

本文会不定期更新,推荐watch下项目。
如果喜欢请star,如果觉得有纰漏请提交issue,如果你有更好的点子可以提交pull request。
本文的示例代码主要是基于logger、LogUtils和timber进行编写的,如果想了解更多请查看他们的详细解释。
我很推荐大家多多进行对比,选择适合你自己的库来使用。
本文固定连接:github.com/tianzhijiex…
一、背景
Android中的log是这么写的:
Log.d(TAG, "This is a debug log");android.util.Log类做的事情很简单,符合kiss原则,但是随着业务的不断发展,logcat中就会有多个部门的各种log,不同手机系统自己的一些log也会参杂进来,逼迫我们要扩展log类。
二、需求
- 我才不要每次打log都去想tag叫什么名字呢
- 通常情况下请自动把当前类名作为默认的tag,但也允许我自由指定
- 我希望我写的模板式代码越少越好,一个
logd就能打印一切 - 我要打印出list,map,json,pojo这样的对象
- 我的log绝对不要和其余的杂乱log混在一起
- log信息过长后应该要自动换行,我不允许我的log打印不全
- 我要我的log变的好看,直观,就是美
- log中还要能显示我当前的线程名,方便我调试多线程
- 我打出的log后面要根上这个log的地址,可以直接外链到log的位置
- release包中不能泄漏我高傲的log,但只要我想让它显示,release版本也阻挡不了我
- 在release版本中残留的log代码应该对app运行效率影响极低
- 它能自动将try-catch住的crash通过log上传到Crashlytics
回看这些需求,不合理么?其实很合理,我们的宗旨就是让无意义的重复代码去死,如果死不掉就交给机器来做。我们应该做那些真正需要我们做的事情,而不是像一个没思想的猿猴一般整天写模板式代码。这才是程序员思维,而不是程序猿思维!
注意:我希望只要写真正有意义的内容!
三、实现
分析上述的需求后,我将其分为四类: 使用、显示和扩展。
使用篇
建立包装类
无论一个第三方库有多好,我还是推荐不直接使用它,因为你很有可能会去替换这个第三方库,而且一个第三方库肯定无法满足各种奇葩需求。所以,对于网络库、图片库和log库来说,我们应该事先考虑在上面封装一层。
我们建立一个包装类,用这个包装类用来包裹Logger(logger是本文介绍的一个log库),下面是包装类的代码片段:
public static void d(@Nullable String info, Object... args) {
if (!mIsOpen) { // 如果把开关关闭了,那么就不进行打印
return;
}
Logger.d(info, args);
}对于包装类的起名最好不要和“Log”这个类似,能有明显的区别最好,一是防止自己手抖写错了,二是方便review的时候能快速检查出有没有误用原始的Log。
自动打tag
默认情况下可以把当前类名作为TAG的默认值,我们可以通过下面代码来得到当前类名:
private static String getClassName() {
// 这里的数组的index,即2,是根据你工具类的层级取的值,可根据需求改变
StackTraceElement thisMethodStack = (new Exception()).getStackTrace()[2];
String result = thisMethodStack.getClassName();
int lastIndex = result.lastIndexOf(".");
result = result.substring(lastIndex + 1, result.length());
return result;
}这样我们就轻易的摆脱了tag的纠缠。
需要注意的是,获取堆栈的方法是有性能消耗的,所以在主线程的log可能会引起一些卡顿,所以强烈建议在release版本中不要使用这个方法。
这个方法来自于豪哥的建议,这里感谢豪哥的意见。
自定义tag
除了自动打tag外,我们肯定要让其支持自定义tag:
public static void d(@NonNull String tag, String info, Object... args) {
Logger.t(tag).d(info, args);
}这个d(tag, info, args...)是上面d(info, args...)的扩展,这里要注意的是tag的选取。
常用的做法是用getSimpleName的方式来得到tag,但如果你加了混淆,很多类(Activity、View不一定会被混淆)就会被混淆为a/b/c这样的单词。因此,如果你的log要出现在混淆的包里的,我强烈建议去手动设置tag值,否则打出来的log就是很难过滤的了。
至于如何手动设置tag的值,下面会讲到logt这个快捷命令。
自定义全局tag和tag前缀
如果你的项目很庞大或者采用了插件化和组件化方案,那么你肯定会涉及到多人开发的问题。底层平台是暴露统一的log接口,但是上层开发人员种类繁多,如何在繁杂的log中找到自己部门的自己关心的log呢?
在这种情况下我们可以采用如下两种方案:
- 自行调试时关闭无关部门的log输出
- 每个部门有自定义的tag前缀
对于方案一,我们本身的log系统底层采用的是timber,它本身就是通过“种树”的方式进行log分发的,我们只需要在我们项目的最开始调用
Logger.uprootAll();
// or
Timber.uprootAll();将所有之前的log通道移除,这样就清空了无用的log了。
相比起方案一的简单粗暴,方案二倒是温和实用的多。我们通过在logger初始化设置一个tagPrefix,这个前缀就会伴随着我们私有项目的所有log了,以后直接搜索这个前缀就可以过滤出想要的信息了。

开启和关闭log
有时候在调试过程中可能会要支持测试同学的动态关闭和开启log的功能。
Logger.closeLog();
Logger.openLog(Log.INFO);这个操作可以支持在应用运行的时的任何时候进行开关。
将Log代码快捷模板
有人说我们IDE不都有代码提示了么,你还想怎么简化log的输入呢?这里可以利用as的模板提示的功能:
我们可以模仿原有的模板来做自己的代码模板,简化模板式代码的输入。至于具体模仿的方式我就不手把手教了,相当简单。下面仅展示下自带的log模板的使用:
生成TAG:
自动填写参数和方法名:
显示篇
让log更加美观
让log的输出直观、美观其实很简单,就是在输出前做点字符串拼接的工作,比如加上下面这行横线。
private static final String BOTTOM_BORDER = "╚═══════════════════════════";因为做了很多拼接的工作,所以好看的log也是消耗性能的。我的习惯是调试完毕后立刻删除无用的log,这样既能减少性能影响,也能减少同事的阅读代码的负担。采用轻量级美化后效果如下:
显示当前方法名、所在类并加超链
这个功能其实ide是原生支持的,不相信的话你随便用原生的log打印出onCreate: (MainActivity.java:31)试试。
我们可以通过下面的方法来做到更好的效果:
private static String callMethodAndLine() {
String result = "at ";
StackTraceElement thisMethodStack = (new Exception()).getStackTrace()[1];
result += thisMethodStack.getClassName()+ "."; // 当前的类名(全名)
result += thisMethodStack.getMethodName();
result += "(" + thisMethodStack.getFileName();
result += ":" + thisMethodStack.getLineNumber() + ") ";
return result;
}这里同样需要注意的是类在混淆后是得不到正确的名称的,所以可以酌情让activity、fragment、view不被混淆,具体方案还是看自己的取舍。
增加当前线程的信息
当你调试过多线程,你就会发现log中带有线程的信息是很方便的。
Thread.currentThread().getName()Logger的尾巴上会带有线程的名字,方便大家进行调试。
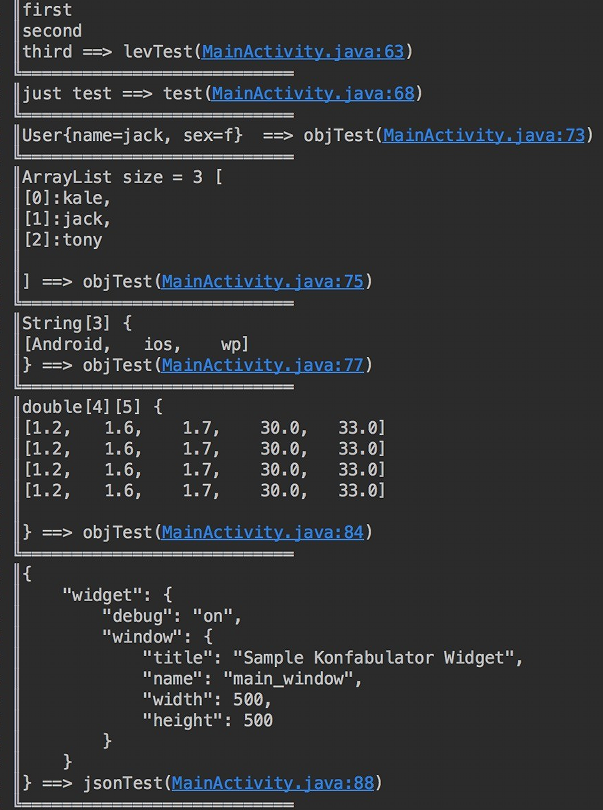
支持POJO、Map、Collection、jsonStr、Array
这个需求实现起来也比较容易:
- 如果是POJO,我们可用反射得到对象的类变量,通过字符串拼接的方式最终输出值
- 如果是map等数组结构,那么就用其内部的遍历依次输出值和内容
- 如果是json的字符串,就需要判断json的
{},[]这样的特殊字符进行换行处理
至于具体是如何实现的,大家移步去看源码就好,这个不是重点,重点是结果:
不推荐打印每次网络请求的json,只推荐在调试某个数据的时候进行打印,否则信息太多,而且效率很低,不实用。
自定义输出样式
我们看到了orhanobut/logger和elvishew/xLog都十分好看,但是tianzhijiexian/logger的log看起来就没那么美观了,所以这个库支持了自定的style,让使用者可以自定义输出样式。
PrintStyle.java
public abstract class PrintStyle {
@Nullable
protected abstract String beforePrint();
@NonNull
protected abstract String printLog(String message, int line, int wholeLineCount);
@Nullable
protected abstract String afterPrint();
}这个抽象类提供了三个方法,用来得到log打印前,打印时,打印后的内容,我们可以通过它来实现自定义的样式。
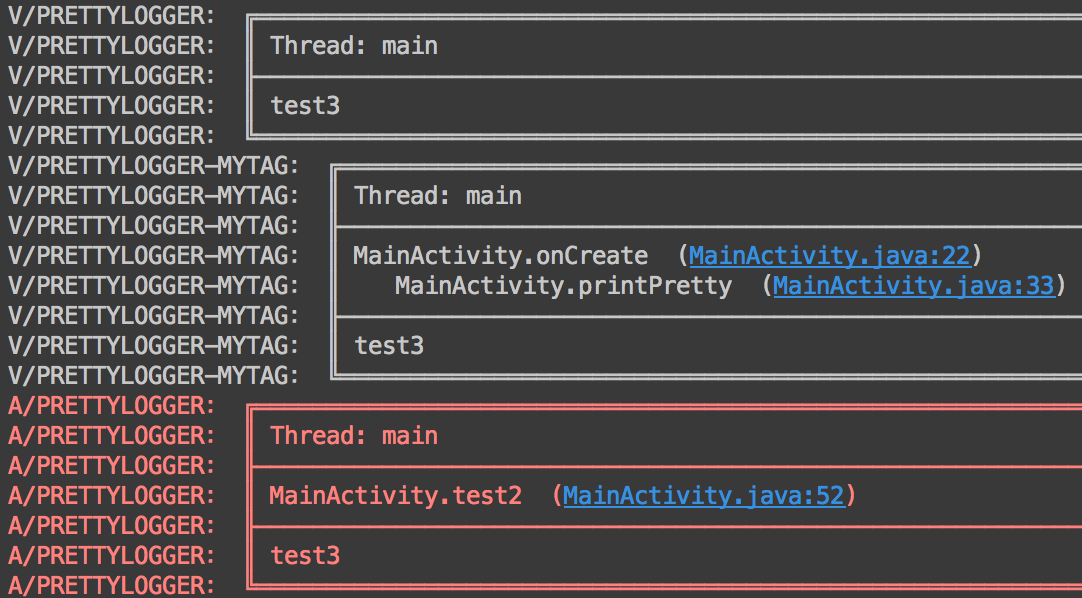
使用XLog样式后的输出:
PS:Logger的不美观其实是折衷的结果。美观必然会带来数据的冗余,但原始的log却又不足够清晰。Logger最终选择了一个轻量的log样式,既保证了清晰易辨认又不会带来过多的冗余信息。
支持超长的log信息
有时候网络的返回值是很长的,android.util.Log类是有最大长度限制的。为了解决这个问题,我们只需要判断这个字符串的长度,然后手动让其换行即可。
private static final int CHUNK_SIZE = 4000;
if (length <= CHUNK_SIZE) {
logContent(logType, tag, msg);
} else {
for (int i = 0; i < length; i += CHUNK_SIZE) {
int count = Math.min(length - i, CHUNK_SIZE);
//create a new String with system's default charset (which is UTF-8 for Android)
logContent(logType, tag, new String(bytes, i, count));
}
}自定义过滤规则
当崩溃出现的时候,有时候会将我们的log清屏,大大影响了我们的调试工作。所以我们可以在合适的时候利用Edit Filter Configuration这个功能。
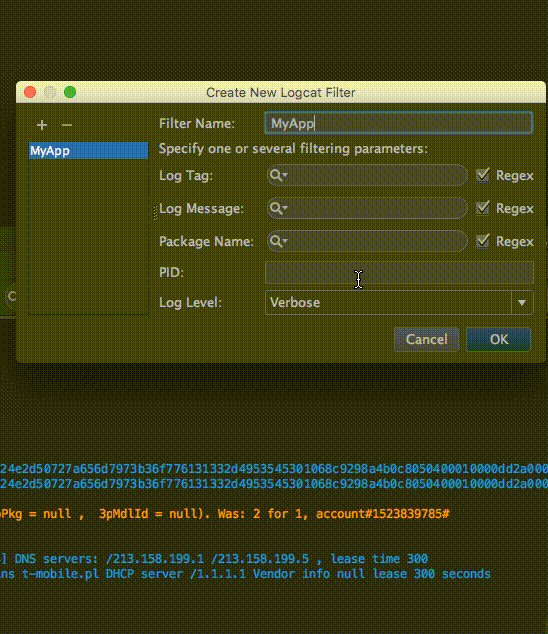
Edit Filter Configuration十分强大,并且支持正则。一般情况下使用Show only selected application就搞定了,是否使用Edit Filter Configuration就看你的具体场景了。
扩展篇
增加自动化或强制开关
要区分release和debug版本,可以用自带的BuildConfig.DEBUG变量,用这个也就可以控制是否显示log了。做个强制开关也很简单,在log初始化的最后判断强制开关是否打开,如果打开那么就覆盖之前的显示设置,直接显示log。转为代码就是这样:
public class BaseApplication extends Application {
// 定义是否是强制显示log的模式
protected static final boolean LOG = false;
@Override
public void onCreate() {
Logger.initialize(
new Settings()
.setLogPriority(BuildConfig.DEBUG ? Log.VERBOSE : Log.ASSERT)
);
// 如果是强制显示log,那么无论在什么模式下都显示log
if (LOG) {
Logger.getSettings().setLogPriority(Log.VERBOSE)
}
}
}以后要是需要做log的开关,那么只需要通过settings重设log级别即可:
Logger.getSettings().setLogPriority(Log.ASSERT); // close log解决log字符拼接的效率影响
多参数log信息应该利用占位符进行打印,尽量避免手动拼接字符串。这样好处是:在关闭log后就不会进行字符串的拼接工作了,减少log语句在release版本中的性能影响。
封装类.d("test %s%s", "v", 5); // test v5public static void d(@Nullable String info, Object... args) {
if (!mIsOpen) { // 如果把开关关闭了,自然就不进行字符串拼接
return;
}
Logger.d(info, args); // 内部会做String.format()
}这条来自朋友helder的建议,感谢!
通过混淆剔除log代码
如果你确定你的log代码在release版本中是无需存在的,那么我分享一个方案来帮你干掉它。
比如你的混淆配置文件叫proguard-rules.pro,里面有如下代码:
-assumenosideeffects class kale.log.LL { // 假设我们的log类是LL
public static *** d(...); // public static void d(...);
public static *** i(...);
public static *** v(...);
}然后在build.gradlez中启用混淆:
buildTypes {
release {
minifyEnabled true
shrinkResources true // 是否去除无效的资源文件
// 注意是用proguard-android-optimize.txt而不是proguard-android.txt
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
signingConfig signingConfigs.release
}
}要令assumenosideeffects生效,就需要开启混淆中的优化选项,而默认的proguard-android.txt是不会开启优化选项的。如果我们需要开启混淆的话,那么建议我们采用 proguard-android-optimize.txt。
proguard-android-optimize的全部内容如下:
# This is a configuration file for ProGuard.
# http://proguard.sourceforge.net/index.html#manual/usage.html
# Optimizations: If you don't want to optimize, use the
# proguard-android.txt configuration file instead of this one, which
# turns off the optimization flags. Adding optimization introduces
# certain risks, since for example not all optimizations performed by
# ProGuard works on all versions of Dalvik. The following flags turn
# off various optimizations known to have issues, but the list may not
# be complete or up to date. (The "arithmetic" optimization can be
# used if you are only targeting Android 2.0 or later.) Make sure you
# test thoroughly if you go this route.
-optimizations !code/simplification/arithmetic,!code/simplification/cast,!field/*,!class/merging/*
-optimizationpasses 5
-allowaccessmodification
-dontpreverify
# The remainder of this file is identical to the non-optimized version
# of the Proguard configuration file (except that the other file has
# flags to turn off optimization).
-dontusemixedcaseclassnames
-dontskipnonpubliclibraryclasses
-verbose
-keepattributes *Annotation*
-keep public class com.google.vending.licensing.ILicensingService
-keep public class com.android.vending.licensing.ILicensingService
# For native methods, see http://proguard.sourceforge.net/manual/examples.html#native
-keepclasseswithmembernames class * {
native <methods>;
}
# keep setters in Views so that animations can still work.
# see http://proguard.sourceforge.net/manual/examples.html#beans
-keepclassmembers public class * extends android.view.View {
void set*(***);
*** get*();
}
# We want to keep methods in Activity that could be used in the XML attribute onClick
-keepclassmembers class * extends android.app.Activity {
public void *(android.view.View);
}
# For enumeration classes, see http://proguard.sourceforge.net/manual/examples.html#enumerations
-keepclassmembers enum * {
public static **[] values();
public static ** valueOf(java.lang.String);
}
-keepclassmembers class * implements android.os.Parcelable {
public static final android.os.Parcelable$Creator CREATOR;
}
-keepclassmembers class **.R$* {
public static <fields>;
}
# The support library contains references to newer platform versions.
# Don't warn about those in case this app is linking against an older
# platform version. We know about them, and they are safe.
-dontwarn android.support.**
# Understand the @Keep support annotation.
-keep class android.support.annotation.Keep
-keep @android.support.annotation.Keep class * {*;}
-keepclasseswithmembers class * {
@android.support.annotation.Keep <methods>;
}
-keepclasseswithmembers class * {
@android.support.annotation.Keep <fields>;
}
-keepclasseswithmembers class * {
@android.support.annotation.Keep <init>(...);
}上面的注释就是采用优化方案来剔除log的风险点,所以要慎重使用!!!
这里也提到了一般推荐用proguard-android.txt来做混淆方案,如果你要是用了proguard-android-optimize.txt的话,请一定要测试充分在发布app。
将try-catch的信息通过log上传到Crashlytics
我们有时候为了防御某个未知原因的崩溃,经常会进行try-catch。这样虽然让其没崩溃,但是也隐藏了错误,以至于我们始终没有办法弄懂错误出现的原因。
我希望可以通过把catch的异常通过log系统分发到崩溃分析网站上(如:Crashlytics),这样既能防御问题,又可以帮助开发者知道崩溃产生的原因,方便以后针对性的进行处理。
代码参考自:blog.xmartlabs.com/2015/07/09/…
模拟
/**
* 这里模拟后端给客户端传值的情况。
*
* 这里的id来自外部输入,如果外部输入的值有问题,那么就可能崩溃。
* 但理论上是不会有数据异常的,为了不崩溃,这里加try-catch
*/
private void setRes(@StringRes int resId) {
TextView view = new TextView(this);
try {
view.setText(resId); // 如果出现了崩溃,那么就会调用崩溃处理机制
} catch (Exception e) {
// 防御了崩溃
e.printStackTrace();
// 把崩溃的异常和当前的上下文通过log系统分发
Logger.e(e, "res id = " + resId);
}
}接下来,我们建立一个crash分发tree:
public class CrashlyticsTree extends Timber.Tree {
@Override
protected void log(int priority, @Nullable String tag, @Nullable String message, @Nullable Throwable t) {
if (priority == Log.VERBOSE || priority == Log.DEBUG || priority == Log.INFO) {
// 只分发异常
return;
}
if (t == null && message != null) {
Crashlytics.logException(new Exception(message));
} else if (t != null && message != null) {
Crashlytics.logException(new Exception(message, t));
} else if (t != null) {
Crashlytics.logException(t);
}
}
}
// ---------------
if (!BuildConfig.DEBUG) { // for release
Logger.plant(new CrashlyticsTree()); // plant a tree
}一旦用户发生了崩溃,我们现在就可以通过Crashlytics进行分析,这样的错误会自动归档在Crashlytics报表的non-fatals中。通过这样的方式,可以方便我们排查出真正的问题,解决后就可以真正去掉这个try-catch了。
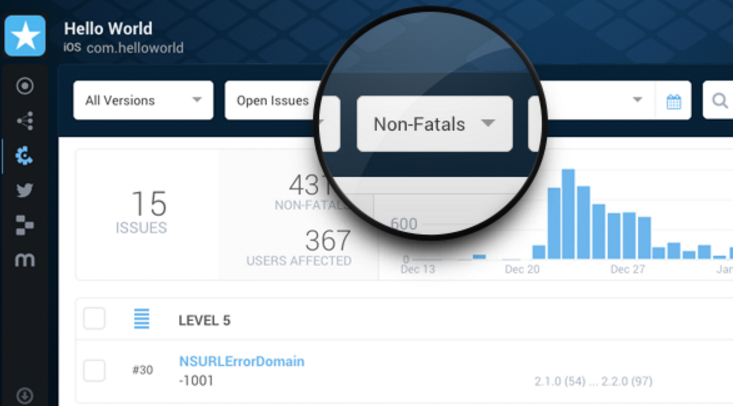
注意:
因为我们有些错误是不希望上传的,有些是希望上传的,所以我建议在使用Logger.e()的时候,通过你的包装类来做个处理(加参数或加方法),让使用者明确这个log将通向何方,不希望引起理解混乱。
增加log的扩展性
正如上面提到的,我们的log可能需要分发到不同的系统,这也是我采用timber的原因。我们除了将线上的错误分发到崩溃统计系统外,也可能要将log保存到sd卡或是做其他的处理,所以目前logger利用timber的tree实现了分发的功能。
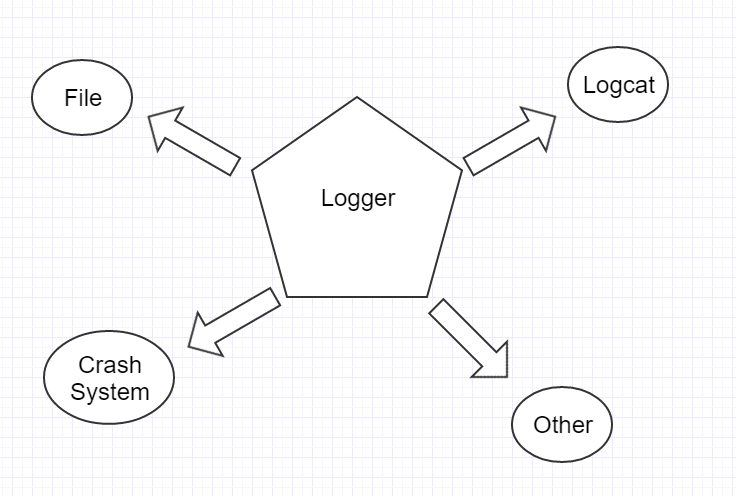
Logger内部的实现:
public static void plant(Timber.Tree tree) {
Timber.plant(tree);
}关于如何plant可以参考下Timber的具体代码。
通过自定义lint来规范log
大多数团队会定义自己的log类来进行log的打印,我们最好可以通过自定义的lint来在代码编写时防止开发者错用log类。
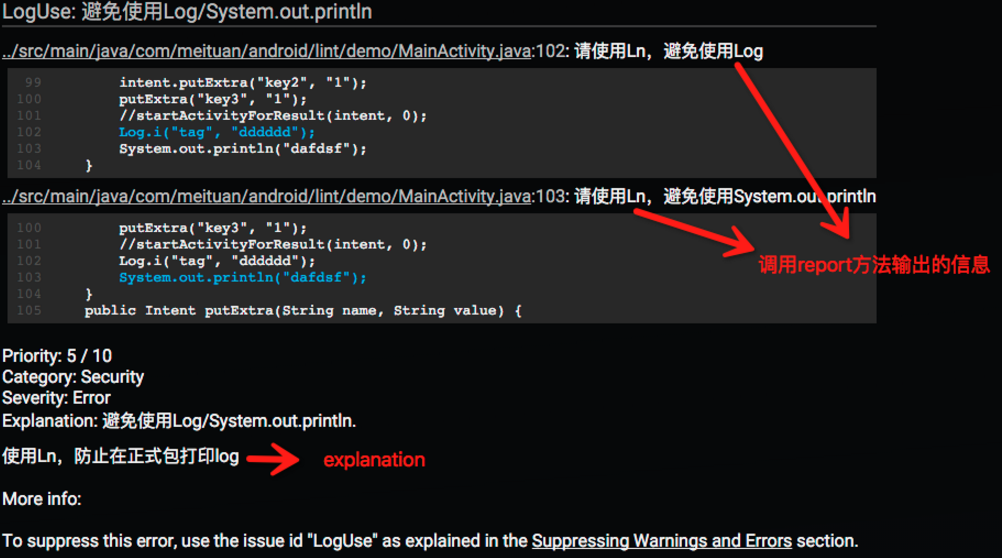
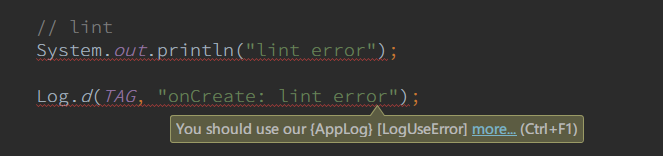
详细的内容可以参考:《Android自定义Lint实践》
利用IDEA的debug工具打log
上文中我就提到了可以利用as的调试模式来加速debug,下面分享下两个和log有关的经验。
public class MainActivity extends AppCompatActivity {
private static final String TAG = "MainActivity";
private int index = 0;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
Button button = (Button) findViewById(R.id.button);
button.setOnClickListener(v-> {
index = 123;
Log.d(TAG, "onClick: index = " + index);
index++;
}
);
}
}通过console热部署打印log信息
我通过debug工具,可以在任意位置打印出任意对象的值,通过这种方式就可以精准调试一些信息了。
下图是我让其在不中断运行的情况下打印index的值。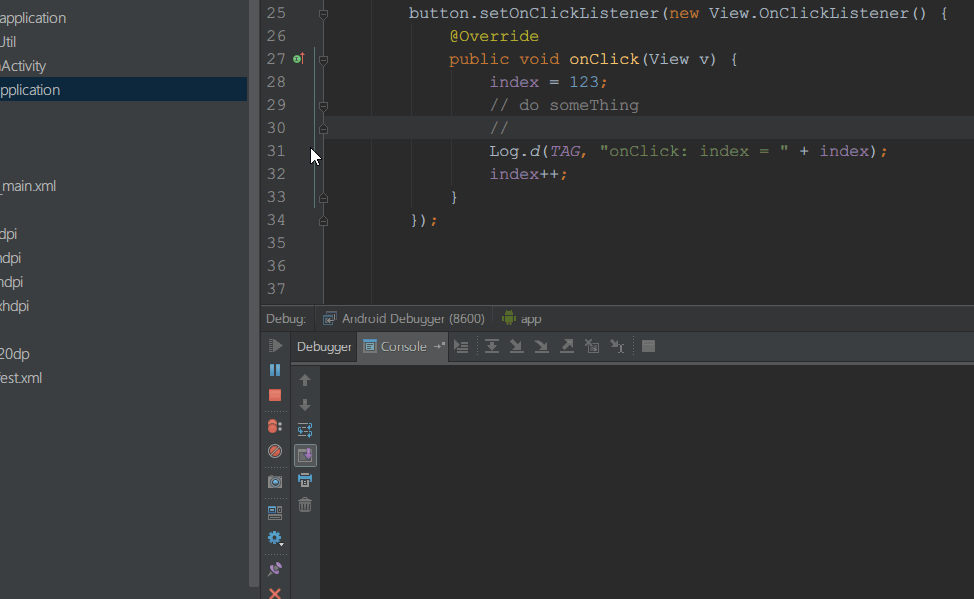
动态设置值
有时候某种分支需要在某个情况下才能走到,我可以利用debug的setValue(F12)方法动态设置值,比如我把下面的123改成了520,最终在终端打印出的信息也会变成520。整个过程对原本代码完全屏蔽,无入侵。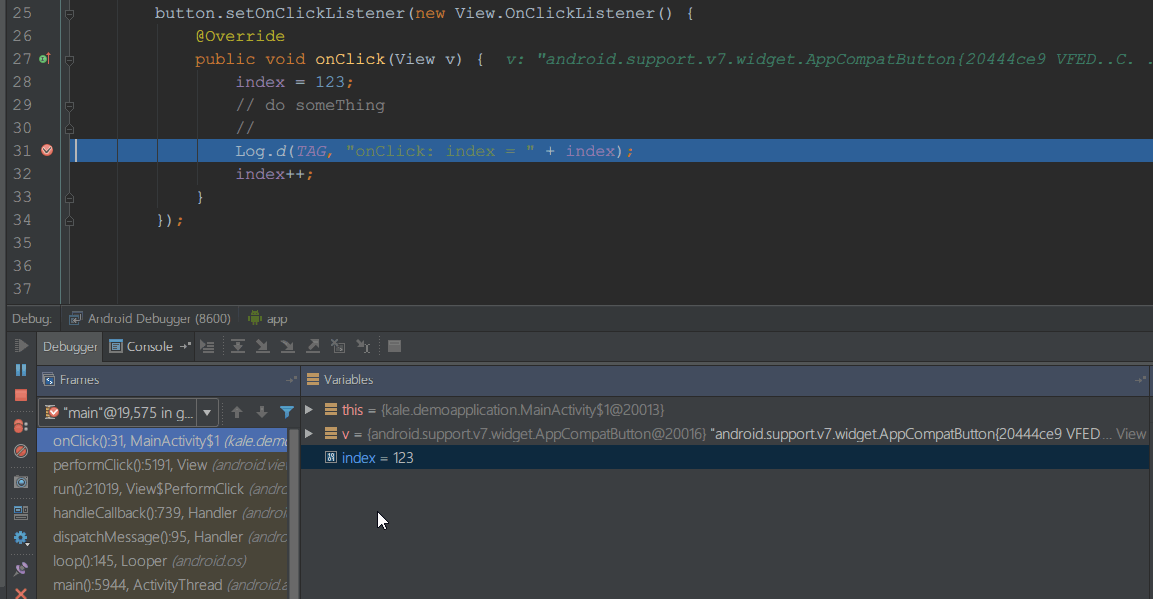
PS:更多的调试技巧可以查看Android-Best-Practices中的推荐的调试技巧的文章。
因地制宜的使用log
虽然我提出了上面的思路和方案,但我并不能确保可以满足所有的需求,我给出下面的思维流程,方便大家随机应变:
- 尽量用as的debug模式下的log系统,无入侵。不用写代码就能打log,十分方便。
- 如果真的要打log做调试,先用debug和error级别,提交代码时务必记得清除。
- 如果提交的代码中需要在某个关键点打log,或者要持续调试,可以用info以上的log。
- 在realse中用自己的log包装类的开关做处理,这样方便在公司内部测试时可以查看到log。
- 如果一些信息需要在用户版本中保留,优先考虑数据统计的方式进行关键点的打点。
- 如果真的要在发布出去的apk中带着log,只保留info级别以上的,不轻易把info级别之下的信息漏出去。
四、总结
我们可以看到即使一行代码的log都有很多点是可优化的,还明白了我们之前一直写的模板式代码是多么的枯燥乏味。
通过这篇文章,希望大家可以看到一个优化编码的思维过程,也希望大家去尝试下logger这个库。当然,我知道还是有很多人不喜欢,那么不妨提出更好的解决方案来一起讨论,不满意可以提issue。
要知道精品永远是个位数,而中庸的东西永远是层出不穷的。我希望大家多提意见齐心协力优化出一个精品,而不是花时间去在平庸的选项中做着选择难题。
五、尾声
在文章中我给出了通过idea的debug模式下打印log的方法,目的是即使你有了这个log库,但我仍旧希望你可以能找到更好的方法来达到调试的目的。拥有技巧,使用技巧,最终化为无形才是最高境界。相信我们的最终目的是一致的,那就是让开发越来越简便,越来越优雅~
最后说下我没直接用文章开头那几个库的原因,logger的库很漂亮,但是冗余行数过多,调试多行的数据就会受到信息干扰。timber的本身设计就是一个log的框架,打印是交给开发者自定义的,所以我将timber的框架和logger的美观实现进行了结合。这当然还要感谢logUtils的作者,让log支持了object类型。
有朋友问,你为什么不自己实现log框架,而是依赖于timber做呢,这样会不会太重?其实logger的1.1.6版本中,我确实是自己实现了所有的功能,没有依赖于任何库。当我看到了timber后,我发现我做的工作和这个库的重叠性太高了,而且它的设计也很值得学习。于是我直接依赖于它做了重构,我现在只关心log的美化和功能的扩展,log分发的事情就交给timber了。


参考文章:
