

回家很久了,实在熬不住,想起来爬点数据玩一玩,之前自己笔记本是win7加ubuntu16.04双系统,本打算在ubuntu里写代码的,可是回到家ubuntu打开一直是紫屏,百度知乎方法用了也没解决,厉害的兄弟可以教下我哦,过年有红包哦!!然后就还是在win7下开始写代码了(电脑太卡,一直不想装Python),今天爬的是豆瓣音乐top250,比较简单,主要是练练手。
代码
import requests
import re
from bs4 import BeautifulSoup
import time
import pymongo
client = pymongo.MongoClient('localhost', 27017)
douban = client['douban']
musictop = douban['musictop']
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
urls = ['https://music.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)]
def get_url_music(url):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
music_hrefs = soup.select('a.nbg')
for music_href in music_hrefs:
get_music_info(music_href['href'])
time.sleep(2)
def get_music_info(url):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
names = soup.select('h1 > span')
authors = soup.select('span.pl > a')
styles = re.findall('<span class="pl">流派:</span> (.*?)<br />',wb_data.text,re.S)
times = re.findall('<span class="pl">发行时间:</span> (.*?)<br />',wb_data.text,re.S)
contents = soup.select('span.short > span')
if len(names) == 0:
name = '缺失'
else:
name = names[0].get_text()
if len(authors) == 0:
author = '佚名'
else:
author = authors[0].get_text()
if len(styles) == 0:
style = '未知'
else:
style = styles[0].split('\n')[0]
if len(times) == 0:
time = '未知'
else:
time = times[0].split('-')[0]
if len(contents) == 0:
content = '无'
else:
content = contents[0].get_text()
info = {
'name':name,
'author':author,
'style':style,
'time':time,
'content':content
}
musictop.insert_one(info)
for url in urls:
get_url_music(url)1加了请求头(本来没加,调试几次突然没数据了,加了请求头开始也没好,后来又好了,可能是网络原因)
2这次是进入信息页爬的数据(上次爬电影没采用这种方法,缺少了部分数据)
3数据的预处理用了很多if函数,厉害的兄弟有什么优化的方法。
数据分析
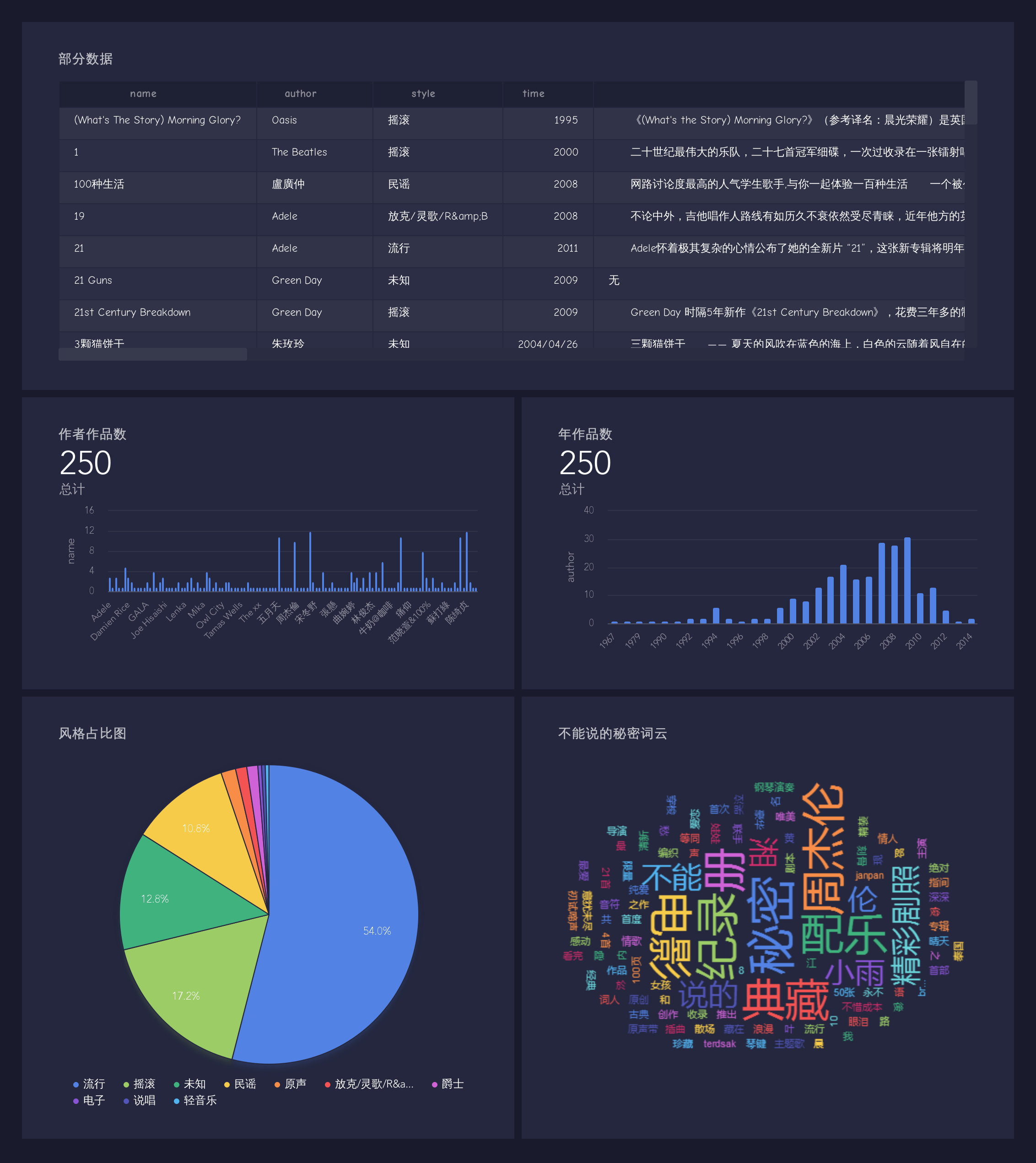
1部分数据可以见上图
2中国音乐作者还是很多的,哈哈。
3随着音乐设备和网络的普及,流行音乐的发展,可以看出2000年后作品越来越多,到2010年又积极下滑(经典就是经典,无法吐槽现在的音乐)
4风格大家可以看出流行,摇滚,民谣占了一大半。
5最后弄了一首周董的《不能说的秘密》做词云,想想小时候都是回忆啊。
问题
import requests
import re
from bs4 import BeautifulSoup
import time
import pymysql
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='test', port=3306, charset='utf8')
cursor = conn.cursor()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
urls = ['https://music.douban.com/top250?start={}'.format(str(i)) for i in range(0,225,25)]
def get_url_music(url):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
music_hrefs = soup.select('a.nbg')
for music_href in music_hrefs:
get_music_info(music_href['href'])
time.sleep(2)
def get_music_info(url):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
names = soup.select('h1 > span')
authors = soup.select('span.pl > a')
styles = re.findall('<span class="pl">流派:</span> (.*?)<br />',wb_data.text,re.S)
times = re.findall('<span class="pl">发行时间:</span> (.*?)<br />',wb_data.text,re.S)
contents = soup.select('span.short > span')
if len(names) == 0:
name = '缺失'
else:
name = names[0].get_text()
if len(authors) == 0:
author = '佚名'
else:
author = authors[0].get_text()
if len(styles) == 0:
style = '未知'
else:
style = styles[0].split('\n')[0]
if len(times) == 0:
time = '未知'
else:
time = times[0].split('-')[0]
if len(contents) == 0:
content = '无'
else:
content = contents[0].get_text()
info = {
'name':name,
'author':author,
'style':style,
'time':time,
'content':content
}
cursor.execute("use test")
cursor.execute("insert into doubanmusic250 (name,author,style,time,content) values(%s,%s,%s,%s,%s)", (name,author,style,time,content))
conn.commit()
for url in urls:
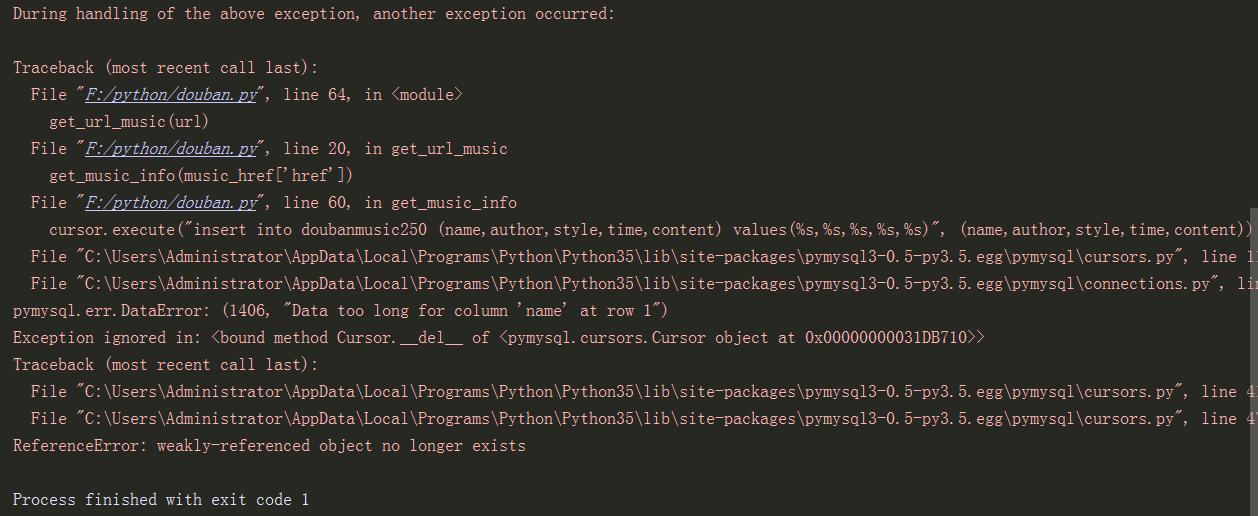
get_url_music(url)最近再学mysql,想用Python连接MySQL的,可是出错,附上代码,大牛们前来指导。代码出错图:
祝福
在这里住大家新年快乐,鸡年大吉。
