override
public void process(ResultItems resultItems, Task task) {
Movie movie = resultItems.get("movie");
if (movie != null) {
try {
Connection connection = JDBCConnection.getConnection();
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, movie.getMovieName());
pStatement.setString(2, movie.getMovieLink());
pStatement.executeUpdate();
pStatement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}这里主要是使用了基本的JDBC将数据保存到数据库中,对应的获取JDBC连接代码是:
package cn.zifangsky.webmagic.movie;
import java.sql.Connection;
import java.sql.DriverManager;
public class JDBCConnection {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String url = "jdbc:mysql://127.0.0.1:3306/movie?useUnicode=true&characterEncoding=utf-8";
private static final String username = "root";
private static final String password = "root";
public static Connection getConnection(){
try {
Class.forName(driver);
return DriverManager.getConnection(url, username, password);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}同样,对应的SQL语句是:
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for movie
-- ----------------------------
DROP TABLE IF EXISTS `movie`;
CREATE TABLE `movie` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`MovieName` varchar(500) DEFAULT NULL,
`MovieLink` varchar(500) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;(3)测试:
package cn.zifangsky.webmagic.movie;
import org.junit.Test;
import us.codecraft.webmagic.model.OOSpider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
public class TestSpider {
@Test
public void saveMovie(){
OOSpider.create(new MovieSpider())
.addUrl("http://www.80s.tw/movie/list/-2016---")
.addPipeline(new ConsolePipeline())
.addPipeline(new SaveDataPipeline())
.thread(5)
.run();
}
}运行这个单元测试之后,等待一会时间之后观察数据库就可以发现电影的下载链接已经全部获取到了:
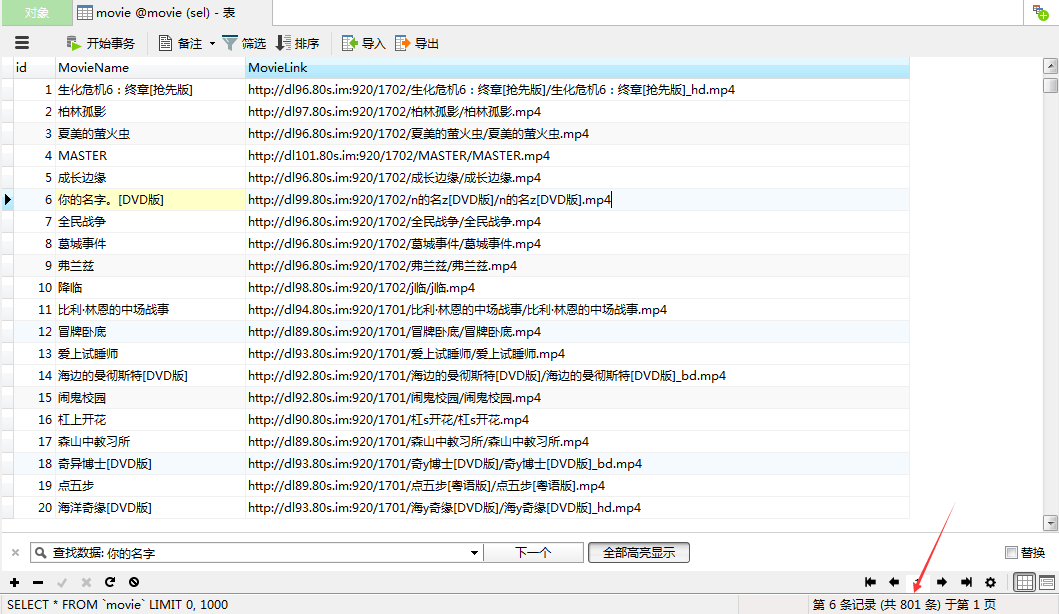
并且我们可以发现:到目前为止这个视频网站收录的2016年的电影一共有801个。至此,整个爬虫代码就全部结束了。代码逻辑实际是很简单的,我这篇文章的目的主要还是重构之前写过的那个类似的代码
最后,我已经将抓取到的电影结果上传到网盘了,感兴趣的童鞋可以下载来看看:pan.baidu.com/s/1pLwbXSf
