

简介
最近因为要找工作,顺应互联网大潮,复习了一下后端的东西。为了把这些知识都串起来,写了一个简单地 HTTP 服务器。对于对 Web 感兴趣的同学应该是一个不错的练手项目。因此,作为专栏的第一个系列,我们要造的「轮子」是 HTTP 服务器。
关于编程语言:为了突出主干,和易于理解, 我选择 Python 作为这个系列的主要编程语言。与此同时,Python 在 Web 开发中也有很成熟的应用和框架(比如:知乎),这个选择也算是兼顾了实用性。考虑到兼容性的问题,Python 的版本使用 2.7,但是我会尽量编写 2.X 和 3.X 都兼容的代码,并在不兼容的地方给出解决方案。如果你对 Python 没有什么了解,也没有关系。直接阅读代码,多少也能猜个八九不离十。或者可以考虑阅读《Python 简明教程》,一个下午的时间足够让你掌握到能够看懂本系列的程度。
关于最终目标:本系列最终会完成一个单线程非阻塞多路复用的 HTTP 服务器(no-blocking & multiplexing IO)。主要关注服务器的部分,较少关注 Web 框架的内容。不排除后期会添加相关章节或者多进程模式之类的内容。同时为了使本系列尽量的贴近实用,很多地方会以 Tornado 中的方法作为标杆。但是本系列并不打算做成「Tornado 源码剖析」或者直接复刻 Tornado 的源代码,只是借鉴其思想。
关于平台:本系列主要针对 mac OS 和 Linux 平台。并不保证这些代码一定能够在 windows 平台上跑通。我会尽量给出兼容的方案,对于 Windows 平台 理论上来讲大部分代码也能够运行,但是可能会有性能等方面的影响。
接下来就让我们进入正题吧。
HTTP Server Ver 0.1
复制下边这一段代码,然后运行。
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind(('localhost', 8888))
s.listen(5)
while(True):
conn, name = s.accept()
print(conn.recv(1024))
# 如果你使用的是 python 3 请在字符串前边加 b。如 b'''content'''
conn.sendall('''HTTP/1.1 200 OK
Build A Web Server
Hello World, this is a very simple HTML document.
''')
conn.close()
打开浏览器,输入 http://127.0.0.1:8888/ 你会看到如下结果:
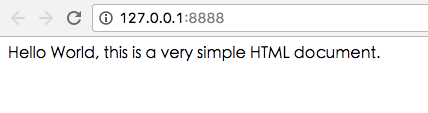 铛铛!一个超级简单地 Web 服务器诞生了。接下来我们就要搞清楚这几行代码到底干了什么。
铛铛!一个超级简单地 Web 服务器诞生了。接下来我们就要搞清楚这几行代码到底干了什么。
Socket 网络通信简介
Socket 是电脑网络中进程间数据流的端点,也是传输层网络通信的 API。HTTP 作为一个应用层的协议,一般是基于传输层的 TCP 协议的。因此我们要在 TCP 协议上构建我们的程序,也就是使用 Socket 传输 HTTP 的消息。如果你对 Socket 网络编程比较熟悉,可以直接跳过这一节。端口、IP 之类的基本概念就不重复了。下边这张图展示了 Socket TCP 通信的步骤:
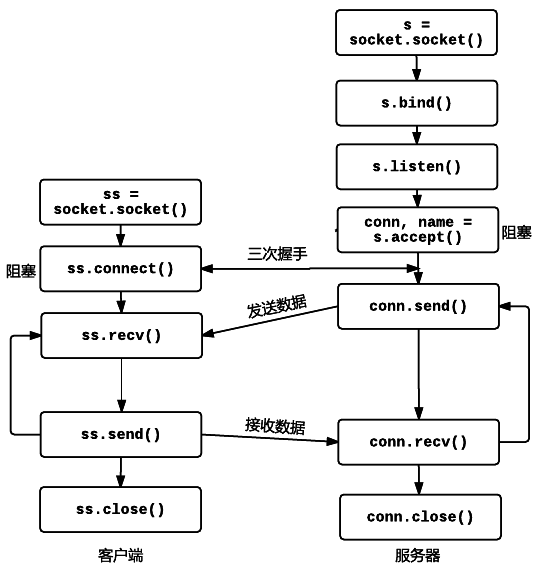
- 服务器需要新建一个 socket 对象,并将这个对象绑定在某个特定的端口。socket.AF_INET 代表 IPV4 协议族,socket.SOCK_STREAM 代表是 TCP 协议。下一行的 setsockopt 表示这个地址可以重复使用。
- 设置这个 socket 对某个特定的端口进行监听,参数代表等待队列的大小。
- 调用 accept 方法,等待客户端连接到这个端口上。需要注意的是调用了 accept 方法以后当前进程会阻塞在 accept 函数上,直到收到一个新的连接请求。
- 客户端新建 socket 对象。调用 connect 方法去访问特定的地址+端口号。此时当前进程会阻塞在这个位置,直到建立连接。connect 和 accept 建立连接的这个过程,就对应着 TCP 的三次握手过程。
- 一旦连接建立,就可以使用 send 和 recv 互相之间发送消息了。recv 的参数代表接收多少个字节。
- 当通讯结束的时候需要使用 close 关闭 socket。
这个过程大家可以打开两个 shell,一个做为客户端,一个做为服务器端。注意体会一下阻塞的过程,注意 accept 是什么时候返回的。如下图所示:
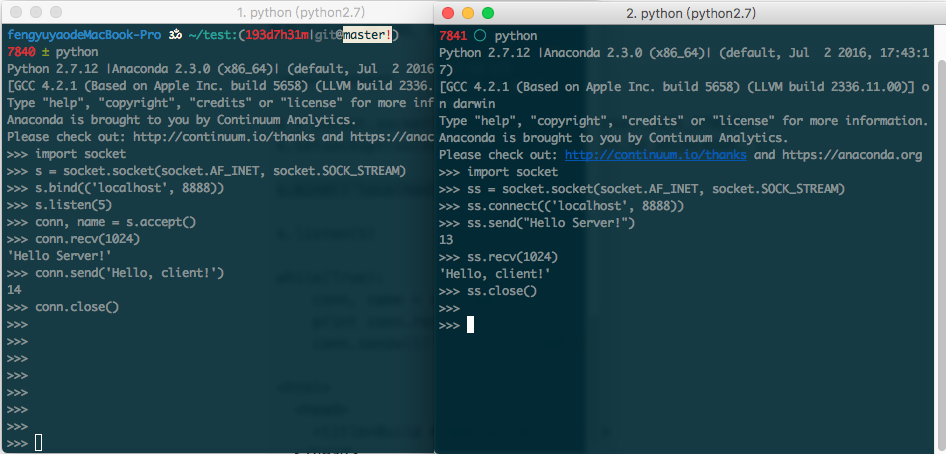 对于没有接触过网络编程的读者这里有个问题需要说明下。为什么服务器端和客户端的操作方式是不一样的?这是因为,socket 是一个从端口到端口的通信方式。一对端口号对应一对 socket。如果你要连接一台服务器,你必须知道他的端口号是多少,因此服务器的端口号是不能够变动的。但是为了支持一个以上的 socket 进行连接必须准备多个端口号进行通信。因此,为了解决这个问题,服务器端需要先「监听」一个固定的端口。一旦有客户端前来连接,就指派给他们一对随机的端口号。一旦连接建立以后,端口号的值就不在重要了。
对于没有接触过网络编程的读者这里有个问题需要说明下。为什么服务器端和客户端的操作方式是不一样的?这是因为,socket 是一个从端口到端口的通信方式。一对端口号对应一对 socket。如果你要连接一台服务器,你必须知道他的端口号是多少,因此服务器的端口号是不能够变动的。但是为了支持一个以上的 socket 进行连接必须准备多个端口号进行通信。因此,为了解决这个问题,服务器端需要先「监听」一个固定的端口。一旦有客户端前来连接,就指派给他们一对随机的端口号。一旦连接建立以后,端口号的值就不在重要了。
socket 连接建立后,就可以互相传递消息了。HTTP 协议是个纯文本的协议,这意味着我们直接传递纯文本就可以了。上边 sendall 所传输的字符串内容,就是 HTTP 协议的消息内容了。换句话说,一个 Web 服务器其实就是根据约定好的方法生成对应的 HTTP 消息内容,然后传输给对方。上边的一段代码就是一个完成特定功能的 HTTP 服务器,只是这个服务器,功能简陋,性能低下。用 wrk 测试一下
每秒钟能够处理 192 个请求。我们接下来的的任务就是如何提升性能,使得服务器能够处理更多的请求。
HTTP 协议简介
要编写 Web 服务器,我们首先要了解 HTTP 协议是什么。如果你已经对 HTTP 协议有所了解可以跳过这部分。
HTTP 协议,又叫做超文本传输协议(HyperText Transfer Protocol)。主要目的是在 Web 服务器和浏览器之间传输信息。所谓「协议」可以简单地理解为双方为了通信所约定的一种方法和格式。所以对于 HTTP 协议我们只需要搞清楚两点:1.通信的方法;2. 通信的格式。
通信的方法:所幸 HTTP 协议是一个「无状态」协议。也就是说对于使用 HTTP 协议的服务器,每一次通信和上一次通信之间没有任何关系,服务器并不知道两次请求是否是同一个客户端发送的,也不知道这个客户端上次发送了什么。大致类似于手机里的语音助手或者微软小冰,你和它们之间的对话一般是不会考虑上一句对话的内容,因为这些语音助手也被设计成「无状态」的了。因此在通信方式上,大多数时候我们只需要认为一次 HTTP 会话是由一个 Request(请求) 和一个 Response(回应)组成的就可以了。一个 Request 对应一个 Response。每个 Response 发送结束后连接就会被关闭(short-lived 模式,下图所示)。
但是,我们平时在使用互联网的时候,各个网站明明是能够记住用户状态的,比如登录之类的,这是怎么回事呢?这些功能都是由 Web 框架通过 Cookie 之类的功能在 HTTP 协议之上实现的。简单的来说相当于服务器发给浏览器一个证明,浏览器每次发送请求的时候只需要把这个证明一起发过去就可以表明自己的身份了。因为和主题无关,就不赘述了,感兴趣的读者可以自己查阅相关资料。
还有一个需要解决的问题是,有人会记得 http 里边一个 「Connection:keep-alive」字段(如果不知道,跳过这一段就好)。既然是「无状态」的,为什么会有「keep-alive」呢?这里的「无状态」主要是指,服务器无法通过 HTTP 协议本身「记忆」用户的状态,而「keep-alive」则指的是客户端与服务器之间的 socket 在一次通信结束后并不立即关闭,可以重复使用。但是里边传输的协议消息依旧是无状态的。这么做的主要目的,是为了避免 socket 建立过程的开销。socket 的建立开销是很大的,至少要有三次握手,也就是说三次往返。如果短时间内有大量消息需要传递的话,这个花费是很可观的。除了「keep-alive」以外为了优化 http 的性能,还有 http pipelining 之类的优化方法。这种策略会一次发送多个请求(见下图),为了突出主干就不赘述了。
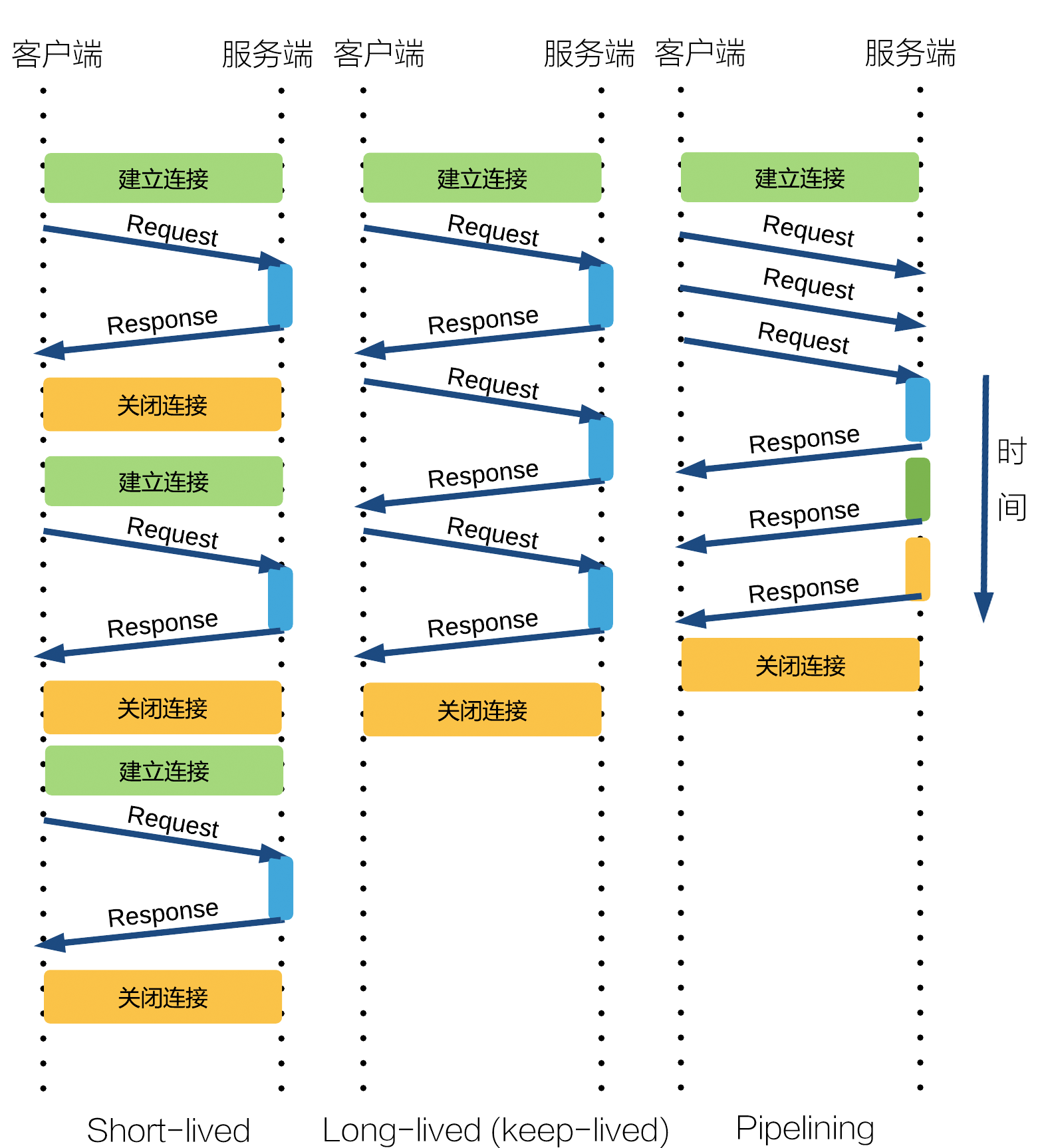
解决了通信方法的问题,我们回头来看看 HTTP 通信的格式。
通信的格式:这一节主要有三个部分,URL 的格式、Request 的格式和 Response 的格式。
URL的格式:URL 又叫统一资源定位符(Uniform Resource Locator)。http 协议最初设计的目的就是为了取得服务器上的某个资源文件。所以 http 协议的 URL 也是按照这个目的来设计的,例如:
http://210.30.97.149:80/web/index.html
这个 url 翻译成自然语言就是「在 ip 为 210.30.97.149 的机器上使用 http 通过 80 端口取得 web 文件夹下的 index.html 文件」。服务器上的对应位置拿到 html 文件传输给浏览器,再由浏览器进行渲染。后来,Web 的功能越来越复杂,人们希望能够与服务器进行交互,于是就给 url 加上了参数,例如:
http://210.30.97.149:80/web/index.html?keyword=val&fontsize=12
https://www.google.com.hk/search?q=something
此处的 search 并不代表服务器上边的 search 文件。它表示的是搜索这个动作,q 则代表搜索的参数,即关键字。这个 url 的作用就是使用 google 搜索「something」。
完整地 URL 格式定义如下(方框中的内容代表可选):
scheme:[//[user:password@]host[:port]][/]path[?query]
协议:[//[用户名:密码@]主机名[:端口号]][/]路径[?查询]
- 协议:即通信协议一般有 http、https、ftp 等。在我们的例子中此处会一直是 http,因为我们使用的是 http 协议。
- 用户名和密码:有的服务器会要求登录,所以需要输入用户名和密码。
- 主机名:也就是我们常说的域名或者 IP。这个名字代表了互联网上的一台主机(抽象的)。可以简单理解为你要访问的网站。
- 端口号:就是 tcp 或者 udp 的端口号。http 一般是 80,可以省略不写。
- 路径:最初代表主机上精确的指向某个资源的路径,后来随着技术的发展,渐渐变成了一个抽象的指示符,代表你要执行的动作,或者访问的页面。
- 查询:以「?」开头。一般写在这里的是参数,参数是一组键值对(key-value)通过「=」链接,「&」进行分割。比如 name=apple&weight=12pt,这个例子中有两个参数,一个是 name,它的值是 apple 还有一个是 weight 他的值是 12pt。
Request 的格式:具体格式如下(//后是注释):
方法名 URL 协议版本 //请求行
字段名:字段值 //消息报头
字段名:字段值 //消息报头
...
字段名:字段值 //消息报头
请求正文 //可选
- 方法名:HTTP 协议的 Request 方法总共分为 8 种。限于篇幅我们只关注最常用的两种 GET 和 POST。其他的方法请自行查阅标准。要注意的是对于同一个 URL 进行不同方法的 Request 可以返回不同的结果。
- 协议版本:一般为 HTTP/1.0 或者 HTTP/1.1
- 消息报头:消息报头是一系列键值对,可以看做是发送给服务器的参数,定义了如何处理链接、消息内容和客户端信息等等。具体有哪些常见的字段,大家可以自行搜索,就不赘述了。
- 请求正文:需要传送的数据,可选。
指的注意的是消息报头和请求正文之间用空行(\r\n)隔开。
一个典型的 GET 请求的例子:
GET /web/index.html?q=1234&user=name HTTP/1.1
Host: google.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0)
Accept: text/html
一般来说 GET 请求表示从服务器上请求一个资源,通过 URL 来传递参数的,不包含消息正文。
一个典型的 POST 请求的例子:
POST /web/index.html HTTP/1.1
Host: google.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0)
Accept: text/html
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4
param1=val¶m2=val2
POST 请求和 GET 请求相比多了一个消息正文,表示向服务器传送一个数据,数据就放在消息正文中。
Response 的格式:
协议版本 状态码 状态描述 //状态行
字段名:字段值 //消息报头
字段名:字段值 //消息报头
...
字段名:字段值 //消息报头
响应正文 //可选
- 状态码:表示请求的结果,我们经常遇到的 404 就是一个状态码,代表请求的网页不存在。一般来说:
- 1xx:指示信息,表示请求已接收,继续处理
- 2xx:成功,表示请求已被成功接收、理解、接受
- 3xx:重定向,要完成请求必须进行更进一步的操作
- 4xx:客户端错误,请求有语法错误或请求无法实现
- 5xx:服务器端错误,服务器未能实现合法的请求
- 状态描述:用来描述状态的短语,比如 200 是 OK,404 是 Not Found
其余的部分和 Request 请求一样。一个具体的例子如下:
HTTP/1.1 200 OK
content-encoding:gzip
content-encoding:sdch
content-type:text/html; charset=UTF-8
date:Sun, 09 Oct 2016 13:02:56 GMT
Hi
请求的网页和资源会被放在请求正文里。比如上边这个例子,就是请求网页的 HTML 源代码。如果里边包含图片之类的静态资源,客户端会再次向服务器请求相应的内容。
到此为止,你已经掌握了如何使用 socket 去传递一个 HTTP 请求,以及 HTTP 请求的含义。下一篇文章我们将要讲解什么是 HTTP 服务器和 Web 框架,以及如何将它们组合起来。
