

【版权申明】未经博主同意,不允许转载!(请尊重原创,博主保留追究权)
blog.csdn.net/javazejian/…
出自【zejian的博客】
关联文章:
java数据结构与算法之顺序表与链表设计与实现分析
java数据结构与算法之双链表设计与实现
java数据结构与算法之改良顺序表与双链表类似ArrayList和LinkedList(带Iterator迭代器与fast-fail机制)
java数据结构与算法之栈(Stack)设计与实现
java数据结构与算法之队列(Queue)设计与实现
java数据结构与算法之递归思维(让我们更通俗地理解递归)
java数据结构与算法之树基本概念及二叉树(BinaryTree)的设计与实现
树博文总算赶上这周发布了,上篇我们聊完了递归,到现在相隔算挺久了,因为树的内容确实不少,博主写起来也比较费时费脑,一篇也无法涵盖树所有内容,所以后续还会用2篇左右的博文来分析其他内容大家就持续关注吧,而本篇主要了解的知识点如下(还是蛮多的!):
树的基本概念与术语
(该定义源于Java数据结构书)树是数据元素之间具有次层关系的非线性的结构,树是由n(n≥0)个结点组成的有限集合,n=0的树是空树,n大于0的树T由以下两个条件约定构成:
- ⑴.有一个特殊的结点,称为根结点(root),它没有前驱结点只有后继结点。
⑵.除了根结点之外的其他结点分为m(0≤m≤n)个互不相交的集合T0,T1,T2,…,Tm−1,其中吧每个集合Ti也是一个树型结构,称之为子树(Subtree)。
以下是树的图形都是树的结构: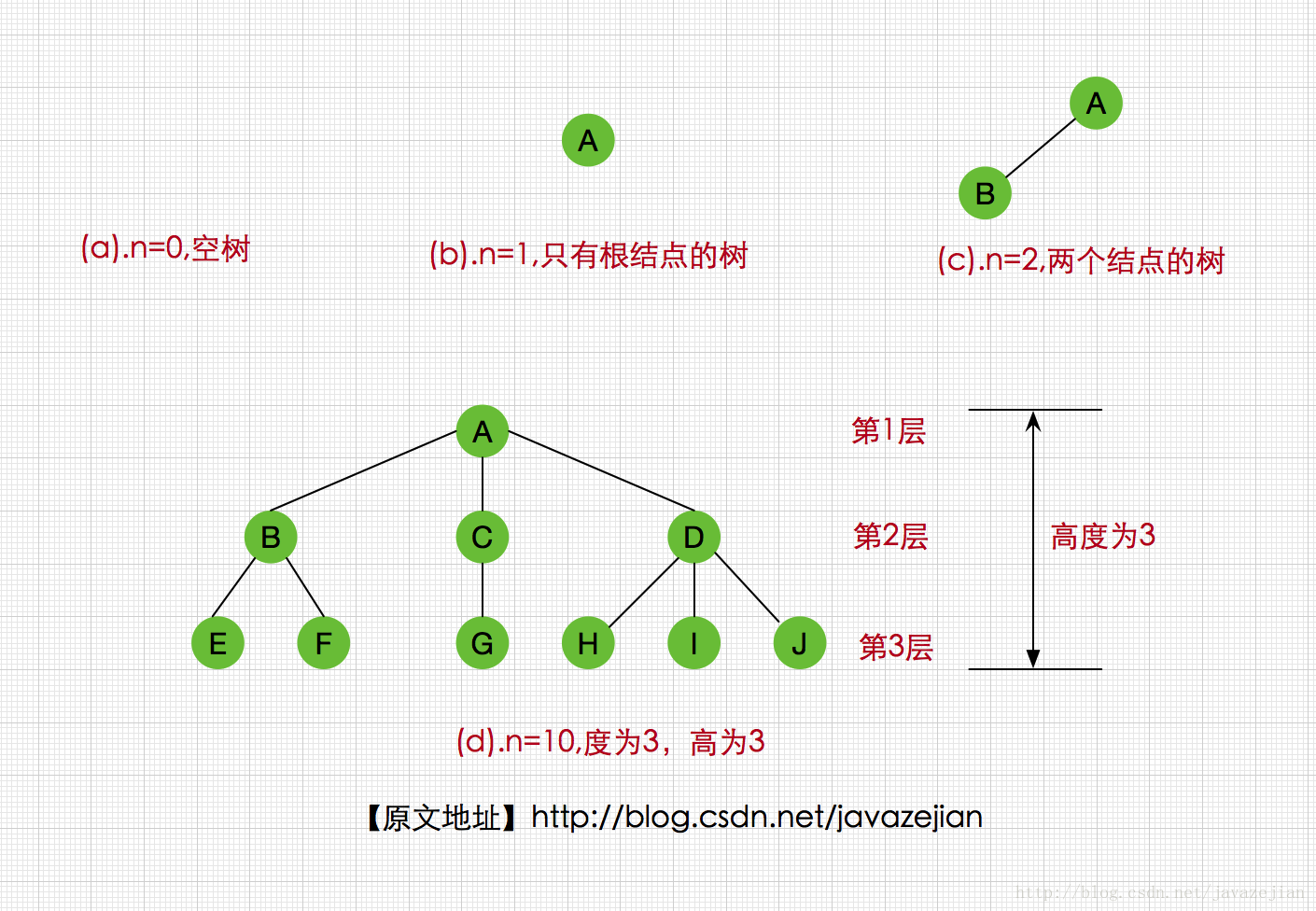
这里我们需要明白树是递归定义,这也是博主在开头强调的在递归的基础上学习树的原因,如果对于递归还不明白的,建议先看看博主的上一篇文章,毕竟在本篇内容中,递归是随处可见的。嗯,接下来我们先来认识一下树的一些常用术语,这些术语并不要求我们去死记硬背,但在看到这些术语时,我们必须有所了解或者明白其主要含义(以上图为例介绍以下的术语)。
(1)根结点: 根结点是没有双亲的结点,一棵树中最多有一个根结点(如上图的A结点)。
(2)孩子结点:一棵树中,一个结点的子树的根结点称为其孩子结点,如上图的A的孩子结点右B、C、D。
(3)父母结点:相对于孩子结点而已其前驱结点即为父母结点,如上图的B、C、D 三个结点的父母结点都为A,当然E、F结点的父母结点则是B。
(4)兄弟结点:拥有相同的父母结点的所有孩子结点叫作兄弟结点,如上图B、C、D 三个结点共同父结点为A,因此它们是兄弟结点,E、F也是兄弟结点,但是F、G就肯定不是兄弟结点了。
(5)祖先结点:如果存在一条从根结点到结点Q的路径,而且结点P出现在这条路径上,那么P就是Q的祖先结点,而结点Q也称为P的子孙结点或者后代。如上图的E的祖先结点有A和B,而E则是A和B的子孙结点。
(6)叶子结点:没有孩子结点的结点叫作叶子结点,如E、F、G、H等。
(7)结点的度:指的是结点所拥有子树的棵数。如A的度为3,F的度为0,即叶子结点的度为0,而树的度则是树中各个结点度的最大值,如图(d)树的度为3(A结点)
(8)树的层:又称结点的层,该属性反映结点处于树中的层次位置,我们约定根结点的层为1,如上图所示,A层为1,B层为2,E的层为3。
(9)树的高度(深度):是指树中结点的最大层数,图(d)的高度为3。
(10)边:边表示从父母结点到孩子结点的链接线,如上图(d)中A到B间的连线则称为边。
ok~,关于树的术语,我们就先了解到这里,接下来主要聊聊二叉树。
二叉树的定义及其基本性质
在树的数据结构中,二叉树可谓是重中之重,因此我们必须好好学习它!以下是二叉树的定义(源于java数据结构原文)
关于二叉树的定义:二叉树(Binary Tree)是n(n≥0)个结点组成的有限集合,n=0时称为空二叉树;n>0的二叉树由一个根结点和两棵互不相交、分别称为左子树和右子树的子二叉树构成,二叉树也是递归定义的,在树种定义的度、层次等术语,同样适用于二叉树。
二叉树主要有以下5种基本形态:
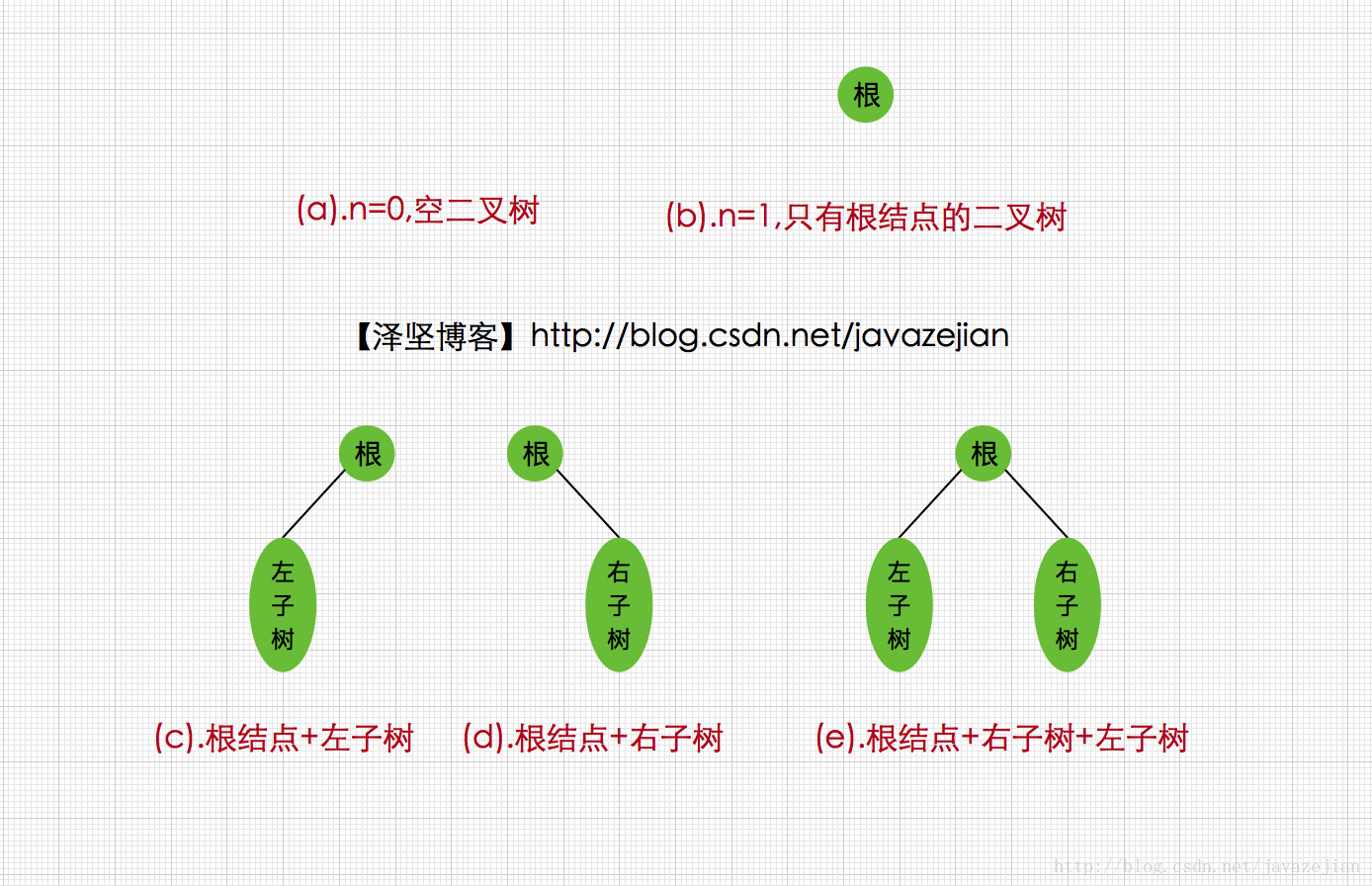
二叉树的5种形态还是比较容易理解的,比较晦涩的应该是二叉树的性质,毕竟关联到了数学层面的知识点,当然对于学习编程的同学,逻辑思维都不会太差,因此也不必担心这点,接着就来了解一下二叉树的主要特性(这里列出的博主认为需要知道和理解的特性,但不限以下特性)。
性质⑴:若根结点的层次为1,则二叉树第i层最多有2i−1(i≥1)个结点,使用数学归纳法证明过程如下:
步骤① 假设根为i=1层上唯一结点,则有2i−1=20=1成立。
步骤② 设第i-1层最多有2i−2,由于二叉树中每个结点的度最多为2,因此第i层最多有2i−1个结点也成立。
性质⑵:在高度为h的二叉树中,最多有2h−1个结点(h≥0)。
证明:由性质⑴可知,第i层最多有2i−1(i≥1)个结点,因此高度为h的二叉树结点数则有如下计算
∑i=1h2i−1=2h−1
性质⑶:满二叉树和完全二叉树
一棵高度为h的满二叉树(Full Binary Tree)是具有2h−1(h≥0)个结点的二叉树。满二叉树的最大特点是每一层次的结点数都达到最大值,我们可以对满二叉树的结点进行连续编号并约定根结点的序号为0,从根结点开始,自上而下,每层自左向右编号。如下图所示(a):
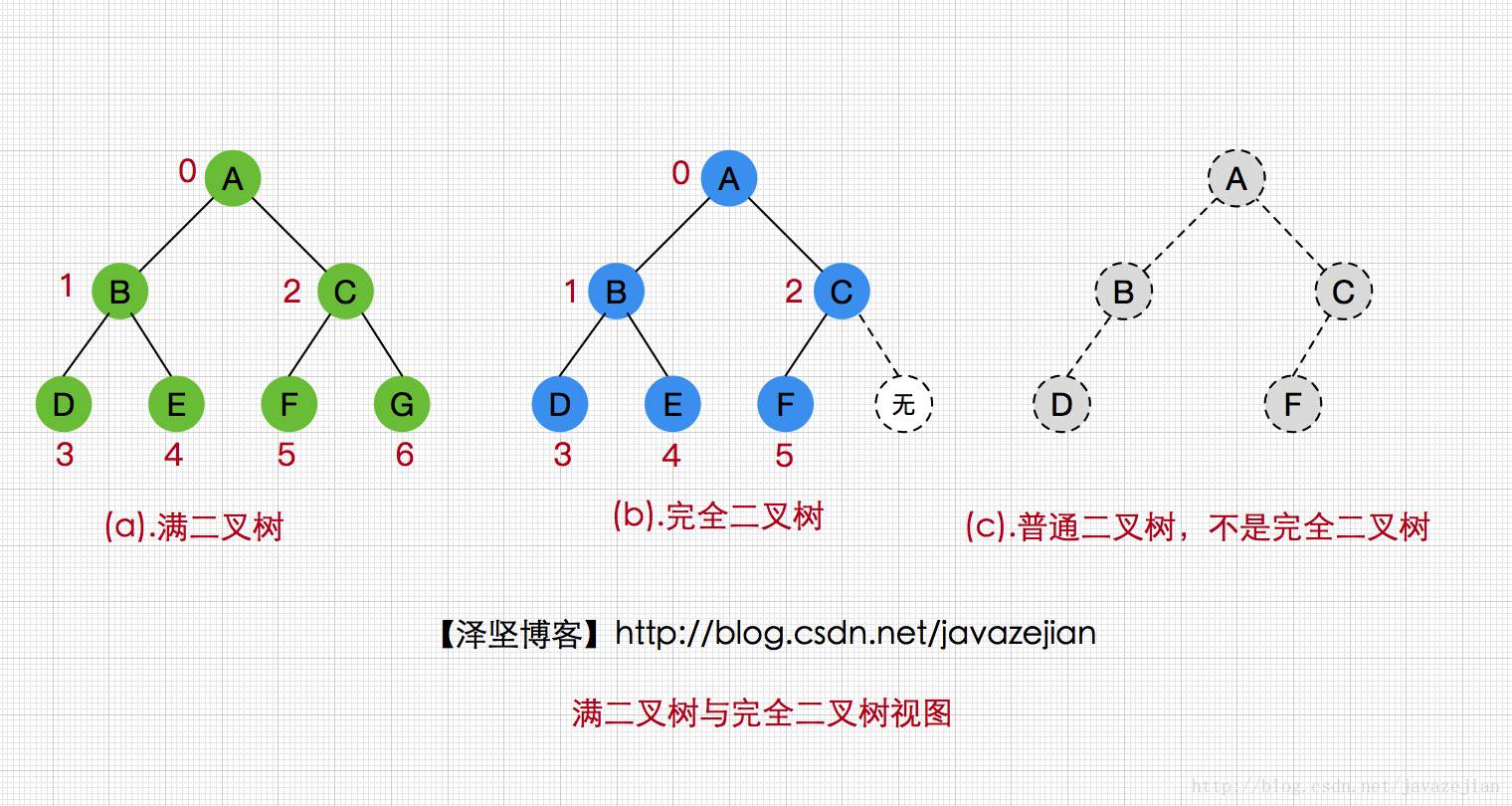
至于完全二叉树,它的每个结点都与高度为h的满二叉树中序号为0~n-1的结点一一对应。如同上图(b)所示,后面我们会通过层序遍历的算法来构造完全二叉树。
性质⑷:一棵具有n个结点的完全二叉树,对于序号为i(0≤i<n)的结点,则有如下规则
①若i=0,则i为根结点,无父母结点;若i>0,则i的父母结点序号为⌊i−12⌋(向下取整)。
②若2i+1<n,则i的左孩子结点序号为2i+1,否则i无左孩子。
③若2i+2>n,则i的右孩子结点序号为2i+2,否则i无右孩子。
如上图(b)中i=0时为根结点A,其左孩子B序号为2i+1,右孩子结点C的序号则为2i+2。注意这仅使用于完全二叉树。
嗯,关于二叉树的性质暂时了解这么多,接着看二叉树抽象数据类型及其存储结构。
二叉树抽象数据类型及其存储结构
二叉树抽象数据类型
与链表、栈、队列等抽象数据类型相似,二叉树抽象数据类型也有插入、删除、查找等操作,同时二叉树还有4种遍历算法,这个我们后面会详细分析。现在我们声明二叉树的抽象数据类型顶级接口Tree如下:T表示结点元素的类型,该类型必须实现了Comparable接口,方便比较数据。而 BinaryNode是二叉树的结点类。Tree接口声明如下:
package com.zejian.structures.Tree.BinaryTree;
/**
* Created by zejian on 2016/12/14.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public interface Tree {
/**
* 判空
* @return
*/
boolean isEmpty();
/**
* 二叉树的结点个数
* @return
*/
int size();
/**
* 返回二叉树的高度或者深度,即结点的最大层次
* @return
*/
int height();
/**
* 先根次序遍历
*/
String preOrder();
/**
* 中根次序遍历
*/
String inOrder();
/**
* 后根次序遍历
*/
String postOrder();
/**
* 层次遍历
*/
String levelOrder();
/**
* 将data 插入
* @return
*/
void insert(T data);
/**
* 删除
*/
void remove(T data);
/**
* 查找最大值
* @return
*/
T findMin();
/**
* 查找最小值
* @return
*/
T findMax();
/**
* 根据值找到结点
* @param data
* @return
*/
BinaryNode findNode(T data);
/**
* 是否包含某个值
* @param data
* @return
*/
boolean contains(T data) throws Exception;
/**
* 清空
*/
void clear();
}二叉树存储结构
关于二叉树的存储结构主要采用的是链式存储结构,至于顺序存储结构仅适用于完全二叉树或满二叉树,这个我们后面再介绍,这里我们主要还是分析二叉树的链式存储结构。二叉树的链式存储结构主要有二叉链表和三叉链表两种,下面分别说明。
二叉树的二叉链表存储结构
二叉链表结构主要由一个数据域和两个分别指向左、右孩子的结点组成,其结构如下:
BinaryNode(T data , BinaryNode left , BinaryNode right )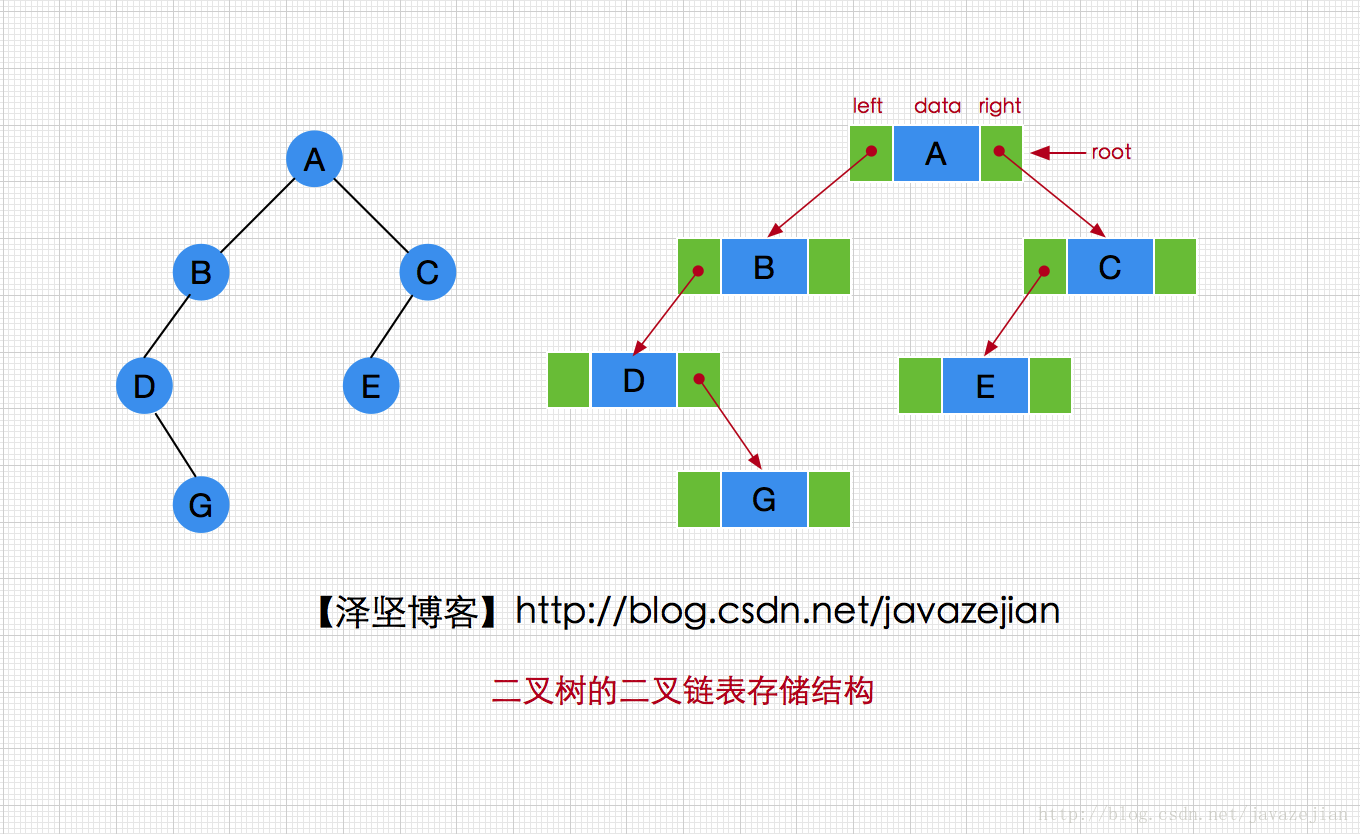
从图中可以看出,采用二叉链表存储结构,每个结点只存储了到其孩子结点的单向关系,而没有存储到父结点的关系,这样的话,每次要获取父结点时将消耗较多的时间,因为需要从root根结点开始查找,花费的时间是遍历部分二叉树的时间,而且与该结点的位置有关。为了更高效的获取父结点,三叉链表存储结构孕育而生了。
二叉树的三叉链表存储结构
三叉链表主要是在二叉链表的基础上多添加了一个指向父结点的域,这样我们就存储了父结点与孩子结点的双向关系,当然这样也增加了一定的空开销其结点结构如下:
ThreeNode(T data ,ThreeNode parent,ThreeNode left,ThreeNode right)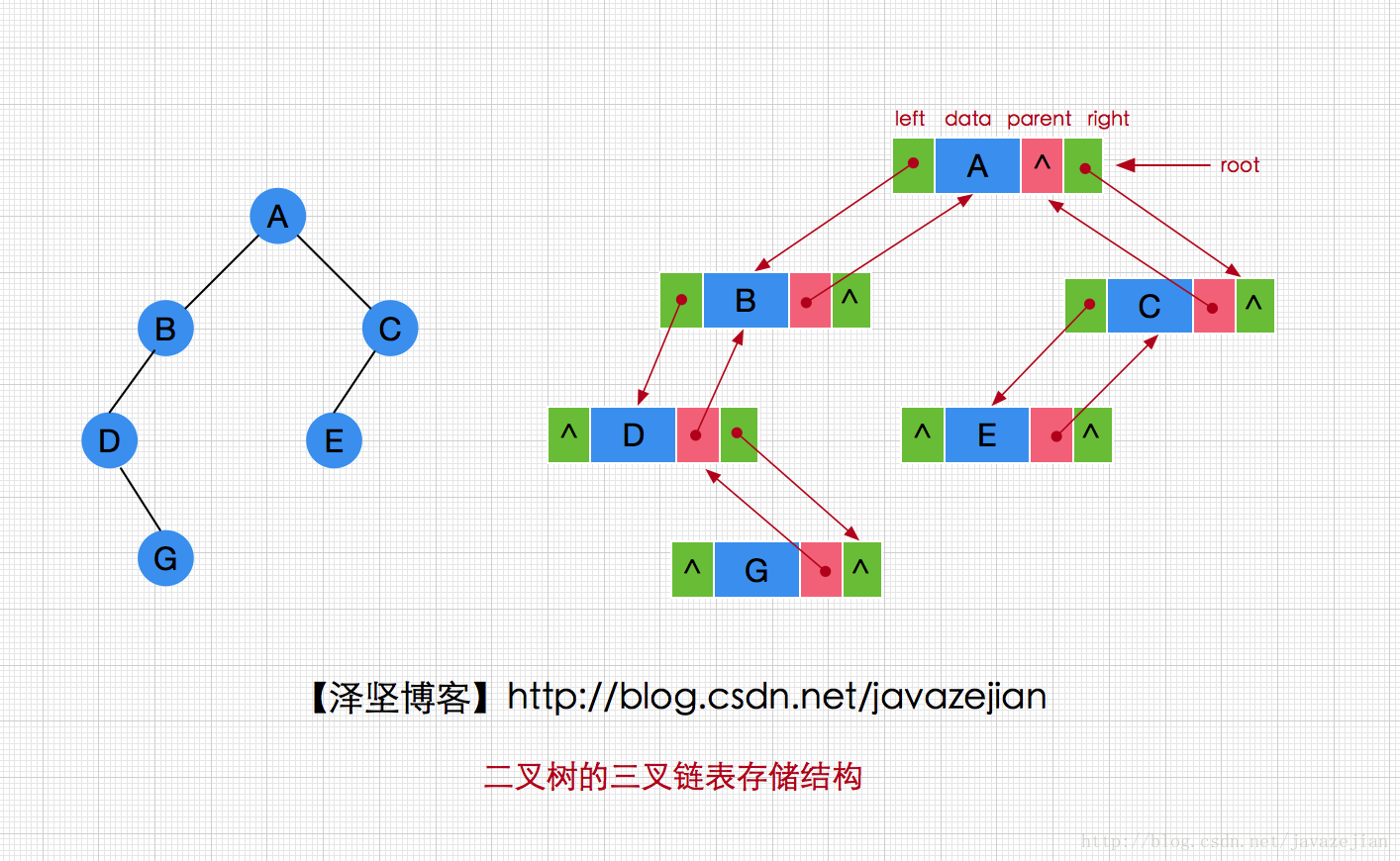
二叉树的静态二/三叉链表存储结构(了解即可)
除了以上两种结构,其实我们也可采用一个结点数组存储所有二叉树的所有结点,这种结构称为静态二/三叉链表,在这样的结构中,每个结点存储其(父结点)左、右孩子下标,通过下标表示结点间的关系,-1表示无此结点。结构如下:
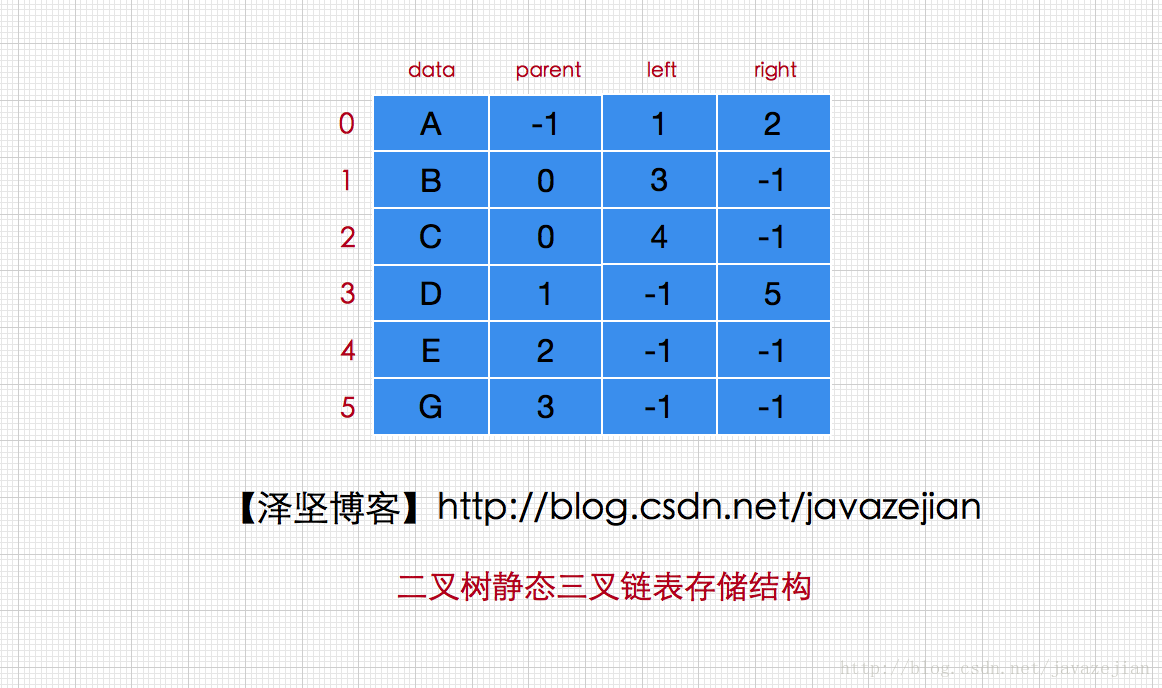
ok~,关于二叉树存储结构就分析到这,下面我们以二叉链表存储结构为例实现二叉树。
二叉树的设计与实现
在开始之前,博主想再聊聊二叉树的递归,毕竟下面的内容递归几乎随处可见,理解递归是掌握下面内容的先行课程。在上篇文章中,我们一再强调递归是一种化复杂问题为简单同类问题的思维,而这种思维在程序中的体现则是递归算法,那么树为什么可以用递归定义呢?我们先来看看一个图:
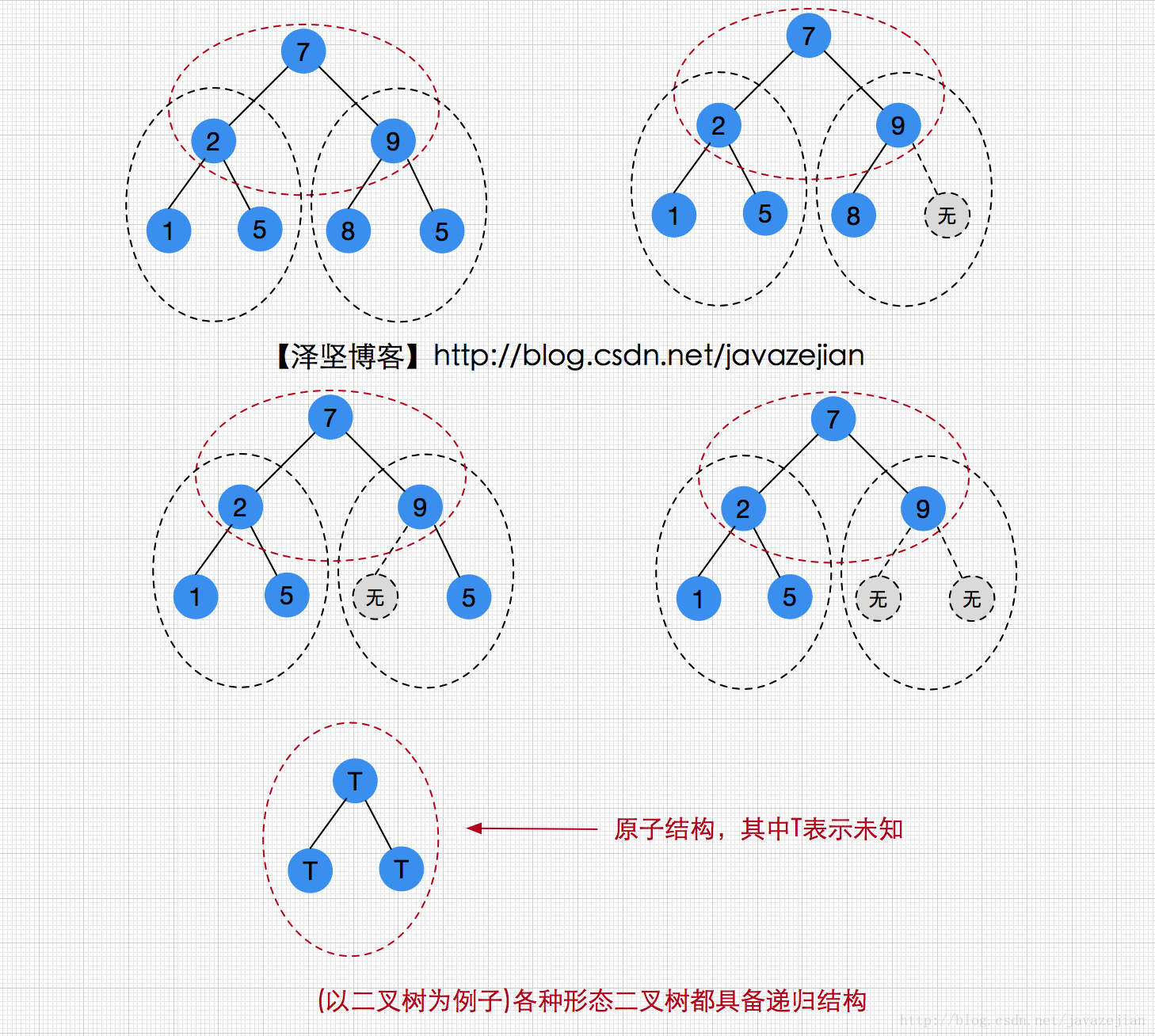
从图中我们可以看到,无论的那种递归结构都具备递归的结构,它们的一致的原子结构,这也就是为什么树可以使用递归定义的原因,递归结构与递归思维都体现得淋漓尽致,即使是一个十分复杂的树,我们也可以简化为原子的结构的求解过程,毕竟它们本质上是同类问题。到此,相信大家对递归的思维方式有更进一步的理解了吧?如果还是不理解,请移步上一篇文章(java数据结构与算法之递归思维),再回忆一遍,思考思考。ok~,下面开始是二叉树的设计与实现内容。
为了使二叉树的实现变得更有具体意义,我们将实现一种叫二叉查找树的数据结构,二叉查找树的特性是,对于树种的每个结点T(T可能是父结点),它的左子树中所有项的值小T中的值,而它的右子树中所有项的值都大于T中的值。这意味着该树所有的元素可以用某种规则进行排序(取决于Comparable接口的实现)。二叉查找树使用二叉链表存储结构实现,其结点BinaryNode<T>声明如下:
package com.zejian.structures.Tree.BinaryTree;
import java.io.Serializable;
/**
* Created by zejian on 2016/12/14.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* 二叉树结点
*/
public class BinaryNode implements Serializable{
private static final long serialVersionUID = -6477238039299912313L;
public BinaryNode left;//左结点
public BinaryNode right;//右结点
public T data;
public BinaryNode(T data,BinaryNode left,BinaryNode right){
this.data=data;
this.left=left;
this.right=right;
}
public BinaryNode(T data){
this(data,null,null);
}
/**
* 判断是否为叶子结点
* @return
*/
public boolean isLeaf(){
return this.left==null&&this.right==null;
}
}二叉查找树BinarySearchTree类架构定义如下:
package com.zejian.structures.Tree.BinaryTree;
/**
* Created by zejian on 2016/12/19.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public class BinarySearchTree implements Tree {
//根结点
protected BinaryNode root;
public BinarySearchTree(){
root =null;
}
@Override
public boolean isEmpty() {
return false;
}
@Override
public int size() {
return 0;
}
@Override
public int height() {
return 0;
}
@Override
public String preOrder() {
return null;
}
@Override
public String inOrder() {
return null;
}
@Override
public String postOrder() {
return null;
}
@Override
public String levelOrder() {
return null;
}
@Override
public void insert(T data) {
}
@Override
public void remove(T data) {
}
@Override
public T findMin() {
return null;
}
@Override
public T findMax() {
return null;
}
@Override
public BinaryNode findNode(T data) {
return null;
}
@Override
public boolean contains(T data) throws Exception {
return false;
}
@Override
public void clear() {
}
}
大概了解BinarySearchTree类的基本架构后,我们接着看看如何实现这些基本方法。
二叉查找树基本操作的设计与实现
二叉查找树的插入算法的设计与实现(递归)
事实上对于二叉查找树的插入操作的设计是比较简单,我们只要利用二叉查找树的特性(即对每个父结点,它的左子树中所有项的值小T中的值,而它的右子树中所有项的值都大于T中的值),找到只对应的插入位置即可,假如现在我们要插入data=4的结点,那么可以这样操作,沿着树查找(比较结点的数据与data的大小从而决定往左/右子树继续前行),如果找到data(4),则什么也不做,否则将data插入到遍历的路径上的最后一个点,如下图所示:
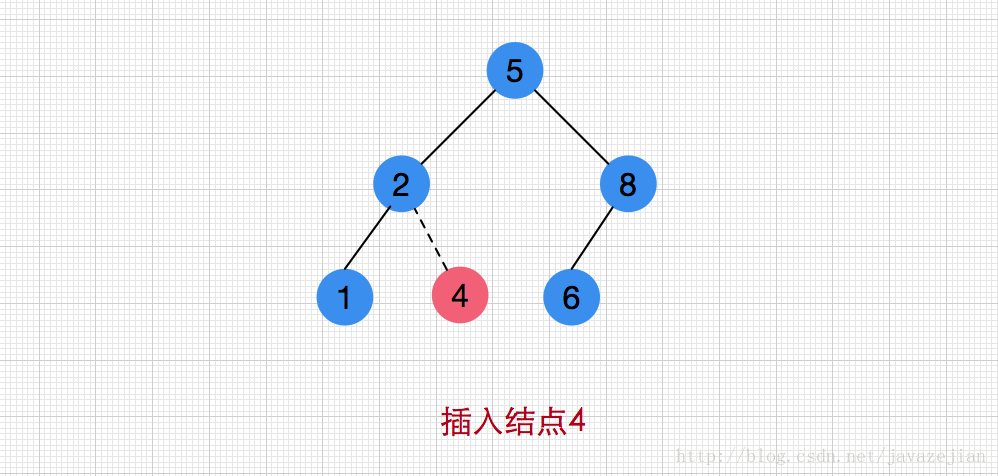
插入算法程序设计如下:
@Override
public void insert(T data) {
if (data==null)
throw new RuntimeException("data can\'Comparable be null !");
//插入操作
root=insert(data,root);
}
/**
* 插入操作,递归实现
* @param data
* @param p
* @return
*/
private BinaryNode insert(T data,BinaryNode p){
if(p==null){
p=new BinaryNode<>(data,null,null);
}
//比较插入结点的值,决定向左子树还是右子树搜索
int compareResult=data.compareTo(p.data);
if (compareResult<0){//左
p.left=insert(data,p.left);
}else if(compareResult>0){//右
p.right=insert(data,p.right);
}else {
;//已有元素就没必要重复插入了
}
return p;
}二叉查找树的删除算法的设计与实现(递归与非递归)
对于二叉树来说,删除是一种比较麻烦的操作,因为涉及到了多种情况(设要删除的结点为q,其父母结点为p):
① 如果要删除的结点q恰好是叶子结点,那么它可以立即被删除
② 如果要删除的结点q拥有一个孩子结点,则应该调整要被删除的父结点(p.left 或 p.right)指向被删除结点的孩子结点(q.left 或 q.right)
- ③如果要删除的结点q拥有两个孩子结点,则删除策略是用q的右子树的最小的数据替代要被删除结点的数据,并递归删除用于替换的结点(此时该结点已为空),此时二叉查找树的结构并不会被打乱,其特性仍旧生效。采用这样策略的主要原因是右子树的最小结点的数据替换要被删除的结点后可以满足维持二叉查找树的结构和特性,又因为右子树最小结点不可能有左孩子,删除起来也相对简单些。
为了更新清晰描述这个过程,我们可以借助下图来理解:
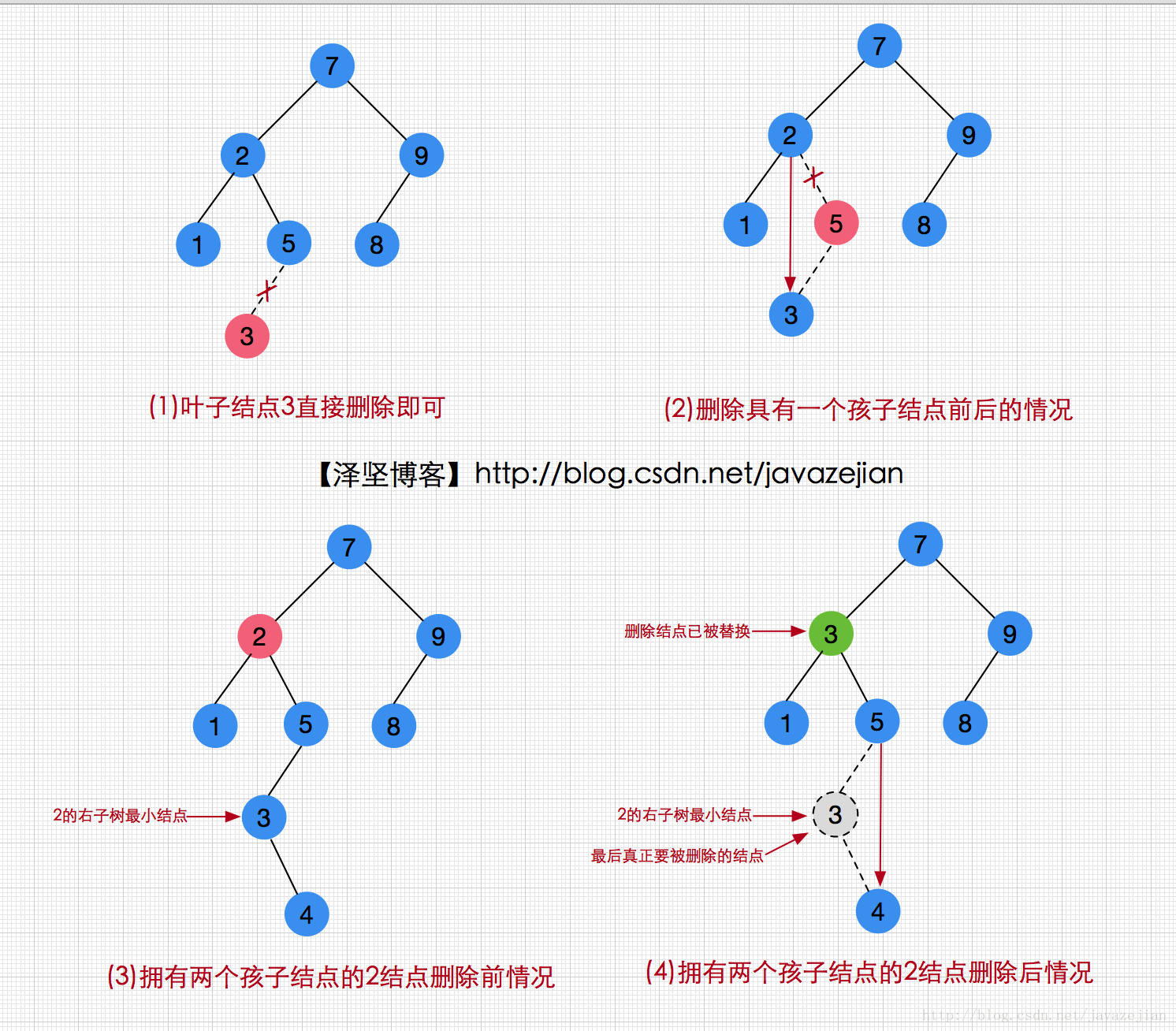
下面是删除操作的程序实现,也是递归实现,其中的findMin方法是查找二叉查找树中的最小值,后面我们会分析这个方法,其代码注释也比较清晰:
@Override
public void remove(T data) {
if(data==null)
throw new RuntimeException("data can\'Comparable be null !");
//删除结点
root=remove(data,root);
}
/**
* 分3种情况
* 1.删除叶子结点(也就是没有孩子结点)
* 2.删除拥有一个孩子结点的结点(可能是左孩子也可能是右孩子)
* 3.删除拥有两个孩子结点的结点
* @param data
* @param p
* @return
*/
private BinaryNode remove(T data,BinaryNode p){
//没有找到要删除的元素,递归结束
if (p==null){
return p;
}
int compareResult=data.compareTo(p.data);
if (compareResult<0){//左边查找删除结点
p.left=remove(data,p.left);
}else if (compareResult>0) {
p.right=remove(data,p.right);
}else if (p.left!=null&&p.right!=null){//已找到结点并判断是否有两个子结点(情况3)
//中继替换,找到右子树中最小的元素并替换需要删除的元素值
p.data = findMin( p.right ).data;
//移除用于替换的结点
p.right = remove( p.data, p.right );
}else {
//拥有一个孩子结点的结点和叶子结点的情况
p=(p.left!=null)? p.left : p.right;
}
return p;//返回该结点
}除了递归实现删除操作,我们也可以使用非递归方式来实现删除操作,代码如下:
/**
* 非递归删除
* @param data
*/
public T removeUnrecure(T data){
if (data==null){
throw new RuntimeException("data can\'Comparable be null !");
}
//从根结点开始查找
BinaryNode current =this.root;
//记录父结点
BinaryNode parent=this.root;
//判断左右孩子的flag
boolean isLeft=true;
//找到要删除的结点
while (data.compareTo(current.data)!=0){
//更新父结点记录
parent=current;
int result=data.compareTo(current.data);
if(result<0){//从左子树查找
isLeft=true;
current=current.left;
}else if(result>0){//从右子树查找
isLeft=false;
}
//如果没有找到,返回null
if (current==null){
return null;
}
}
//----------到这里说明已找到要删除的结点
//删除的是叶子结点
if (current.left==null&¤t.right==null){
if (current==this.root){
this.root=null;
} else if(isLeft){
parent.left=null;
}else {
parent.right=null;
}
}
//删除带有一个孩子结点的结点,当current的right不为null
else if (current.left==null){
if (current==this.root){
this.root=current.right;
}else if(isLeft){//current为parent的左孩子
parent.left=current.right;
}else {//current为parent的右孩子
parent.right=current.right;
}
}
//删除带有一个孩子结点的结点,当current的left不为null
else if(current.right==null){
if (current==this.root){
this.root=current.left;
}else if (isLeft){//current为parent的左孩子
parent.left=current.left;
}else {//current为parent的右孩子
parent.right=current.left;
}
}
//删除带有两个孩子结点的结点
else {
//找到当前要删除结点current的右子树中的最小值元素
BinaryNode successor= findSuccessor(current);
if(current == root) {
this.root = successor;
} else if(isLeft) {
parent.left = successor;
} else{
parent.right = successor;
}
//把当前要删除的结点的左孩子赋值给successor
successor.left = current.left;
}
return current.data;
}
/**
* 查找中继结点--右子树最小值结点
* @param delNode 要删除的结点
* @return
*/
public BinaryNode findSuccessor(BinaryNode delNode) {
BinaryNode successor = delNode;
BinaryNode successorParent = delNode;
BinaryNode current = delNode.right;
//不断查找左结点,直到为空,则successor为最小值结点
while(current != null) {
successorParent = successor;
successor = current;
current = current.left;
}
//如果要删除结点的右孩子与successor不相等,则执行如下操作(如果相当,则说明删除结点)
if(successor != delNode.right) {
successorParent.left = successor.right;
//把中继结点的右孩子指向当前要删除结点的右孩子
successor.right = delNode.right;
}
return successor;
}这里主要说明一下删除时有两个结点的情况,这时我们需要借助findSuccessor方法找到要被删除结点右子树的最小值,并用于替换要被删除结点。对于if(successor != delNode.right)代码被执行的情况如下图
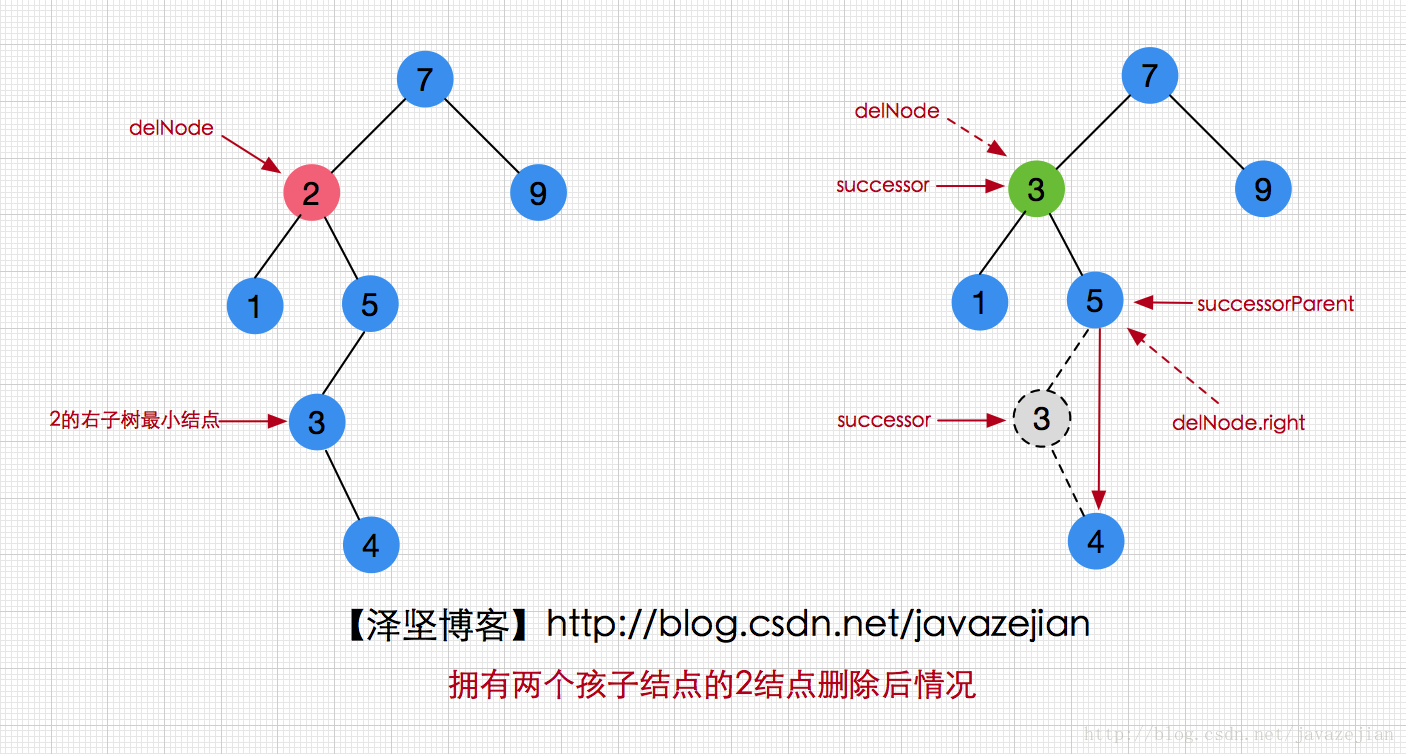
对于if(successor != delNode.right)代码不成立的情况如下图:
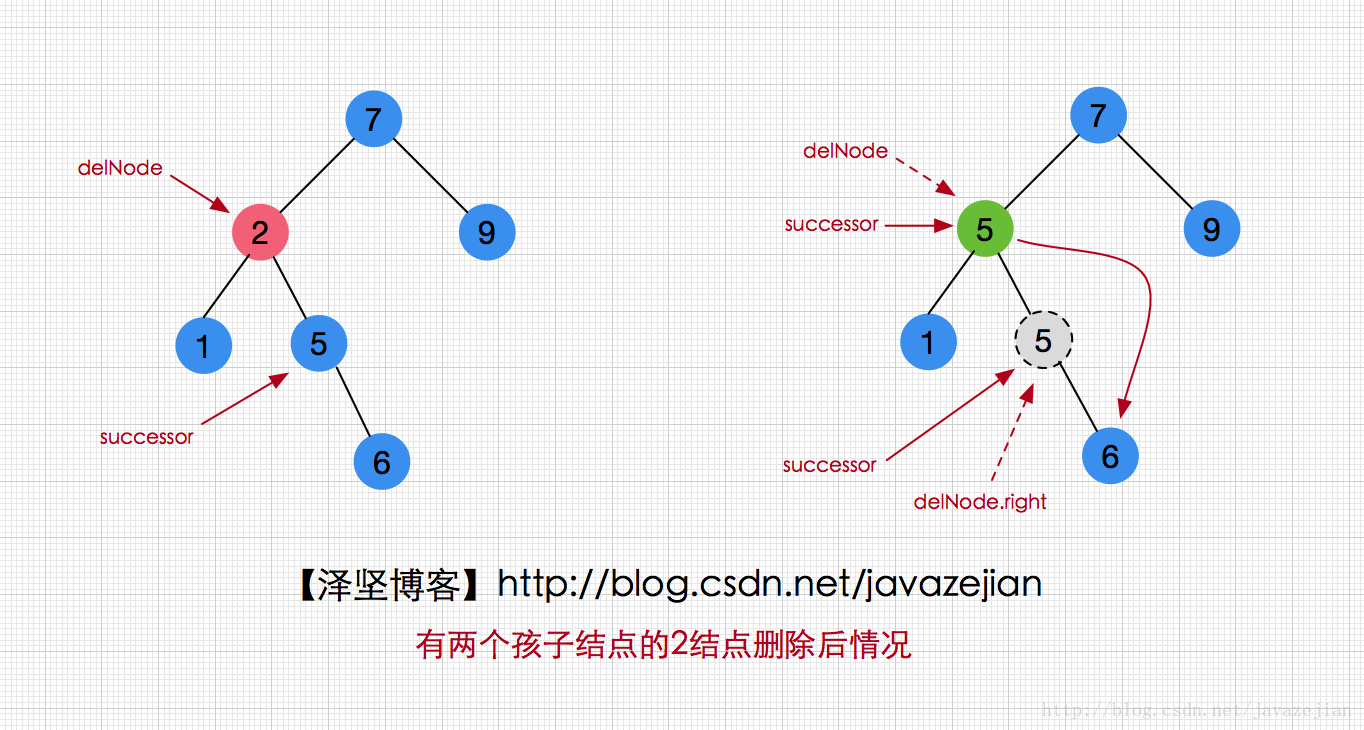
嗯,以上两幅图辅助大家理解代码,其他就不多分析了,注释写很明白了。
二叉查找树的最大和最小值的查找算法与实现(递归)
二叉查找树中的findMin和findMax方法分别返回的是树种的最小值和最大值,对于findMin(),则需要从根结点开始并且只要有左孩子就向左进行即可,其终止点即为最小值的元素;而对于findMax(),也需要从根结点开始并且只要有右孩子就向右进行即可,终止点即为值最大的元素。同样的我们使用递归实现它们,代码如下:
@Override
public T findMin() {
if(isEmpty())
throw new EmptyTreeException("BinarySearchTree is empty!");
return findMin(root).data;
}
@Override
public T findMax() {
if(isEmpty())
throw new EmptyTreeException("BinarySearchTree is empty!");
return findMax(root).data;
}
/**
* 查找最小值结点
* @param p
* @return
*/
private BinaryNode findMin(BinaryNode p){
if (p==null)//结束条件
return null;
else if (p.left==null)//如果没有左结点,那么t就是最小的
return p;
return findMin(p.left);
}
/**
* 查找最大值结点
* @param p
* @return
*/
private BinaryNode findMax(BinaryNode p){
if (p==null)//结束条件
return null;
else if (p.right==null)
return p;
return findMax(p.right);
}
二叉查找树的深度(height)和大小(size)计算的设计与实现(递归)
根据前面的术语,可知树的深度即为最大层的结点所在层次,而大小就是树的结点数,关于深度,我们只需要从根结点开始寻找,然后计算出左子树的深度和右子树的深度,接着比较左子树与右子树的深度,最后返回深度大的即可。深度求解过程图示以及代码实现如下:
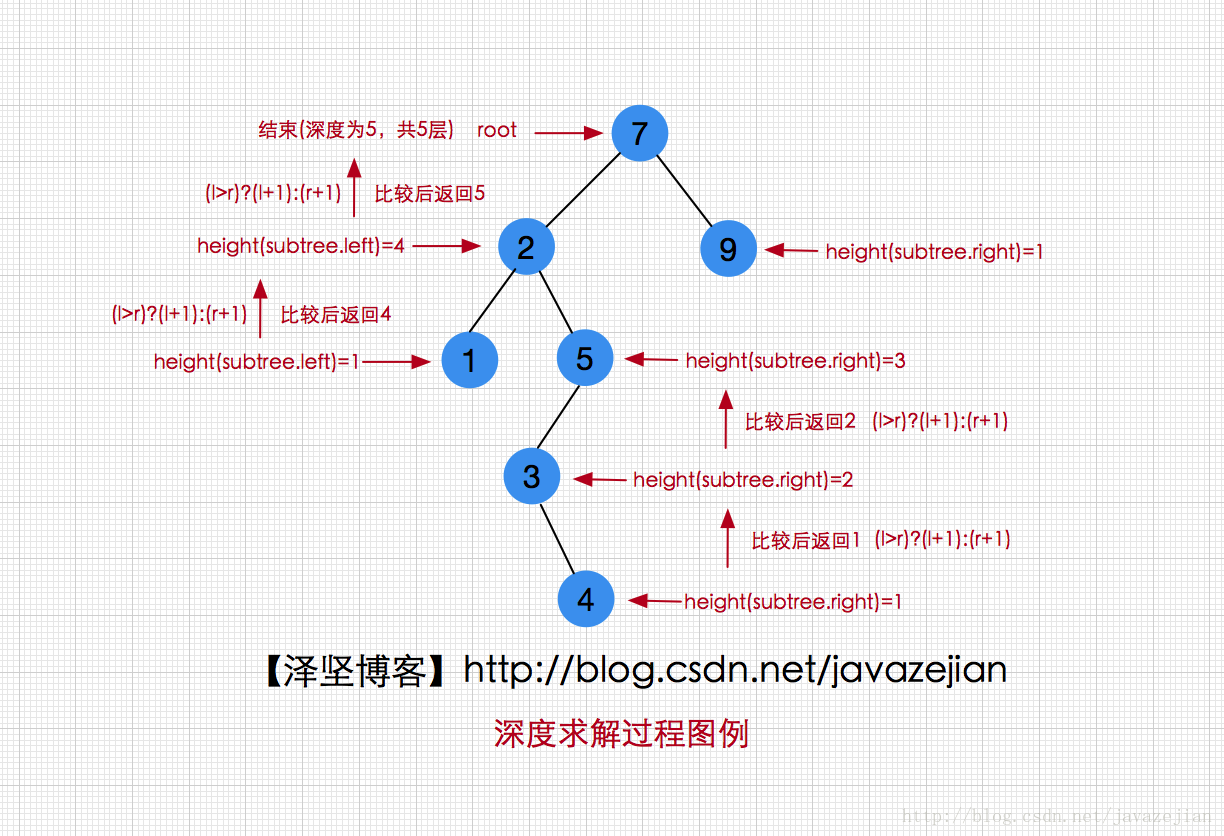
/**
* 计算深度
* @return
*/
@Override
public int height() {
return height(root);
}
/**
* 递归实现
* @param subtree
* @return
*/
private int height(BinaryNode subtree){
if (subtree==null){
return 0;
}else {
int l=height(subtree.left);
int r=height(subtree.right);
return (l>r) ? (l+1):(r+1);//返回并加上当前层
}
} 接着在看看求解二叉树大小(size)的算法该如何实现,实际上,size的求解跟上篇文章分析递归时,汉诺塔问题求解过程十分相似(其实不止是大小求解过程,二叉查找树的所有使用递归的操作都是这样的思想),我们先看看下图:
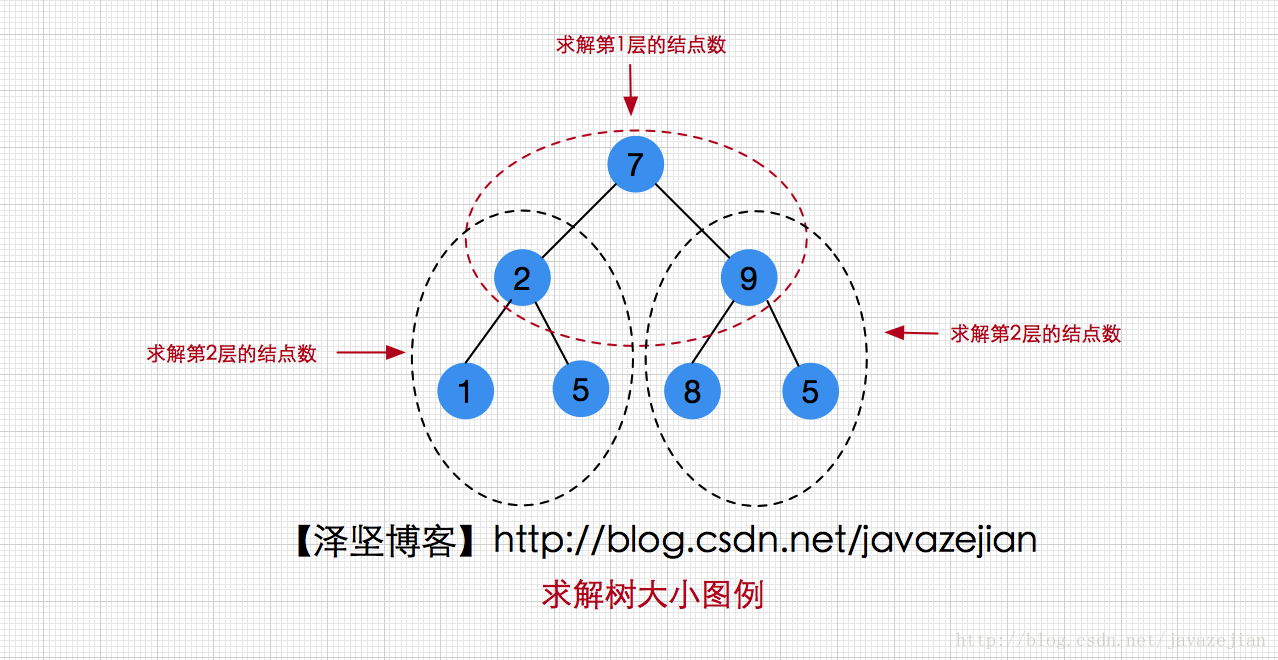
对比一下,是不是很相似?
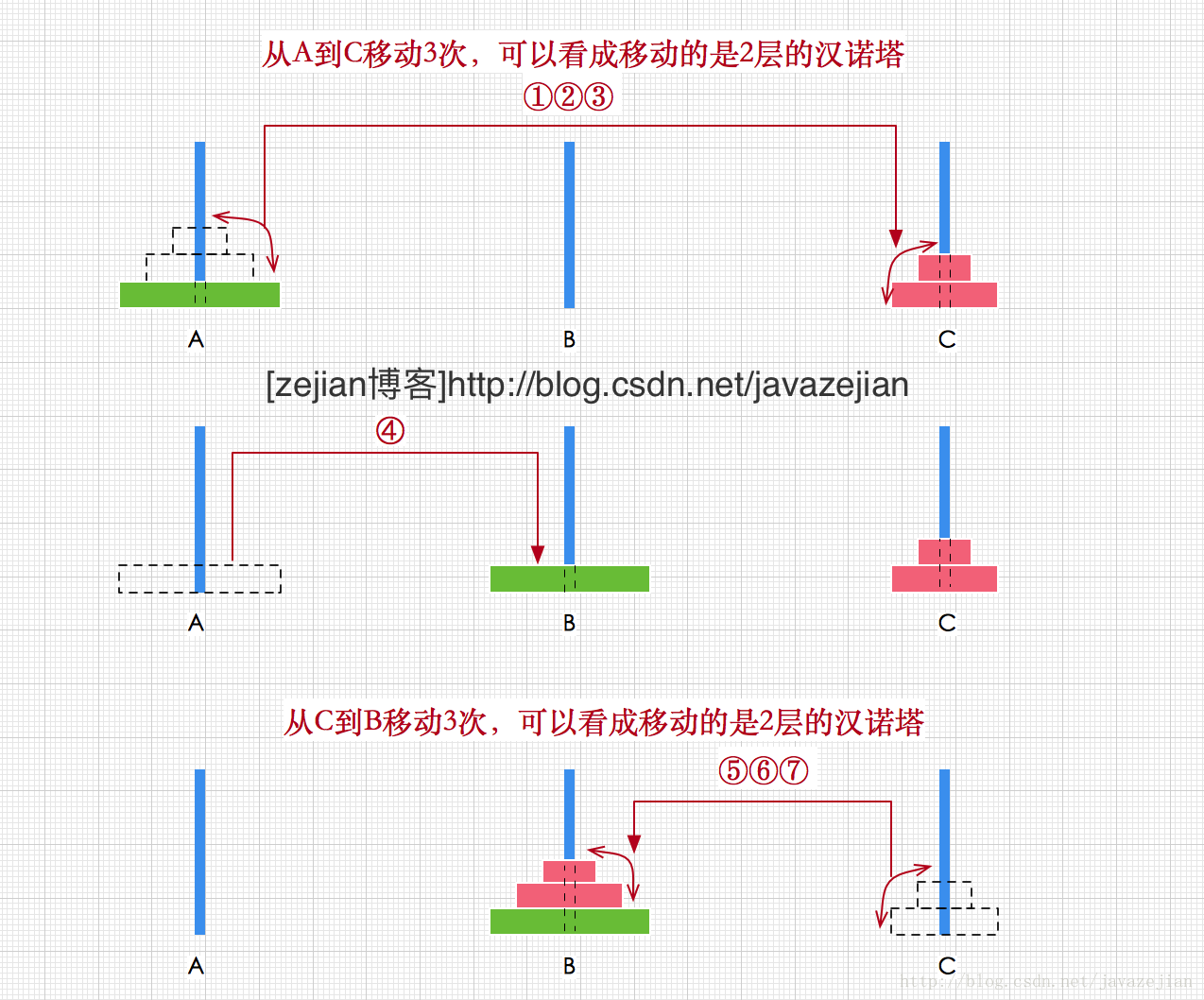
很显然树也是一个递归结构,而且我们发现,要从第一层开始计算,求出整棵树的结点数,只要先求出第2层的结点数(左子树和右子树),然后加上父结点1就是整棵树的结点数了,是不是跟汉诺塔求解很相似呢?只不过这里是反向求解罢了,因此我们的算法程序可以这样设计:
/**
* 计算大小
* @return
*/
@Override
public int size() {
return size(root);
}
/**
* 递归实现:定义根节点root后,再用subtree实现递归
* @param subtree
* @return
*/
private int size(BinaryNode subtree){
if (subtree == null)
return 0;
else
{
//对比汉诺塔:H(n)=H(n-1) + 1 + H(n-1)
return size(subtree.left) + 1 + size(subtree.right);
}
}二叉查找树的遍历算法
通过前面分析,我们已熟悉了二叉树的一些主要操作方法,那么现在接着来了解二叉查找树的遍历算法,二叉树的遍历规则主要有四种,先根次序遍历,中根次序遍历,后根次序遍历以及层次遍历,下面我们将一一分析。
递归与非递归的先根次序遍历算法的实现
先根次序遍历算法,其访问规则是先遍历根结点,再遍历左子树,最后遍历右子树。如下图先根遍历的次序为ABEFC
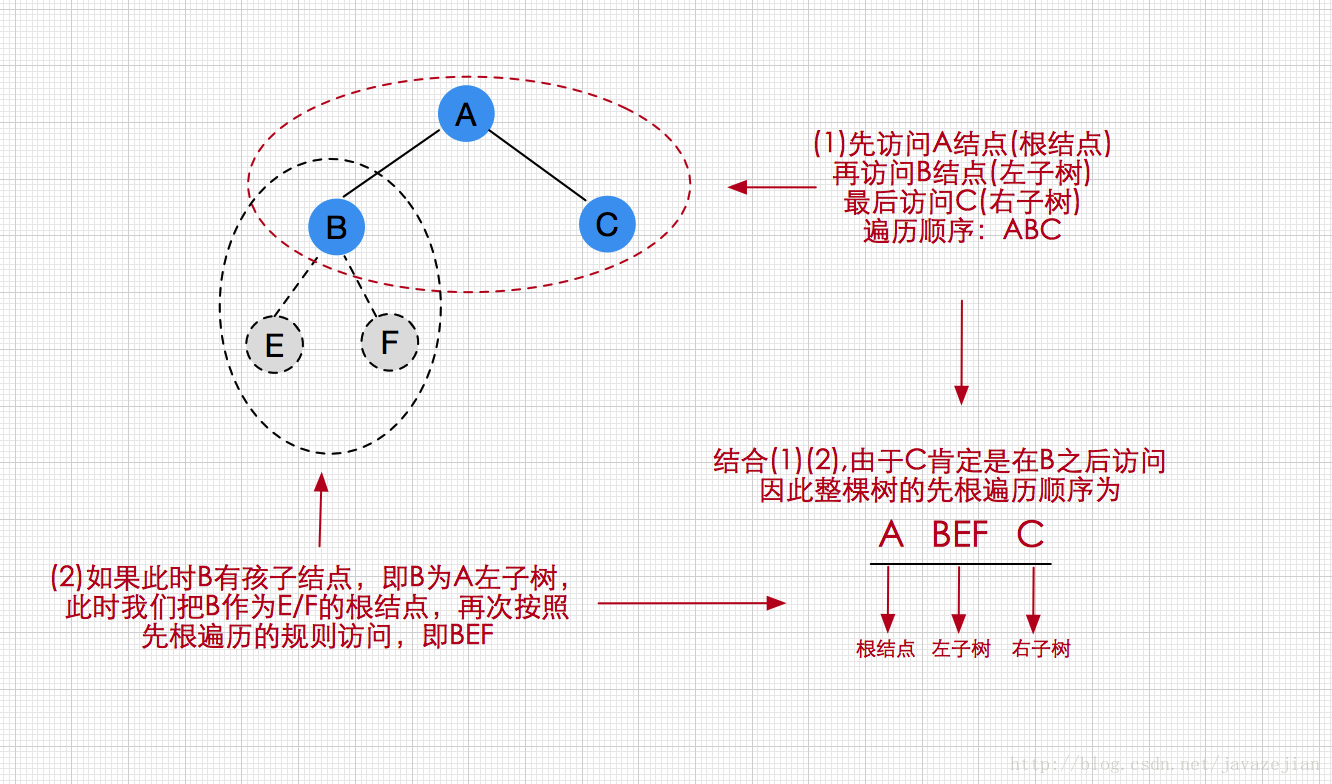
从图可知,先根遍历每次总是先访问根结点,再访问左子树,最后访问右子树,而对于一个复杂的树,我们可以先将其简化为三个结点的树(两个结点或者一个结点则空白填补,最后去掉即可),然后解出该子树的顺序,再求解其上层的子树,如上图的步骤(1)(2)的过程,我们可先求出以B为根的三个结点的子树,先根遍历次序为BEF,然后再求出以A为根结点的树,然后将已解出的(2)作为左子树整体插入到A(BEF)C的序列中即可,这样整棵树的遍历顺序求出来了,事实上这里我们又再次运用递归思维(复杂化简单求解问题),因此在程序中也可以使用递归算法实现先根次序遍历算法如下:
@Override
public String preOrder() {
String sb=preOrder(root);
if(sb.length()>0){
//去掉尾部","号
sb=sb.substring(0,sb.length()-1);
}
return sb;
}
/**
* 先根遍历
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* @param subtree
* @return
*/
private String preOrder(BinaryNode subtree){
StringBuffer sb=new StringBuffer();
if (subtree!=null) {//递归结束条件
//先访问根结点
sb.append(subtree.data+",");
//遍历左子树
sb.append(preOrder(subtree.left));
//遍历右子树
sb.append(preOrder(subtree.right));
}
return sb.toString();
}代码比较简单,很容易明白,当然我们也可以使用非递归的方式实现,不过得借助容器栈实现(这里利用LinkedStack)。我们这里来分析一下为什么需要借助栈,如下图:
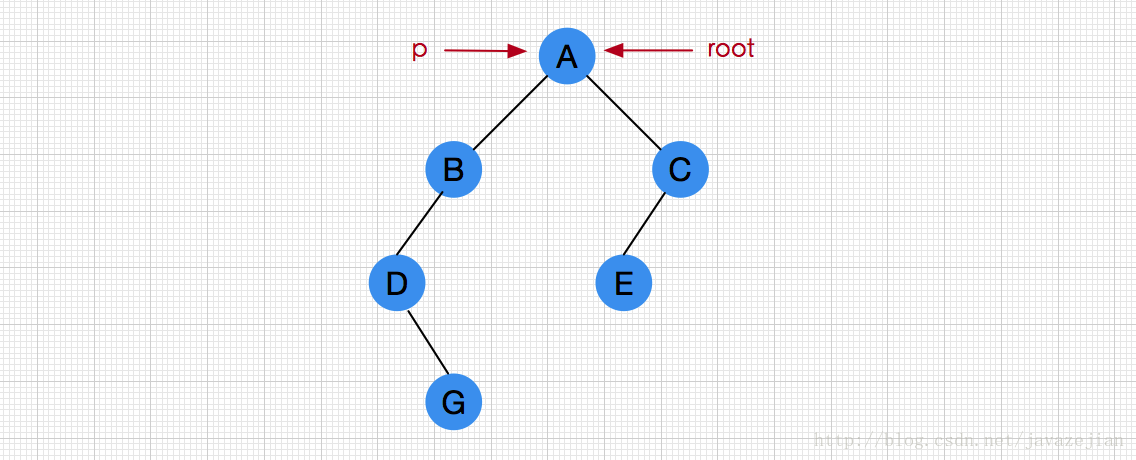
p结点从根结点A开始,沿左子树开始遍历B、D,再沿D的右子树访问G结点,这样就完成了遍历A的左子树的工作,此时需要返回到根结点A,然后继续遍历A的右子树,但G结点并没有到达A的直接指向,因此可见二叉链表本身并不能很好支持非递归的遍历二叉树的操作,所以我们需要一个容器来记录这个访问路径,以便能顺利返回A点继续遍历其右子树,由于所有刚才所有经过的结点次序(ABDG)与返回结点的次序(GDBA)正好相反,如果我们能保存路径上的所经过的结点,只要按照相反次序就应该能找到返回的路径,也就是说这个容器的特点必须是后进先出的–栈,这就是选择栈的原因。根据这一思路,我们将二叉查找树的先根次序非递归遍历算法描述如下(如下图所示,p从根结点开始,设置辅助容器linkedStack,当p非空或者栈非空时,循环执行下述操作,直到栈和二叉查找树为空):
①若p非空,表示恰好到达p结点,访问p结点,再将p入栈,进入p的左子树。
②进入p的左子树后,若p为空但栈不为空,则表示已完整走完一条路径,则需返回寻找另一条路径,而此时返回的结点恰恰是刚才经过的最后一个结点,它已保存在栈顶,因此出栈该结点,赋值给p,再遍历p的右子树。
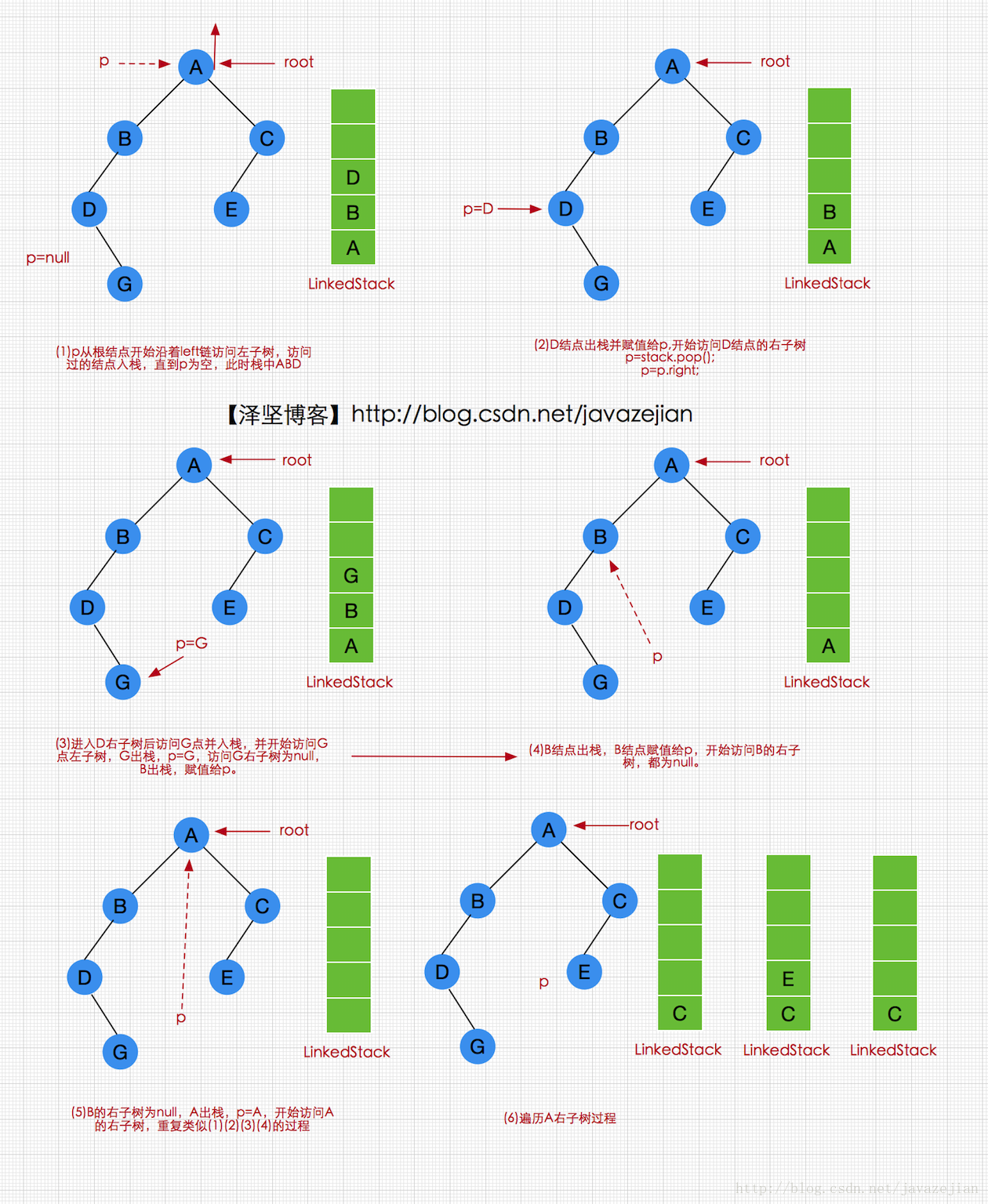
代码实现如下:
/**
* 非递归的先根遍历
* @return
*/
public String preOrderTraverse(){
StringBuffer sb=new StringBuffer();
//构建用于存放结点的栈
LinkedStack> stack=new LinkedStack<>();
BinaryNode p=this.root;
while (p!=null||!stack.isEmpty()){
if (p!=null){
//访问该结点
sb.append(p.data+",");
//将已访问过的结点入栈
stack.push(p);
//继续访问其左孩子,直到p为null
p=p.left;
}else { //若p=null 栈不为空,则说明已沿左子树访问完一条路径, 从栈中弹出栈顶结点,并访问其右孩子
p=stack.pop();//获取已访问过的结点记录
p=p.right;
}
}
//去掉最后一个逗号
if(sb.length()>0){
return sb.toString().substring(0,sb.length()-1);
}else {
return sb.toString();
}
}递归与非递归的中根次序遍历算法的实现
中根次序遍历的算法规则是,先遍历左子树,再遍历根结点,最后遍历右子树。过程如下图(同样利用的是递归思维)
图的原理跟先根次序的的原理是一样的,唯一不同的是根结点的遍历顺序罢了,下面给出递归算法的实现代码:
@Override
public String inOrder() {
String sb=inOrder(root);
if(sb.length()>0){
//去掉尾部","号
sb=sb.substring(0,sb.length()-1);
}
return sb;
}
/**
* 中根遍历
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* @return
*/
public String inOrder(BinaryNode subtree) {
StringBuffer sb=new StringBuffer();
if (subtree!=null) {//递归结束条件
//先遍历左子树
sb.append(inOrder(subtree.left));
//再遍历根结点
sb.append(subtree.data+",");
//最后遍历右子树
sb.append(inOrder(subtree.right));
}
return sb.toString();
} 同样的,我们也可以借助栈容器使用非递归的遍历算法实现中根遍历,中根遍历算法描述如下(p从根结点开始,设置辅助容器linkedStack,当p非空或者栈非空时,循环执行下述操作,直到栈和二叉查找树为空):
① 若p不为空,表示刚刚到达p结点,由于是中根遍历,不能先访问根结点,直接将p入栈,继续进入p左子树,直到p为null。
②若p为空但栈不为空,表示已走完一条路径,则需要返回寻找另一条路径,而返回结点就是刚才经过的最后一个结点,它已保存在栈顶,所以出栈一个结点,使p指向它,并访问该结点,再进入p的右子树。
程序实现如下:
/**
* 非递归的中根遍历
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* @return
*/
public String inOrderTraverse(){
StringBuffer sb=new StringBuffer();
//构建用于存放结点的栈
LinkedStack> stack=new LinkedStack<>();
BinaryNode p=this.root;
while (p!=null||!stack.isEmpty()){
while (p!=null){//把左孩子都入栈,至到左孩子为null
stack.push(p);
p=p.left;
}
//如果栈不为空,因为前面左孩子已全部入栈
if(!stack.isEmpty()){
p=stack.pop();
//访问p结点
sb.append(p.data+",");
//访问p结点的右孩子
p=p.right;
}
}
if(sb.length()>0){
return sb.toString().substring(0,sb.length()-1);
}else {
return sb.toString();
}
}递归与非递归的后根次序遍历算法的实现
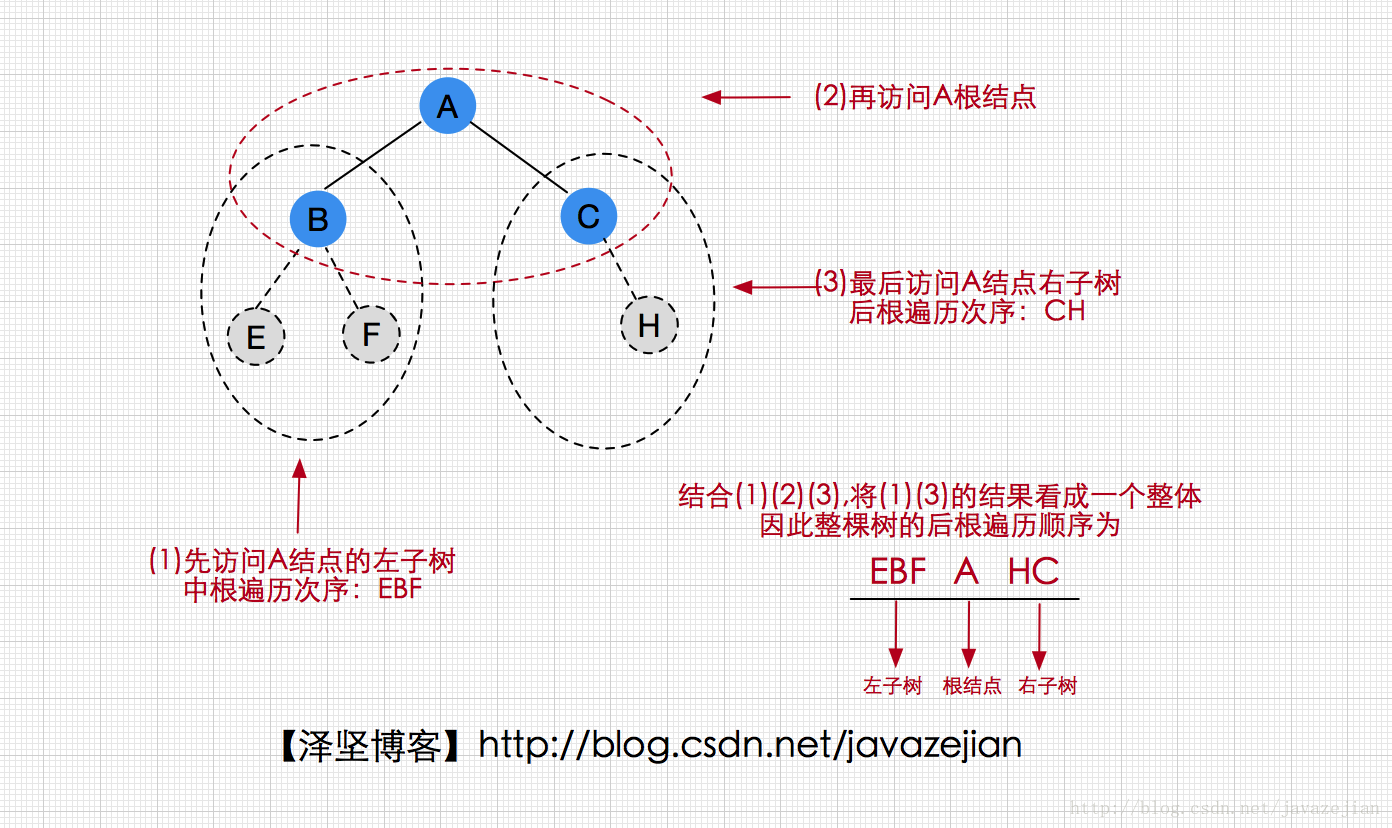
后根次序遍历的算法规则是,先访问左子树,再访问右子树,最后访问根结点,如下图(递归思维):
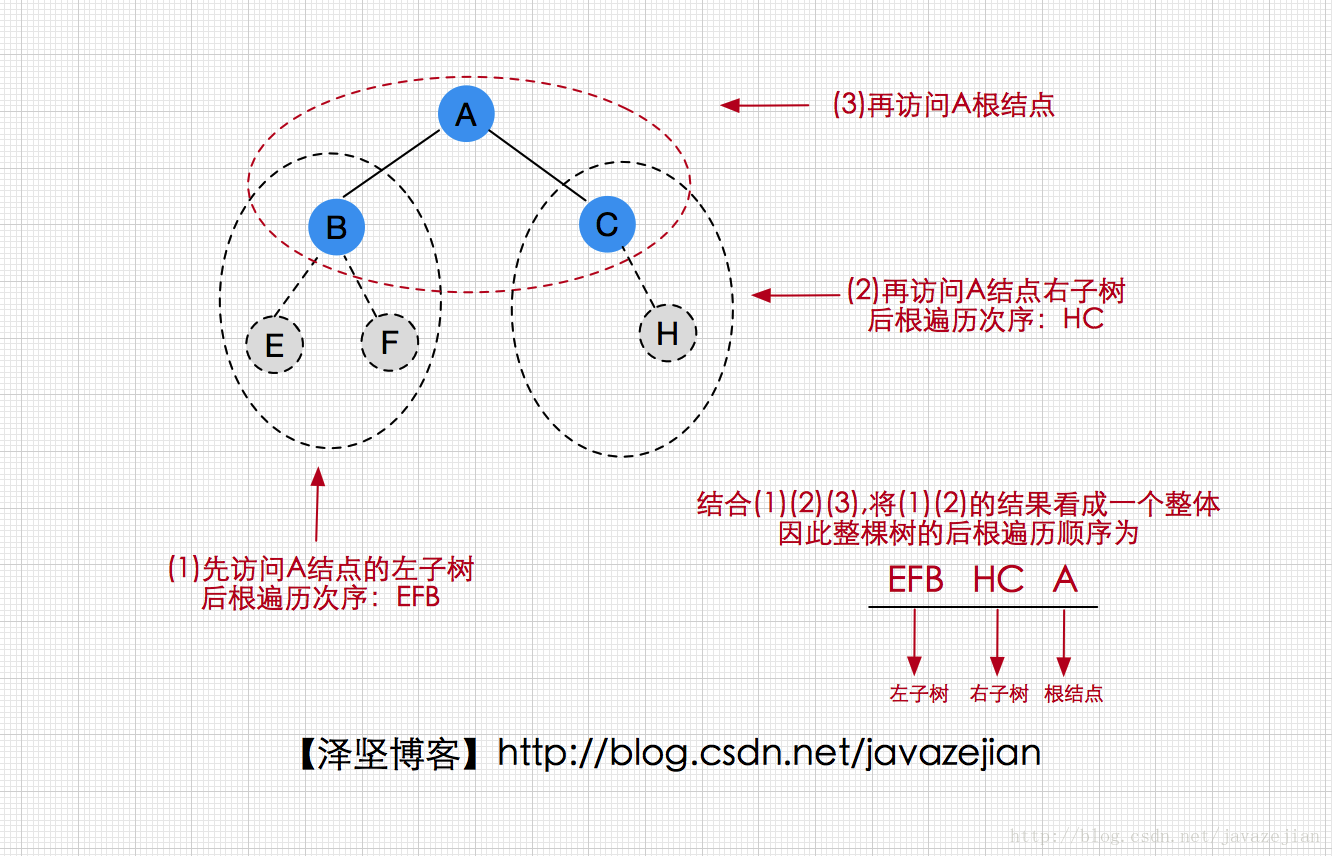
后根次序遍历算法代码如下:
@Override
public String postOrder() {
String sb=postOrder(root);
if(sb.length()>0){
//去掉尾部","号
sb=sb.substring(0,sb.length()-1);
}
return sb;
}
/**
* 后根遍历
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* @param subtree
* @return
*/
public String postOrder(BinaryNode subtree) {
StringBuffer sb=new StringBuffer();
if (subtree!=null) {//递归结束条件
//先遍历左子树
sb.append(postOrder(subtree.left));
//再遍历右子树
sb.append(postOrder(subtree.right));
//最后遍历根结点
sb.append(subtree.data+",");
}
return sb.toString();
}同样的,我们也可以借助栈容器使用非递归的遍历算法实现中根遍历,算法实现如下:
/**
* 非递归后根遍历
* @return
*/
public String postOrderTraverse(){
StringBuffer sb=new StringBuffer();
//构建用于存放结点的栈
LinkedStack> stack=new LinkedStack<>();
BinaryNode currentNode =this.root;
BinaryNode prev=this.root;
while (currentNode!=null||!stack.isEmpty()){
//把左子树加入栈中,直到叶子结点为止
while (currentNode!=null){
stack.push(currentNode);
currentNode=currentNode.left;
}
//开始访问当前结点父结点的右孩子
if(!stack.isEmpty()){
//获取右孩子,先不弹出
BinaryNode temp=stack.peek().right;
//先判断是否有右孩子或者右孩子是否已被访问过
if(temp==null||temp==prev){//没有右孩子||右孩子已被访问过
//如果没有右孩子或者右孩子已被访问,则弹出父结点并访问
currentNode=stack.pop();
//访问
sb.append(currentNode.data+",");
//记录已访问过的结点
prev=currentNode;
//置空当前结点
currentNode=null;
}else {
//有右孩子,则开始遍历右子树
currentNode=temp;
}
}
}
//去掉最后一个逗号
if(sb.length()>0){
return sb.toString().substring(0,sb.length()-1);
}else {
return sb.toString();
}
}层次遍历算法的实现
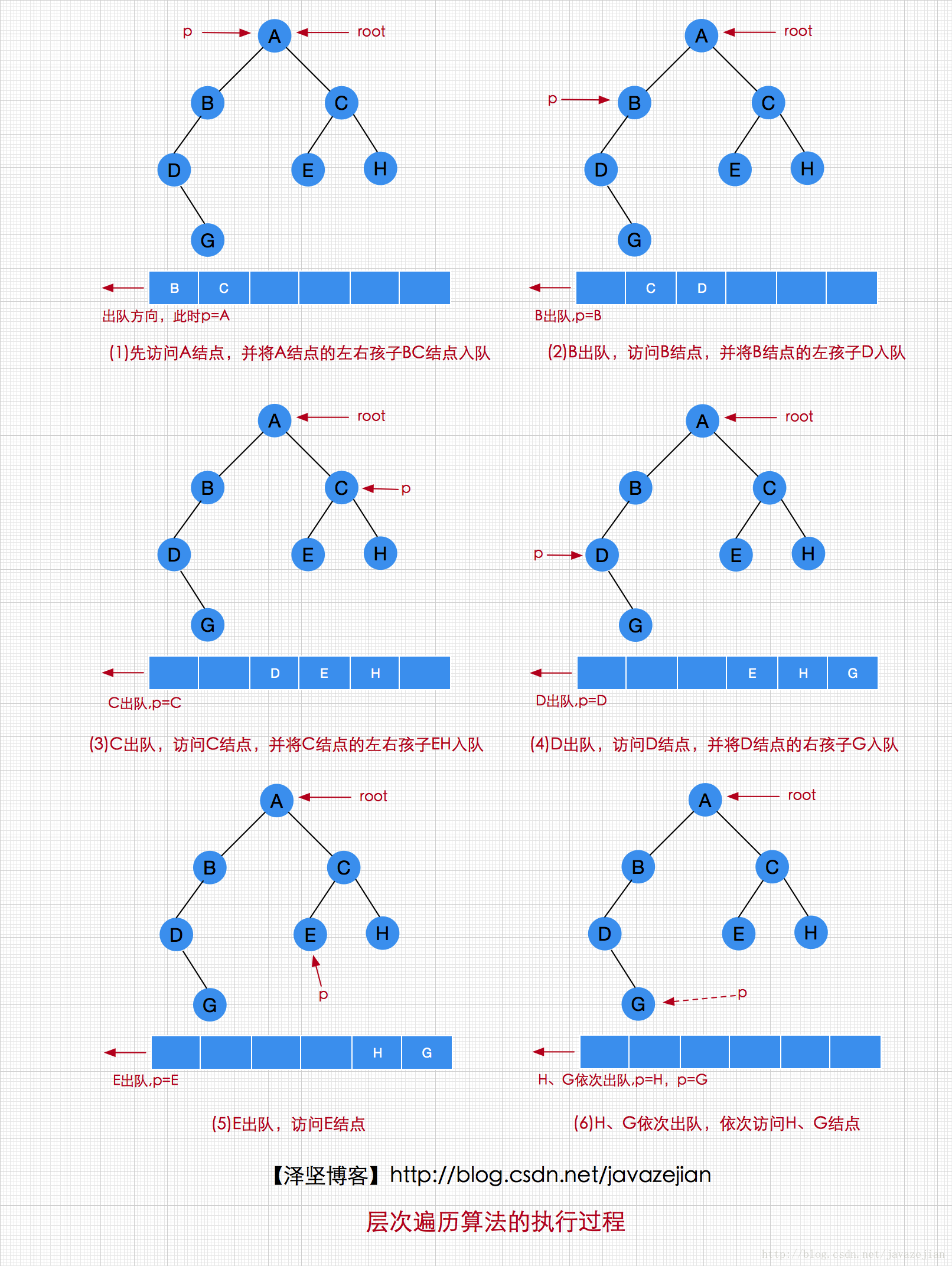
分析完前面的3种遍历算法,我们最后来分析一下层次遍历,二叉查找树的层次遍历特性就是兄弟优先访问,两个兄弟结点的访问顺序是先左后右的。同样它们的后代结点的访问次序也是先左后右,左兄弟的所有孩子结点一定优先右兄弟的孩子访问。对于二叉查找树的层次遍历算法,我们需要明确如何解决一下的存在的问题(假设p从根结点开始访问):
- p点如何到达其兄弟结点? B->C
- p点如何到达它同层下一个结点(非兄弟结点)?D->E
- p点如何在访问完当前层的最后一个结点时,进入下一层的第一个结点?C->D
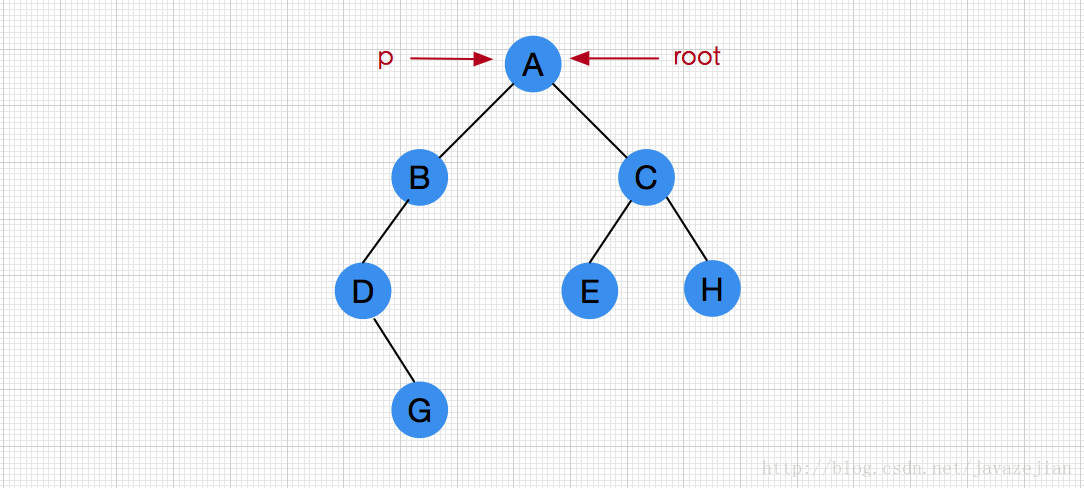
很显然,我们现在遇到的问题跟前面非递归算法遍历的问题有些类似,也就是二叉链表的本身根本无法满足以上任意一个问题,因为从B到C,从D到E,从C到D根本没有桥梁,此时肯定得借助第3方容器来满足需求,那么这个容器该如何选呢?该容器必须告诉我们下一个访问结点是谁?层次遍历的规则是兄弟优先,从左往右,因此,在访问时,必须先将当前正在访问的结点P的左右孩子依次放入容器,如P=C时,E、H必须已在栈中,而且先进入必须先访问,即先进E再进H,然后先访问E再访问H,显然该容器必须满足“先进先出”的原则,那也就是队列了,这里我们选择LinkedQueue队列,层次遍历算法描述如下:
p点从根结点开始访问,设一个空队列,当前p结点不为空时,重复以下操作:
① 访问p结点,将p结点的左右孩子依次入队。
② 使p指向一个出队结点,重复①的操作,直到队列为空。
其过程如下图所示:
层次遍历算法实现如下:
/**
* 层次遍历
* @return
*/
@Override
public String levelOrder() {
/**
* 存放需要遍历的结点,左结点一定优先右节点遍历
*/
LinkedQueue> queue=new LinkedQueue<>();
StringBuffer sb=new StringBuffer();
BinaryNode p=this.root;
while (p!=null){
//记录经过的结点
sb.append(p.data);
//先按层次遍历结点,左结点一定在右结点之前访问
if(p.left!=null){
//孩子结点入队
queue.add(p.left);
}
if (p.right!=null){
queue.add(p.right);
}
//访问下一个结点
p=queue.poll();
}
return sb.toString();
}完全二叉树的构造与实现
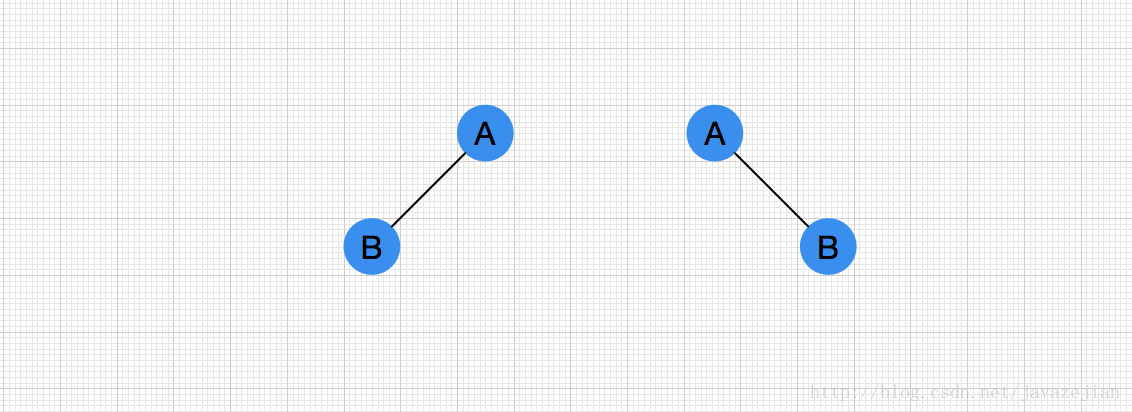
明白了层次遍历算法后,我们可以利用层次遍历算法来构建一棵完全二叉树,为什么是完全二叉树而不是二叉树呢?显然层次遍历不能确定唯一的一棵二叉树,看个简单的例子,层次遍历顺序为AB时,有如下两种情况:
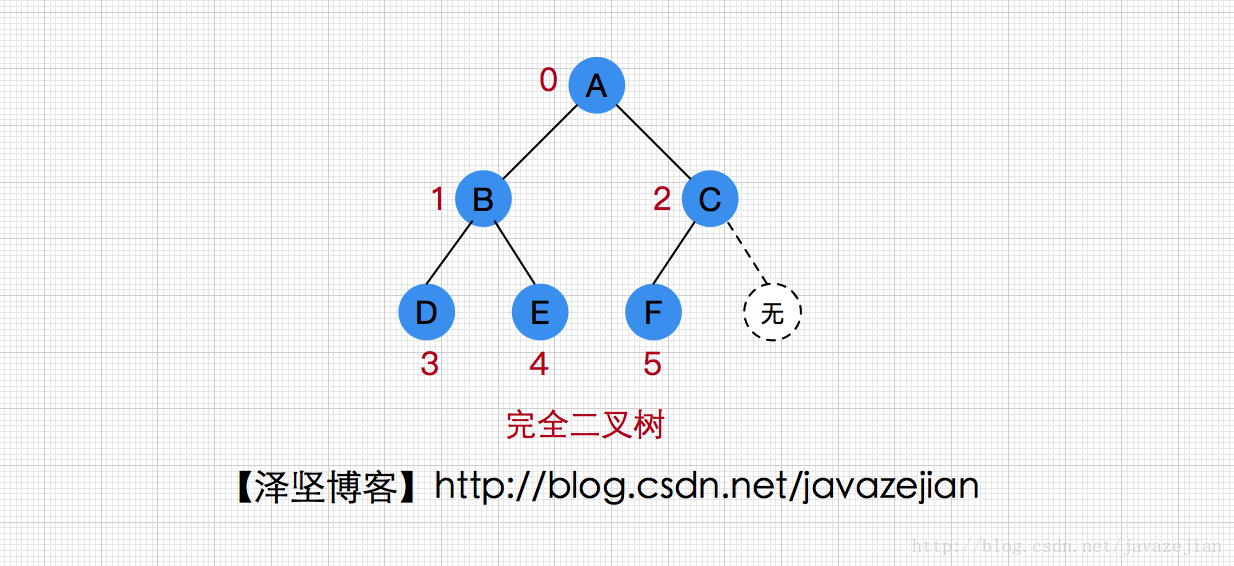
那为什么层次遍历就可以确定完全二叉树呢?这是因为完全二叉树的特性所决定的,一棵具有n个结点的完全二叉树,对于序号为i(0≤i<n)的结点,则有如下规则
①若i=0,则i为根结点,无父母结点;若i>0,则i的父母结点序号为⌊i−12⌋(向下取整)。
②若2i+1<n,则i的左孩子结点序号为2i+1,否则i无左孩子。
③若2i+2>n,则i的右孩子结点序号为2i+2,否则i无右孩子。
因此很容易知道第0个结点就是完全二叉树,而左孩子结点序号为2i+1,否则没有左孩子,右结点序号为2i+2,否则没有右孩子,这样的编号恰好符合层次遍历的访问顺序,因此层次遍历确实可以确定一棵完全二叉树,如下图:
完全二叉树的构造代码实现如下,注释清晰,就不解释了:
package com.zejian.structures.Tree.BinaryTree;
import com.zejian.structures.Queue.LinkedQueue;
/**
* Created by zejian on 2016/12/17.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* 利用层次遍历原理构造完全二叉树
*/
public class CompleteBinaryTree extends BinarySearchTree {
/**
* 构建空完全二叉树
*/
public CompleteBinaryTree()
{
super();
}
/**
* 以层序遍历构造完全二叉树
* @param levelOrderArray
*/
public CompleteBinaryTree(T[] levelOrderArray)
{
this.root = create(levelOrderArray, 0);
}
/**
* 层次遍历构造完全二叉树
* @param levelOrderArray
* @param i
* @return
*/
public BinaryNode create(T[] levelOrderArray ,int i){
if(levelOrderArray ==null){
throw new RuntimeException("the param 'array' of create method can\'t be null !");
}
BinaryNode p = null;
if (i(levelOrderArray[i],null,null);
p.left=create(levelOrderArray,2*i+1); //根据完全二叉树的性质 2*i+1 为左孩子结点
p.right=create(levelOrderArray,2*i+2); //2*i+2 为右孩子结点
}
return p;
}
/**
* 搜索二叉树的包含操作和移除操作不适合层次遍历构造的完全二叉树
* 根据层次遍历构建的二叉树必须用层次遍历来判断(仅适用层次遍历构建的完全二叉树)
* @param data
* @return
*/
@Override
public boolean contains(T data) {
/**
* 存放需要遍历的结点,左结点一定优先右节点遍历
*/
LinkedQueue> queue=new LinkedQueue<>();
StringBuffer sb=new StringBuffer();
BinaryNode p=this.root;
while (p!=null){
//判断是否存在data
if(data.compareTo(p.data)==0){
return true;
}
//先按层次遍历结点,左结点一定在右结点之前访问
if(p.left!=null){
//孩子结点入队
queue.add(p.left);
}
if (p.right!=null){
queue.add(p.right);
}
//访问下一个结点
p=queue.poll();
}
return false;
}
/**
* 搜索二叉树的包含操作和移除操作不适合层次遍历构造的完全二叉树
* @param data
* @return
*/
@Override
public void remove(T data) {
//do nothing 取消删除操作
}
/**
* 完全二叉树只通过层次遍历来构建,取消insert操作
* @param data
*/
@Override
public void insert(T data) {
//do nothing //取消insert操作
}
/**
* 测试
* @param args
*/
public static void main(String args[])
{
String[] levelorderArray = {"A","B","C","D","E","F"};
CompleteBinaryTree cbtree = new CompleteBinaryTree<>(levelorderArray);
System.out.println("先根遍历:"+cbtree.preOrder());
System.out.println("非递归先根遍历:"+cbtree.preOrderTraverse());
System.out.println("中根遍历:"+cbtree.inOrder());
System.out.println("非递归中根遍历:"+cbtree.inOrderTraverse());
System.out.println("后根遍历:"+cbtree.postOrder());
System.out.println("非递归后根遍历:"+cbtree.postOrderTraverse());
System.out.println("查找最大结点(根据搜索二叉树):"+cbtree.findMax());
System.out.println("查找最小结点(根据搜索二叉树):"+cbtree.findMin());
System.out.println("判断二叉树中是否存在E:"+cbtree.contains("E"));
}
}
二叉树的构造与实现
了解了完全二叉树的构造,现在我们回过头来看看二叉树又该如何构造呢?显然从完全二叉树的分析中发现,无论是先根遍历或者是中根遍历还是后根遍历,都无法唯一确定一棵树,都将面临之前的问题,遍历顺序为AB的树都可能有两种情况。因此已知二叉树的一种遍历顺序,不能确定唯一一棵二叉树。这是因为后根和先根次序反映的都是父母与孩子结点间的关系而没有反映兄弟间的关系,而中根次序反映的则是兄弟结点间的关系。既然这样,我们能不能考虑结合两种遍历顺序来构造一个二叉树呢?答案是肯定的,确实可以通过先根遍历和中根遍历次序或者后根和中根遍历次序唯一确定一棵二叉树,而先根和后根遍历反应的都是父母与孩子结点的关系,自然也就无法确定一棵唯一二叉树了,如给出先根顺序AB和后根顺序BA,可以确定A是根结点,但B呢,是左孩子还是右孩子呢?无法确定,下面我们案例来分析上面两种情况。
先根与中根次序构建二叉树及其代码实现
已知先根序列preList=ABDGCEFH和中根序列inList=DGBAECHF,确定二叉树的过程如下:
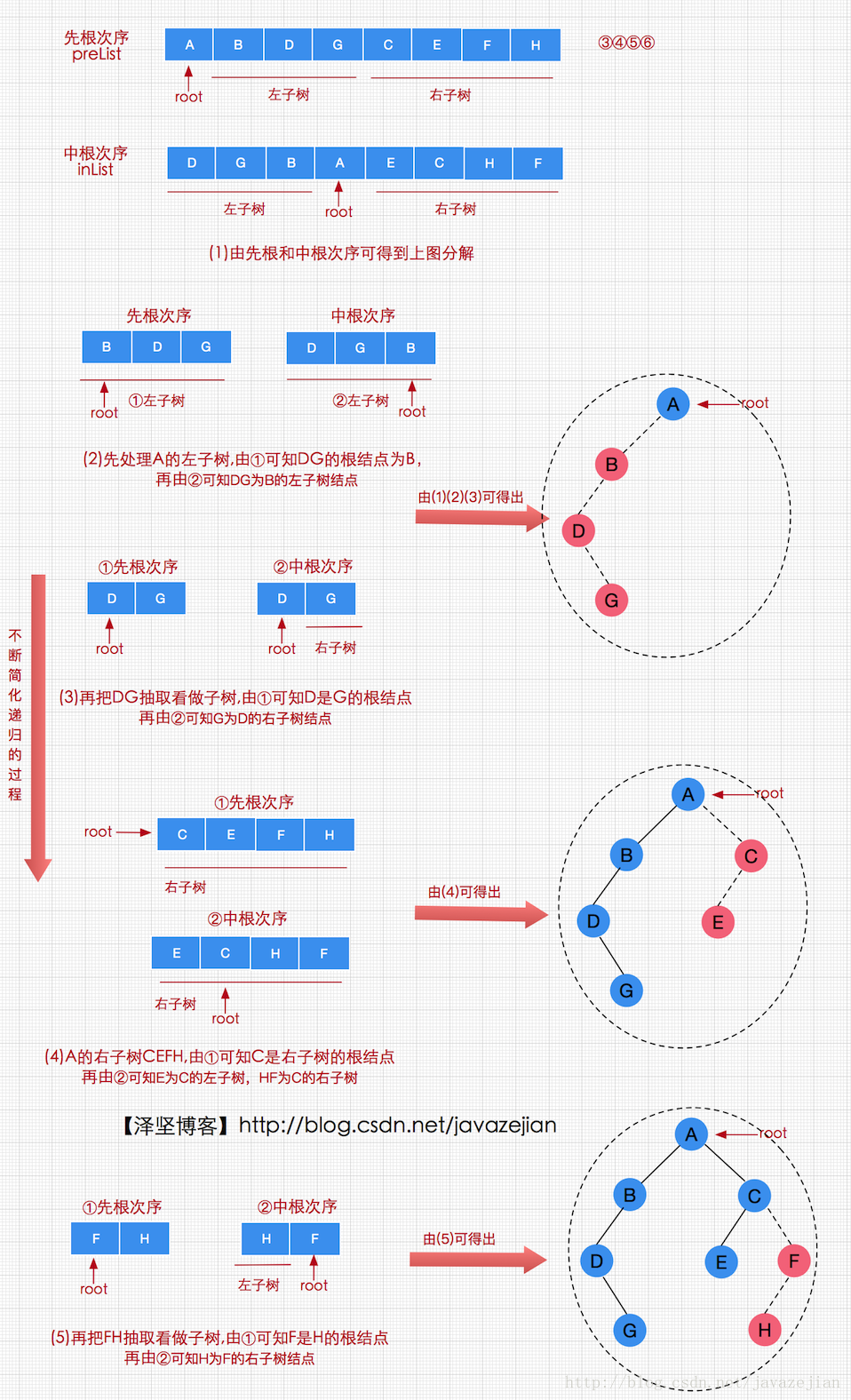
从图中我们可以发现整个构建过程都是在不断递归,即将复杂树简化为子树进行求解。上述过程我们可以这样描述,设数组preList和inList分别表示一个二叉树的先根和中根遍历次序,两个序列的长度都为n,则二叉树构建过程分如下步骤:
①由先根遍历次序可知,二叉树的根结点为preList[0],该根结点也肯定在中根序列中,设中根序列inList中根结点的位置为i(0≤i≤n),则有preList[0]=inList[i]
②根据中根遍历次序可知,inList[i]之前的结点都为根结点的左子树,inList[i]之后的结点都为根结点的右子树,因此根结点的左子树由i个结点组成,子序列如下:
左子树的先根序列:preList[1] , … , preList[i]
左子树的中根序列:inList[0] , … , inList[i-1]
根结点的右子树有n-i-1个结点组成,子序列如下:
右子树的先根序列:preList[i+1] , … , preList[n-1]
右子树的中根序列:inList[i+1] , … , inList[n-1]
③ 循环递归步骤①②,即可确定二叉树
以上3个步骤便是通过先根次序和中根次序确定一棵二叉树的过程,大家可结合图理解这过程,这里顺带给出实现代码如下:
/**
*Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* 根据先根和中根遍历算法构造二叉树
* @param preList 先根遍历次序数组
* @param inList 中根遍历次序数组
* @param preStart
* @param preEnd
* @param inStart
* @param inEnd
* return root 最终返回的根结点
*/
public BinaryNode createBinarySearchTreeByPreIn(T[] preList , T[] inList,int preStart ,int preEnd ,int inStart ,int inEnd){
//preList[preStart]必须根结点数据,创建根结点root
BinaryNode p=new BinaryNode<>(preList[preStart]);
//如果没有其他元素,就说明结点已构建完成
if (preStart == preEnd && inStart == inEnd) {
return p;
}
//找出中根次序的根结点下标root
int root=0;
for (root = inStart; root < inEnd; root++) {
//如果中根次序中的元素值与先根次序的根结点相当,则该下标index即为inList中的根结点下标
if (preList[preStart].compareTo(inList[root])==0){
break;
}
}
//获取左子树的长度
int leftLength=root-inStart;
//获取右子树的长度
int rightLength=inEnd-root;
//递归构建左子树
if(leftLength>0){
//左子树的先根序列:preList[1] , ... , preList[i]
//左子树的中根序列:inList[0] , ... , inList[i-1]
p.left=createBinarySearchTreeByPreIn(preList,inList,preStart+1,preStart+leftLength,inStart,root-1);
}
//构建右子树
if (rightLength>0){
//右子树的先根序列:preList[i+1] , ... , preList[n-1]
//右子树的中根序列:inList[i+1] , ... , inList[n-1]
p.right=createBinarySearchTreeByPreIn(preList,inList,preStart+leftLength+1,preEnd,root+1,inEnd);
}
return p;
}后根与中根次序构建二叉树及其代码实现
同样的情况,根据中根次序和后根次序,我们也可以确定唯一一棵二叉树,后根次序为GDBEHFCA,中根次序为DGBAECHF,其确定二叉树执行过程如下:
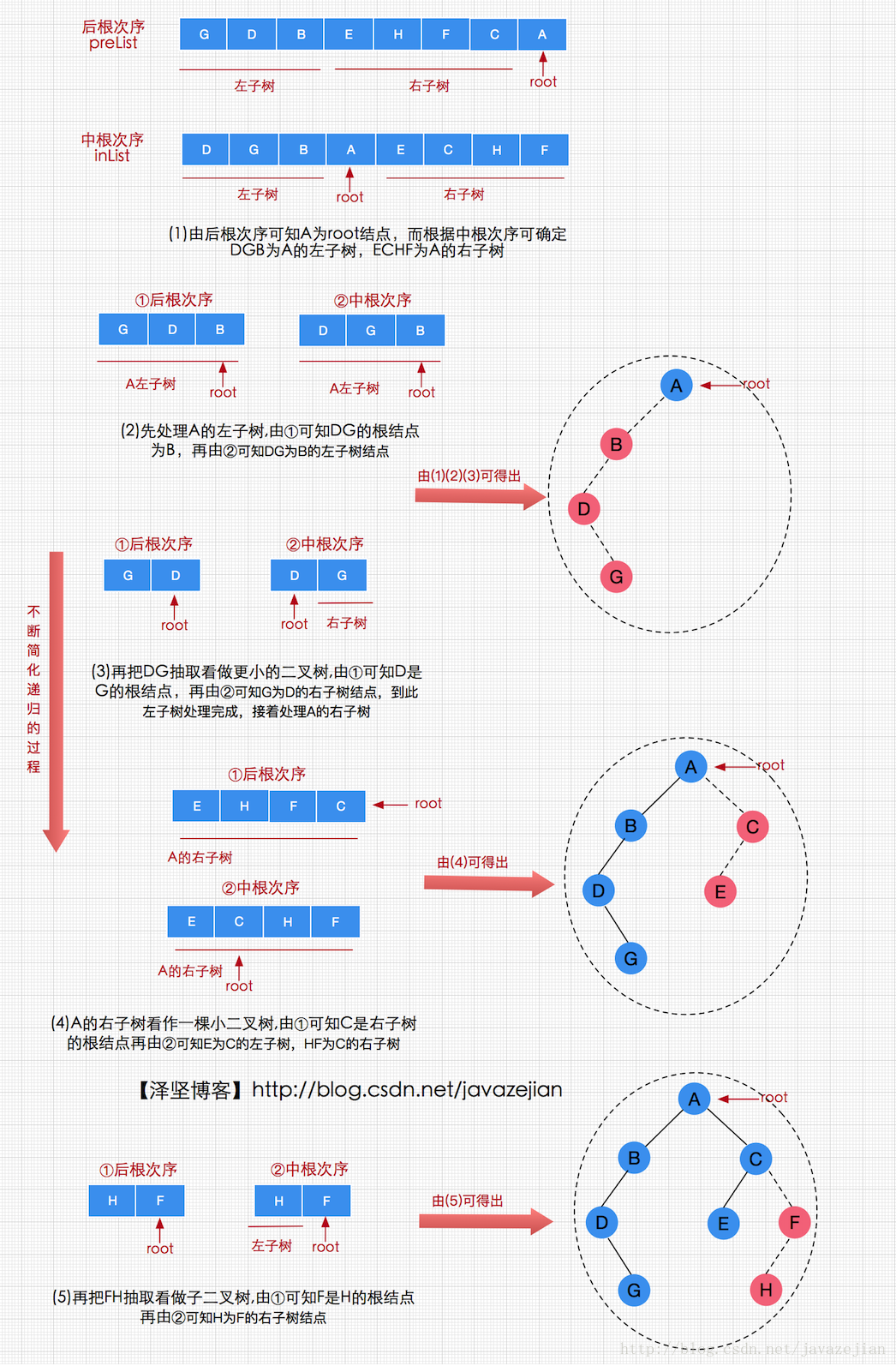
上述过程我们也可以这样描述,设数组postList和inList分别表示一个二叉树的后根和中根遍历次序,两个序列的长度都为n,则二叉树构建过程分如下步骤:
①由后根遍历次序可知,二叉树的根结点为preList[n-1],该根结点也肯定在中根序列中,设中根序列inList中根结点的位置为i(0≤i≤n),则有postList[n-1]=inList[i]
②根据中根遍历次序可知,inList[i]之前的结点都为根结点的左子树,inList[i]之后的结点都为根结点的右子树,因此根结点的左子树由i个结点组成,子序列如下:
左子树的后根序列:postList[0] , … , preList[i-1]
左子树的中根序列:inList[0] , … , inList[i-1]
根结点的右子树有n-i-1个结点组成,子序列如下:
右子树的后根序列:postList[i] , … , postList[n-2]
右子树的中根序列:inList[i+1] , … , inList[n-1]
③ 循环递归步骤①②,即可确定二叉树
到此利用后根、中根遍历算法构建二叉树的过程就已全部描述完成了,实现代码如下:
/**
*Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
* 后根/中根遍历构建二叉树
* @param postList 后根遍历序列
* @param inList 中根遍历序列
* @param postStart
* @param postEnd
* @param inStart
* @param inEnd
* @return 根结点
*/
public BinaryNode createBinarySearchTreeByPostIn(T[] postList,T[] inList,int postStart,int postEnd,int inStart,int inEnd){
//构建根结点
BinaryNode p=new BinaryNode<>(postList[postEnd]);
if(postStart==postEnd && inStart==inEnd){
return p;
}
//查找中根序列的根结点下标root
int root=0;
for (root=inStart;root0){
//postStart+leftLenght-1:后根左子树的结束下标
p.left=createBinarySearchTreeByPostIn(postList,inList,postStart,postStart+leftLenght-1,inStart,root-1);
}
//递归构建右子树
if(rightLenght>0){
p.right=createBinarySearchTreeByPostIn(postList,inList,postStart+leftLenght,postEnd-1,root+1,inEnd);
}
return p;
} ok~,本篇就到这吧,已很长了,树的知识点确实挺多了,一篇是不可能涵盖完整的,剩余的我们后面再另外开篇聊吧,下面给出本篇的全部实现代码:
github源码下载(含文章列表)
