

專 欄
blog:http://ipytlab.com
github:https://github.com/PytLab
前言
并行计算是使用并行计算机来减少单个计算问题所需要的时间,我们可以通过利用编程语言显式的说明计算中的不同部分如何再不同的处理器上同时执行来设计我们的并行程序,最终达到大幅度提升程序效率的目的。
众所周知,Python中的GIL限制了Python多线程并行对多核CPU的利用,但是我们仍然可以通过各种其他的方式来让Python真正利用多核资源, 例如通过C/C++扩展来实现多线程/多进程, 以及直接利用Python的多进程模块multiprocessing来进行多进程编程。
本文主要尝试仅仅通过python内置的multiprocessing模块对自己的动力学计算程序来进行优化和效率提升,其中:
- 实现了单机利用多核资源来实现并行并进行加速对比
- 使用manager模块实现了简单的多机的分布式计算
本文并不是对Python的multiprocessing模块的接口进行翻译介绍,需要熟悉multiprocessing的童鞋可以参考官方文档https://docs.python.org/2/library/multiprocessing.html 。
正文
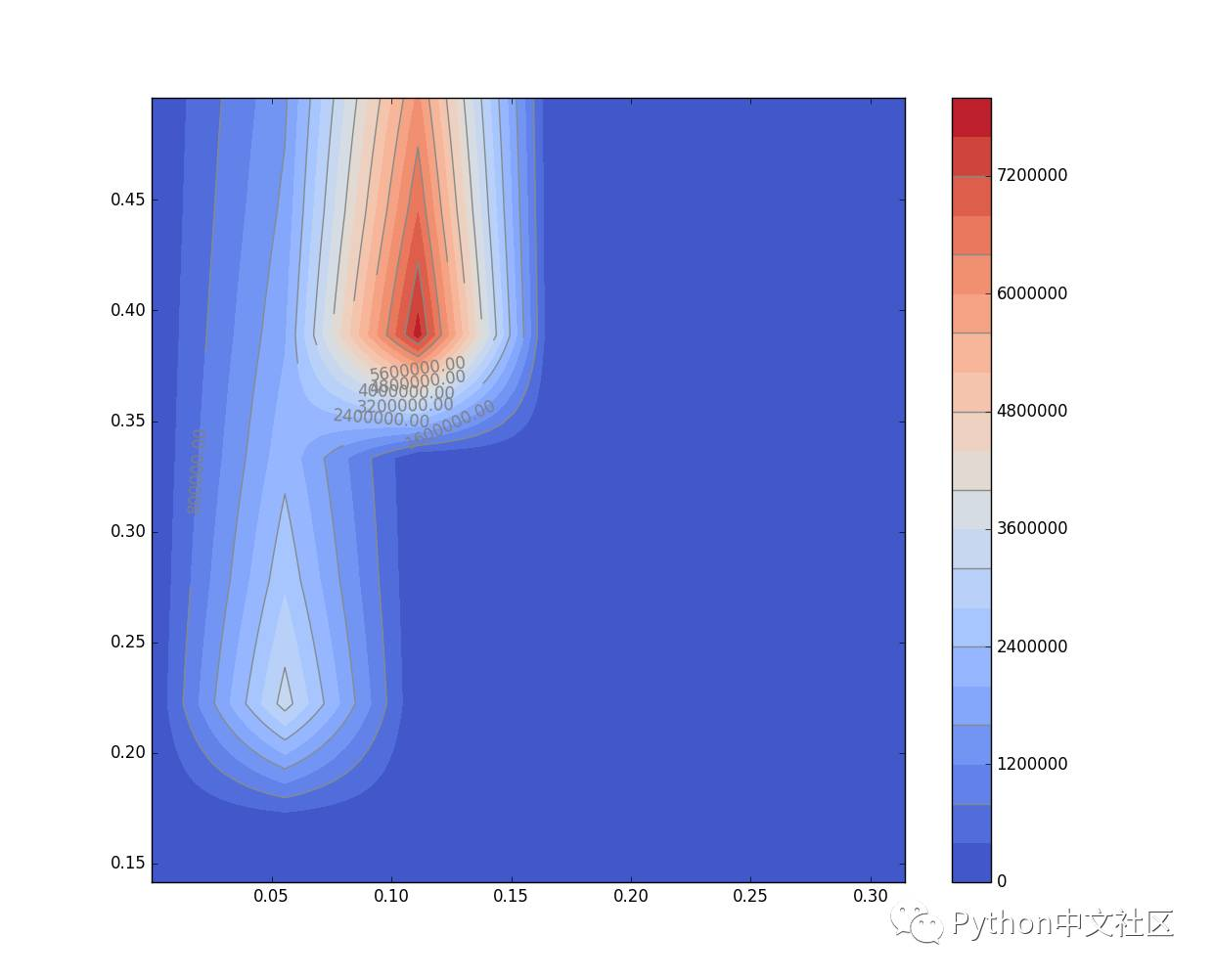
最近想用自己的微观动力学程序进行一系列的求解并将结果绘制成二维Map图进行可视化,这样就需要对二维图上的多个点进行计算并将结果收集起来并进行绘制,由于每个点都需要进行一次ODE积分以及牛顿法求解方程组,因此要串行地绘制整张图可能会遇到极低的效率问题尤其是对参数进行测试的时候,每画一张图都需要等很久的时间。其中绘制的二维图中每个点都是独立计算的,于是很自然而然的想到了进行并行化处理。
串行的原始版本
由于脚本比较长,而且实现均为自己的程序,脚本的大致结构如下, 本质是一个二重循环,循环的变量分别为反应物气体(O2 和 CO)的分压的值:

整体过程就这么简单,我需要做的就是使用multiprocessing的接口来对这个二重循环进行并行化。
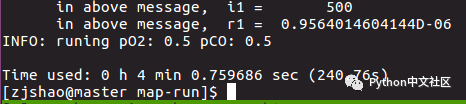
使用单核串行绘制100个点所需要的时间如下, 总共花了240.76秒:
二维map图绘制的效果如下:
进行多进程并行处理
multiprocessing模块
multiprocessing模块提供了类似threading模块的接口,并对进程的各种操作进行了良好的封装,提供了各种进程间通信的接口例如Pipe
, Queue等等,可以帮助我们实现进程间的通信,同步等操作。
使用Process类来动态创建进程实现并行
multiprocessing模块提供了Process能让我们通过创建进程对象并执行该进程对象的
start方法来创建一个真正的进程来执行任务,该接口类似threading
模块中的线程类Thread.
但是当被操作对象数目不大的时候可以使用Process动态生成多个进程,但是如果需要的进程数一旦很多的时候,手动限制进程的数量以及处理不同进程返回值会变得异常的繁琐,因此这个时候我们需要使用进程池来简化操作。
使用进程池来管理进程
multiprocessing模块提供了一个进程池Pool类,负责创建进程池对象,并提供了一些方法来讲运算任务offload到不同的子进程中执行,并很方便的获取返回值。例如我们现在要进行的循环并行便很容易的将其实现。
对于这里的单指令多数据流的并行,我们可以直接使用Pool.map()来将函数映射到参数列表中。
Pool.map其实是map函数的并行版本,此函数将会阻塞直到所有进程全部结束,而且此函数返回的结果顺序仍然不变。
首先,我先把针对每对分压数据的处理过程封装成一个函数,这样可以将函数对象传递给子进程执行。
使用两个核心进行计算,计算时间从240.76s降到了148.61秒, 加速比为1.62

对不同核心的加速效果进行测试
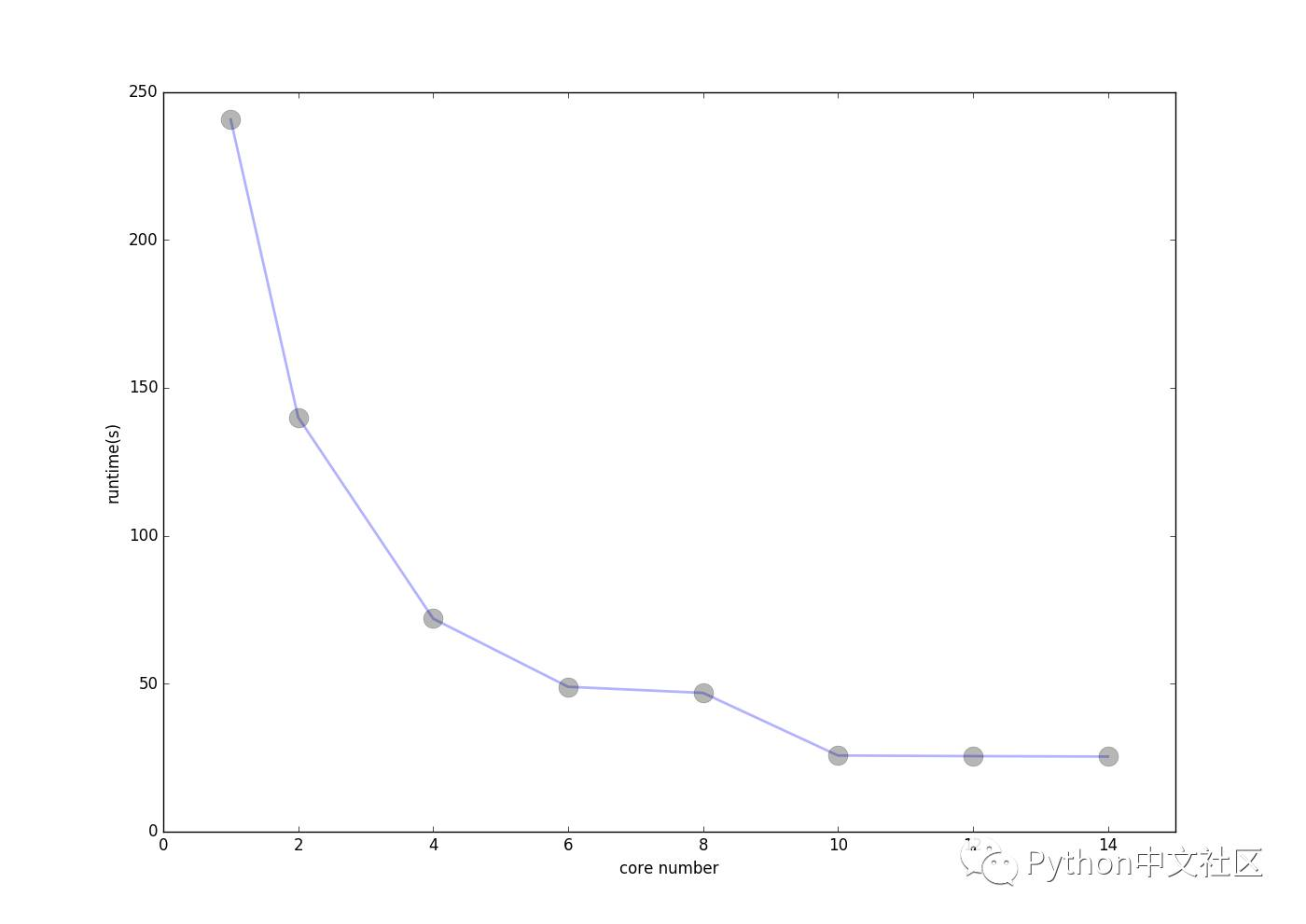
为了查看使用不同核心数对程序效率的改善,我对不同的核心数和加速比进行了测试绘图,效果如下:
运行核心数与程序运行时间:
运行核心数与加速比:

可见,由于我外层循环只循环了10次因此使用的核心数超过10以后核心数的增加并不能对程序进行加速,也就是多余的核心都浪费掉了。
使用manager实现简单的分布式计算
前面使用了multiprocessing包提供的接口我们使用了再一台机器上进行多核心计算的并行处理,但是multiprocessing的用处还有更多,通过multiprocessing.managers模块,我们可以实现简单的多机分布式并行计算,将计算任务分布到不同的计算机中运行。
Managers提供了另外的多进程通信工具,他提供了在多台计算机之间共享数据的接口和数据对象,这些数据对象全部都是通过代理类实现的,比如ListProxy
和DictProxy等等,他们都实现了与原生list
和dict相同的接口,但是他们可以通过网络在不同计算机中的进程中进行共享。
关于managers模块的接口的详细使用可以参考官方文档:https://docs.python.org/2/library/multiprocessing.html#managers
好了现在我们开始尝试将绘图程序改造成可以在多台计算机中分布式并行的程序。改造的主要思想是:
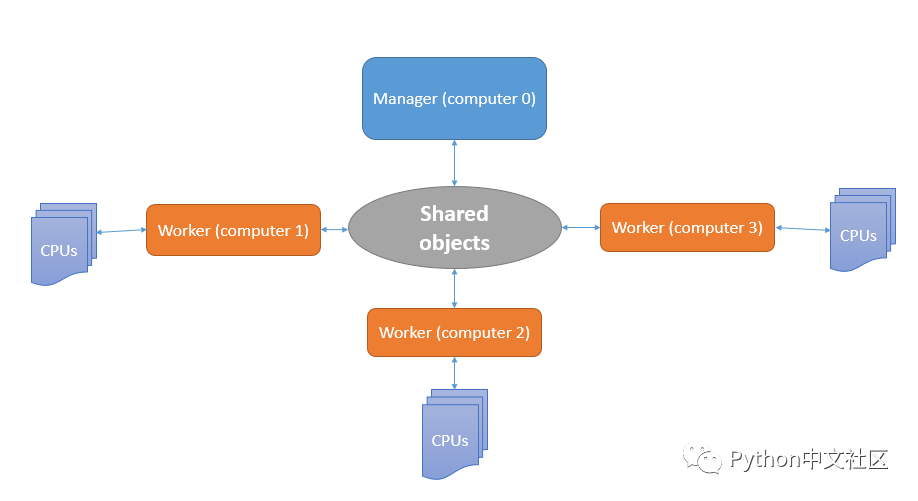
1. 使用一台计算机作为服务端(server),此台计算机通过一个Manager对象来管理共享对象,任务分配以及结果的接收,并再收集结果以后进行后处理(绘制二维map图)。
2. 其他多台计算机可以作为客户端来接收server的数据进行计算,并将结果传到共享数据中,让server可以收集。同时再client端可以同时进行上文所实现的多进程并行来充分利用计算机的多核优势。
大致可总结为下图:
服务进程
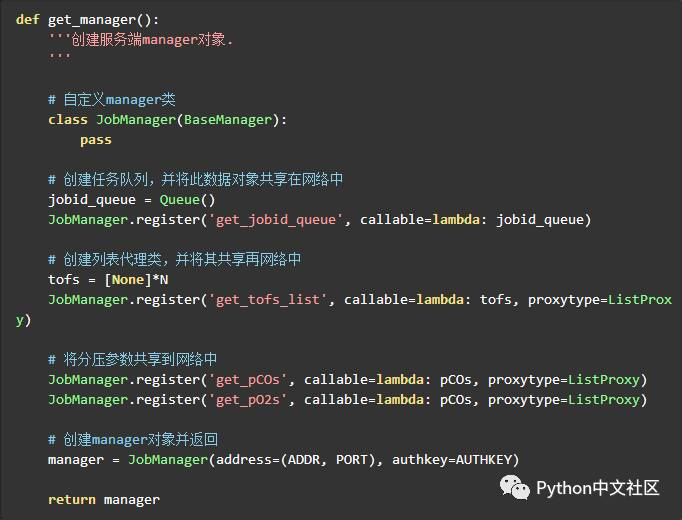
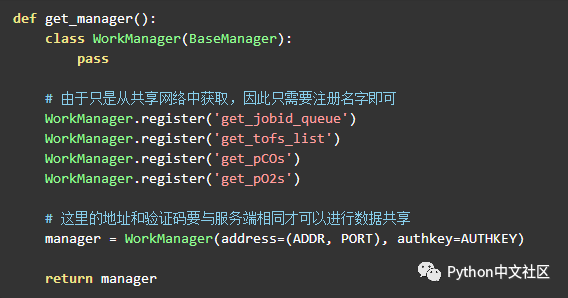
首先服务端需要一个manager对象来管理共享对象
-
BaseManager.register是一个类方法,它可以将某种类型或者可调用的对象绑定到manager对象并共享到网络中,使得其他在网络中的计算机能够获取相应的对象。
例如,
JobManager.register('get_jobid_queue', callable=lambda: jobid_queue)我就将一个返回任务队列的函数对象同manager对象绑定并共享到网络中,这样在网络中的进程就可以通过自己的manager对象的get_jobid_queue方法得到相同的队列,这样便实现了数据的共享. -
创建manager对象的时候需要两个参数,
-
address, 便是manager所在的ip以及用于监听与服务端连接的端口号,例如我如果是在内网中的
192.168.0.1地址的5000端口进行监听,那么此参数可以是('192.169.0.1, 5000)` -
authkey, 顾名思义,就是一个认证码,用于验证客户端时候可以连接到服务端,此参数必须是一个字符串对象.
进行任务分配
上面我们将一个任务队列绑定到了manager对象中,现在我需要将队列进行填充,这样才能将任务发放到不同的客户端来进行并行执行。
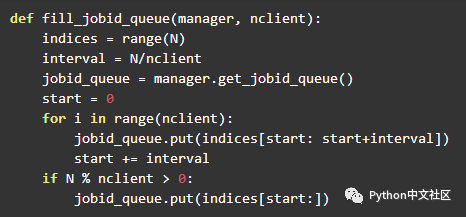
这里所谓的任务其实就是相应参数在list中的index值,这样不同计算机中得到的结果可以按照相应的index将结果填入到结果列表中,这样服务端就能在共享的网络中收集各个计算机计算的结果。
启动服务端进行监听
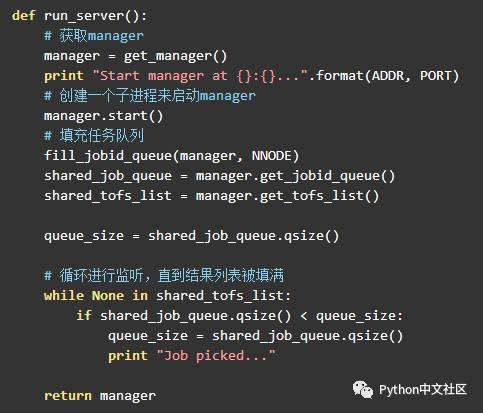
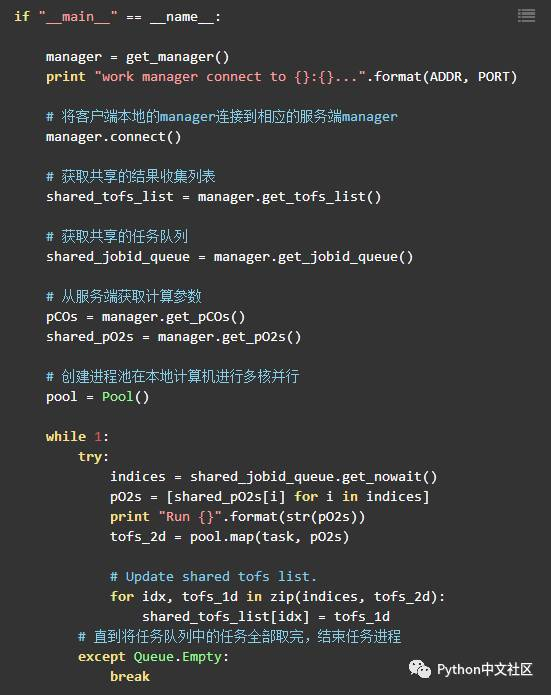
任务进程
服务进程负责进行简单的任务分配和调度,任务进程则只负责获取任务并进行计算处理。
在任务进程(客户端)中基本代码与我们上面单机中的多核运行的脚本基本相同(因为都是同一个函数处理不同的数据),但是我们也需要为客户端创建一个manager来进行任务的获取和返回。
在客户端我们仍然可以多进程利用多核资源来加速计算。
下面我将在3台在同一局域网中的电脑来进行简单的分布式计算测试,
- 其中一台是实验室器群中的管理节点, 内网ip为
10.10.10.245
- 另一台为集群中的一个节点, 共有12个核心
- 最后一台为自己的本本,4个核心
-
先在服务端运行服务脚本进行任务分配和监听:
python server.py
-
在两个客户端运行任务脚本来获取任务队列中的任务并执行
python worker.py
当任务队列为空且任务完成时,任务进程终止; 当结果列表中的结果收集完毕时,服务进程也会终止。
执行结果如下图:
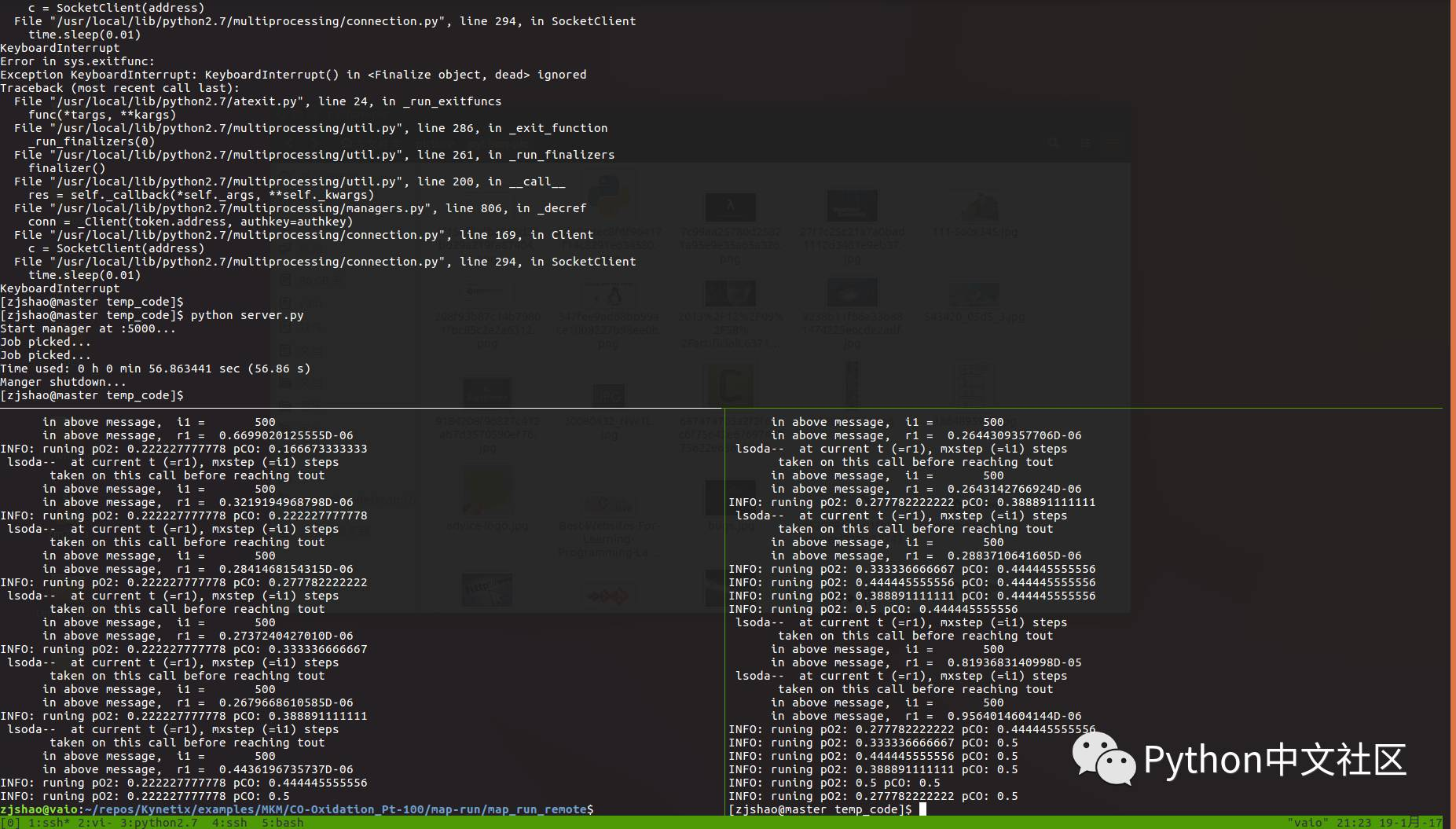
上面的panel为服务端监听,左下为自己的笔记本运行结果,右下panel为集群中的其中一个节点。
可见运行时间为56.86s,无奈,是我的本子脱了后腿(-_-!)
总结
本文通过python内置模块multiprocessing实现了单机内多核并行以及简单的多台计算机的分布式并行计算,multiprocessing为我们提供了封装良好并且友好的接口来使我们的Python程序更方面利用多核资源加速自己的计算程序,希望能对使用python实现并行话的童鞋有所帮助。
参考
ARTICLES近期热门文章
⊙生成器:
关于生成器的那些事儿
⊙爬虫代理:
如何构建爬虫代理服务
⊙地理编码:
怎样用Python实现地理编码
⊙nginx日志:
使用Python分析nginx日志
⊙ 淘宝女郎:
一个批量抓取淘女郎写真图片的爬虫
⊙ IP代理池:
突破反爬虫的利器——开源IP代理池
⊙ 布隆去重:
基于Redis的Bloomfilter去重(附代码)
⊙ 内建函数:
Python中内建函数的用法
⊙ QQ空间爬虫 :
QQ空间爬虫最新分享,一天 400 万条数据
⊙ 对象:
Python教你找到最心仪对象
⊙ 线性回归:
Python机器学习算法入门之梯度下降法实现线性回归
⊙ 匿名代理池:
进击的爬虫:用Python搭建匿名代理池
⊙ 发射导弹:
Python发射导弹的正确姿势
在公众号底部回复上述关键词可直接打开相应文章

Python 中 文 开 发 者 的 精 神 家 园
www.python-cn.com


致力于成为
国内最好的Python社区
QQ群:152745094
专栏作者申请邮箱
sinoandywong@gmail.com
— Life is short,we use Python —社区在节后计划推出图文直播模块PyLive,如果您在Python开发、应用、研究等方面有一定的经验,请点击阅读全文,或将以下链接复制在浏览器:http://t.cn/RMXAIwd 填写表单申请PyLive主讲人。经过审核认可,将会发送PyLive策划书及相关说明至您的邮箱,我们尊重知识,并且始终相信知识是最有价值 的,PyLive主讲人也将获得丰厚的补贴,欢迎大家踊跃申请。如果您认为自己暂时还欠缺相关的经验,也欢迎将本消息转发给您认识的Python高手,感 谢一路有你!
欢迎点击阅读原文,或者长按扫描以下二维码申请PyLive主讲人!

