

这是全栈数据工程师养成攻略系列教程的第七期:7 爬虫 Http请求和Chrome。
我们在浏览网页时,网页上显示的文字和图片等数据从何而来?为了弄清这一点,需要首先了解下什么是Http请求。
访问一个链接
首先在浏览器中访问一个网页链接:kaoshi.edu.sina.com.cn/college/sco…,这是由新浪教育提供的一个高考信息查询网站。
每个网页链接,或者称作url,通常包含以下几个部分,协议://域名:端口/路由?参数。
- 协议:数据传输所使用的协议,例如
http; - 域名:所访问服务器的域名,例如
kaoshi.edu.sina.com.cn,如果没有域名则为服务器IP; - 端口:链接所使用的端口,Http请求的默认端口是80,可以省略;
- 路由:不同的路由会请求到不同的功能,例如
college/scorelist请求的是查看大学的分数线列表这一功能; - 参数:请求数据时所提供的参数,参数的
key和value由=连接,参数之间以&分隔,例如tab=batch&wl=1&local=2&batch=&syear=2013指定了返回2013年的数据。
可以在终端或CMD中使用 ping 访问某一个url,测试是否能正常连接,并且查看域名所对应的IP。
ping kaoshi.edu.sina.com.cn在浏览器中访问一个url,我们就能看到对应网页上的文字和图片等内容,这一过程主要包括以下几个步骤,其中的数据传输大多是基于Http请求实现的。
- 浏览器向所访问的服务器请求指定的url;
- 服务器根据url返回相应的数据;
- 浏览器加载所返回的数据,经渲染后以网页的形式呈现给用户。
Chrome浏览器
在正式开始介绍Http请求之前,我们来了解一下Chrome浏览器,以熟悉一些必须的背景知识。
Chrome是一款优秀的浏览器,渲染效果和调试功能都非常强大。在Chrome浏览器中访问网页后,在页面上右击鼠标,可以找到“显示网页源代码(View Source)”和“检查(Inspect)”两项功能。前者可以查看网页的静态源代码,而后者提供了相当强大的调试功能。
以之前访问的新浪教育网页为例,在网页的某一个元素,例如页面顶部的 新浪首页 上,右键并点击“检查”之后将会出现以下界面,即Chrome提供的“开发者工具(Developer Tools)”。默认显示在 Elements 标签页上,并且高亮右键点击元素所对应的代码。
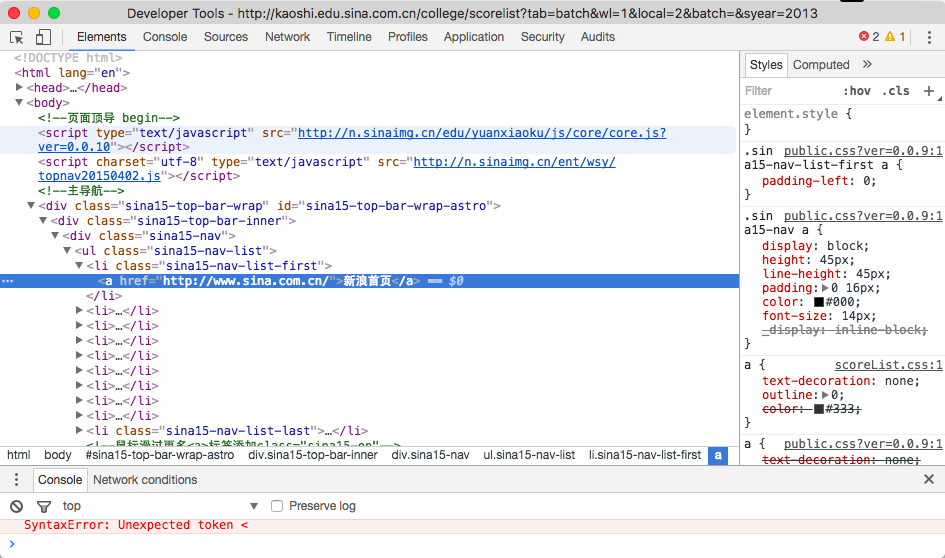
开发者工具包括 Elements 、 Console 、 Sources 、 Network 等多个标签页,分别提供了以下功能:
- Elements:显示网页经过渲染之后的结构,可以任意调整和修改网页元素,并即时显示修改结果;
- Console:打印变量信息,用于代码调试,网页运行过程中产生的警告和报错也会出现在这里;
- Sources:查看网页所使用到的全部资源文件;
- Network:查看网页所请求的各类资源文件及其对应的请求时间。
Network 标签页会记录网页在渲染过程中所请求的各类资源文件及其对应的请求时间。大多数网页只在一开始加载的时候请求各类资源文件,加载完毕后不再请求;也有一些网页在加载完毕后仍定时请求一些资源,用于动态更新页面上的内容。所访问的网页使用了哪些资源?用户浏览的过程中网页做了哪些事情?这些都可以在 Network 标签页中找到答案。
Network 标签页中的资源文件主要分为以下几大类:
- All:不加筛选条件,所请求的全部资源文件;
- XHR:异步请求的数据;
- JS:js代码文件;
- CSS:css样式文件;
- Img:jpg、png等图片文件;
- Media:媒体资源文件;
- Font:字体文件;
- Doc:静态html文档。
我们的目的是写爬虫,所以主要关注 XHR 、 JS 和 Doc 等资源类型,可以找到网页所使用到的一些数据。举例来说,还是之前访问的新浪教育网页,可以在 XHR 中找到这样的一个链接,kaoshi.edu.sina.com.cn/?p=college&…1485309859918&=1485309859919。将 callback 之后的内容去掉,在浏览器中访问 kaoshi.edu.sina.com.cn/?p=college&…,就会返回相应的json数据。可以将json文本全部复制,并粘贴到 www.bejson.com/ 等在线json校验格式化工具里,即可发现这是网页中使用到的大学基本信息数据。
所以在写爬虫的时候,我们需要对目标网页进行分析。一方面是直接把目标页面请求下来,经过解析后获取需要的字段;另一方面是请求网页所使用到的一些资源,或许能够更方便地拿到丰富的格式化数据。
Http请求
掌握了和Chrome浏览器相关的内容,我们再来介绍下Http请求,因为以上所请求的大多数资源都是基于Http协议获取的。
Http是目前最通用的Web传输协议。无论是用电脑看网站,还是用手机玩游戏,客户端和服务端之间的数据传输大多都是基于Http协议。Http请求中最常见的两类分别是 GET 和 POST。
GET 请求,顾名思义,是去拿数据。在GET请求中,可以包含或不包含参数。如果包含参数的话,参数直接写在url中,因此是显式可见的,即 所访问的服务 + 参数。例如之前提到的 kaoshi.edu.sina.com.cn/?p=college&… 就是一个GET请求,参数指明了我们需要进行的操作是获取全部大学的信息数据。
POST 请求一般包含参数,向服务器提交url和参数,然后获取相应的数据。在POST请求中,参数并不是直接写在url中,而是在数据包内部提供,所以不是显示可见的,相对GET请求而言更加安全。
在浏览器中访问以下链接:shuju.wdzj.com/plat-info-5…,这是 网贷之家 提供的关于陆金所的相关数据。当我们在网页上访问数据时,可以对应地在 Network 中找到这样一项请求:shuju.wdzj.com/plat-info-t…。从图中可以看出请求的类型是POST,所提交的参数在Form Data中可以找到,一共指定了wdzjPlatId、type、target1、target2四个参数,分别对应P2P平台的Id、数据汇总类型、指标1、指标2。
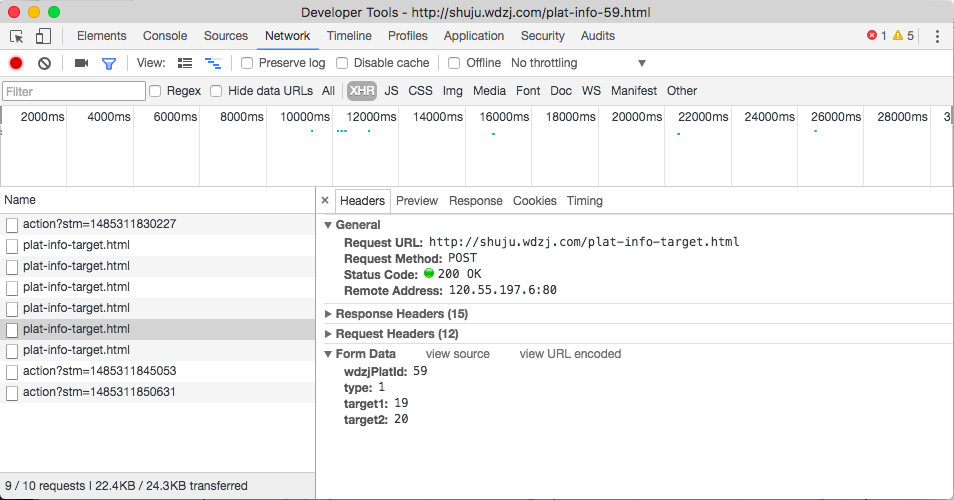
如果我们直接在浏览器中访问 shuju.wdzj.com/plat-info-t…,即将POST请求组装成一个GET请求,把参数直接写在url里面访问,服务器将报错,无法获得正确的数据,从这个例子可以看出POST请求和GET请求的不同。
Url类型
回过头来总结下之前访问过的url。同样是在浏览器中访问,有的url返回的是经过渲染后的复杂页面,有的url仅返回json文本数据。因此,可以将url分为以下两大类:
- Html:返回html结构化页面,经浏览器渲染后呈现给用户,通常是多个资源融合后的结果,例如 kaoshi.edu.sina.com.cn/college/sco…;
- API:Application Programming Interfaces,即应用编程接口。请求后完成某些功能,可以是返回指定的数据,例如 kaoshi.edu.sina.com.cn/?p=college&…。
对于以上两大类url,在写爬虫时我们会采取不同的处理方法。能找到所需的API最好,因为格式化数据更便于处理。如果只有Html,就需要对渲染后的页面进行分析,通过一些解析工具提取出想要的字段。
视频链接:Http请求和Chrome
