

在Android端,比较有名的网络请求框架是OkHttp和Retrofit,后者在网络请求又是依赖OkHttp的。所以说OkHttp是Android世界里最出名的框架也不为过,今天,我们就来认真分析一下这个框架,依照我务实的风格,这篇文章绝对不会是为了读源码而读源码。
HTTP简介
分析这个Http框架,我们就先从Http谈起,Http是互联网上应用最普遍的通讯协议。而所谓通讯协议,就是指通讯双方约定好传输数据的格式。所以要理解Http,只需要理解Http传输数据的格式,下面是Http数据传输双方的大致的数据格式。
上图列出的并不够详细,因为我们并不是想研究Http本身。
从上图可以看到,一个Http请求本身其实很简单。
从客户端的角度来看
- 装配Request(涉及到请求方法,url,cookie等等)
- Client端发送request请求
- 接收服务端返回的Response数据
是不是简单到令人发指?说起来这和大象装冰箱其实还蛮像的。
一个简单的OkHttp请求
结合上面的步骤,我们来看看在OkHttp框架是怎么完成简单一个网络请求的呢?
//构造Request
Request req=new Request.Builder()
.url(url)
.build();
//构造一个HttpClient
OkHttpClient client=new OkHttpClient();
//发送请求
client.newCall(req)
.enqueue(new Callback() {
//获得服务器返回的Response数据
@Override
public void onResponse(Call arg0, Response arg1) throws IOException {
}
@Override
public void onFailure(Call arg0, IOException arg1) {
// TODO Auto-generated method stub
}
});你瞧,这些步骤和我们预想的都是一样的,OKHttp为你封装了那些复杂,繁琐的东西,只给你你想要的和你需要的。
既然它把Http请求封装得如此简单,它的内部的设计是否也非常的严谨呢?
首先给出OkHttp框架的整个处理流程:
可以看到,OKHttp的框架中,构造Request和HttpClient两个过程其实还是很简单的,而发送请求的过程则显得十分复杂,当然也是最精彩的部分。
下面我们就按照客户端Http请求的流程来看看OKHttp框架的源码。
构造Request
public final class Request {
.......
.....
public static class Builder {
private HttpUrl url;
private String method;
private Headers.Builder headers;
private RequestBody body;
private Object tag;
}
}使用builder的方式,来插入请求的数据,构建Request,Builder模式相信大家非常熟悉了,所以这里仅仅给出它可构造的参数。
虽然说是构建Request,其实也言过其实,因为你能看到实际上这些数据是不足以构建一个合法的Request的,其他待补全的信息其实是OkHttp在后面某个环节帮你加上去,但至少,在开发者来看,第一步构建Request此时已经完成了。
构造OKHttpClient
public class OkHttpClient implements Cloneable, Call.Factory, WebSocketCall.Factory {
......
......
public static final class Builder {
Dispatcher dispatcher;
Proxy proxy;
List<Protocol> protocols;
List<ConnectionSpec> connectionSpecs;
final List<Interceptor> interceptors = new ArrayList<>();
final List<Interceptor> networkInterceptors = new ArrayList<>();
ProxySelector proxySelector;
CookieJar cookieJar;
Cache cache;
InternalCache internalCache;
SocketFactory socketFactory;
SSLSocketFactory sslSocketFactory;
CertificateChainCleaner certificateChainCleaner;
HostnameVerifier hostnameVerifier;
CertificatePinner certificatePinner;
Authenticator proxyAuthenticator;
Authenticator authenticator;
ConnectionPool connectionPool;
Dns dns;
boolean followSslRedirects;
boolean followRedirects;
boolean retryOnConnectionFailure;
int connectTimeout;
int readTimeout;
int writeTimeout;
}
....
....
@Override
public Call newCall(Request request) {
return new RealCall(this, request, false /* for web socket */);
}
....
....
}依然是Builder来构建OKHttpClient,值得注意的是OKHttpClient实现了 Call.Factory接口,创建一个RealCall类的实例(Call的实现类)。开头我们看到,在发送请求之前,需要调用newCall()方法,创建一个指向RealCall实现类的Call对象,实际上RealCall包装了Request和OKHttpClient这两个类的实例。使得后面的方法中可以很方便的使用这两者。
我们可以看看RealCall的上层接口Call:
public interface Call extends Cloneable {
Request request();
Response execute() throws IOException;
void enqueue(Callback responseCallback);
void cancel();
boolean isExecuted();
boolean isCanceled();
Call clone();
interface Factory {
Call newCall(Request request);
}
}基本上我们会用到的大部分操作都定义在这个接口里面了,可以说这个接口是OkHttp框架的操作核心。在构造完HttpClient和Request之后,我们只要持有Call对象的引用就可以操控请求了。
我们继续按照上面的流程图来查看代码,发送请求时,将请求丢入请求队列,即调用realCall.enqueue();
RealCall.java
@Override
public void enqueue(Callback responseCallback) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
//对代码做了一点结构上的转化,帮助阅读
Dispatcher dispatcher=client.dispatcher()
//从这里我们也能感觉到,我们应该全局维护一个OkHttpClient实例,
//因为每个实例都会带有一个请求队列,而我们只需要一个请求队列即可
dispatcher.enqueue(new AsyncCall(responseCallback));
/*
*这个AsyncCall类继承自Runnable
*AsyncCall(responseCallback)相当于构建了一个可运行的线程
*responseCallback就是我们期望的response的回调
*/
}我们可以进入Dispatcher这个分发器内部看看enqueue()方法的细节,再回头看看AsyncCall执行的内容。
Dispatcher.java
...
...
/**等待异步执行的队列 */
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
/** Running asynchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
/** Running synchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
...
...
synchronized void enqueue(AsyncCall call) {
//如果正在执行的请求小于设定值,
//并且请求同一个主机的request小于设定值
if (runningAsyncCalls.size() < maxRequests &&
runningCallsForHost(call) < maxRequestsPerHost) {
//添加到执行队列,开始执行请求
runningAsyncCalls.add(call);
//获得当前线程池,没有则创建一个
ExecutorService mExecutorService=executorService();
//执行线程
mExecutorService.execute(call);
} else {
//添加到等待队列中
readyAsyncCalls.add(call);
}
}在分发器中,它会根据情况决定把call加入请求队列还是等待队列,在请求队列中的话,就会在线程池中执行这个请求。
嗯,现在我们可以回头查看AsyncCall这个Runnable的实现类
RealCall.java
//它是RealCall的一个内部类
//NamedRunnable实现了Runnable接口,把run()方法封装成了execute()
final class AsyncCall extends NamedRunnable {
private final Callback responseCallback;
AsyncCall(Callback responseCallback) {
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
}
String host() {
return originalRequest.url().host();
}
Request request() {
return originalRequest;
}
RealCall get() {
return RealCall.this;
}
@Override
protected void execute() {
boolean signalledCallback = false;
try {
//一言不和就返回Response,那没说的,这个方法里面肯定执行了request请求
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}
}
...
...
//显然请求在这里发生
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
//包裹这request的chain
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
return chain.proceed(originalRequest);
}在这个getResponseWithInterceptorChain()方法中,我们看到了大量的Interceptor,根据上面的流程图,就意味着网络请求流程可能到了末尾了,也终于到了我介绍的重点了,因为这个Interceptor设计确实是精彩。
了解Interceptor之前,我们先来理一理,到目前为止,我们只有一个信息不全的Request,框架也没有做什么实质性的工作,与其说网络请求快到结尾了,不如说我们才刚刚开始,因为很多事情:为Request添加必要信息,request失败重连,缓存,获取Response等等这些什么都没做,也就是说,这所有的工作都交给了Interceptor,你能想象这有多复杂。。
Interceptor:你们这些辣鸡。
Interceptor详解
Interceptor是拦截者的意思,就是把Request请求或者Response回复做一些处理,而OkHttp通过一个“链条”Chain把所有的Interceptor串联在一起,保证所有的Interceptor一个接着一个执行。
这个设计突然之间就把问题分解了,在这种机制下,所有繁杂的事物都可以归类,每个Interceptor只执行一小类事物。这样,每个Interceptor只关注自己份内的事物,问题的复杂度一下子降低了几倍。而且这种插拔的设计,极大的提高了程序的可拓展性。
我特么怎么就没有想到过这种设计??
平复一下心情......
我们先来看看Interceptor接口:
public interface Interceptor {
//只有一个接口方法
Response intercept(Chain chain) throws IOException;
//Chain大概是链条的意思
interface Chain {
// Chain其实包装了一个Request请求
Request request();
//获得Response
Response proceed(Request request) throws IOException;
//获得当前网络连接
Connection connection();
}
}其实“链条”这个概念不是很容易理解Interceptor(拦截者),因此,我用一个更加生动的环形流水线生产的例子来帮助你在概念上完全理解Interceptor。
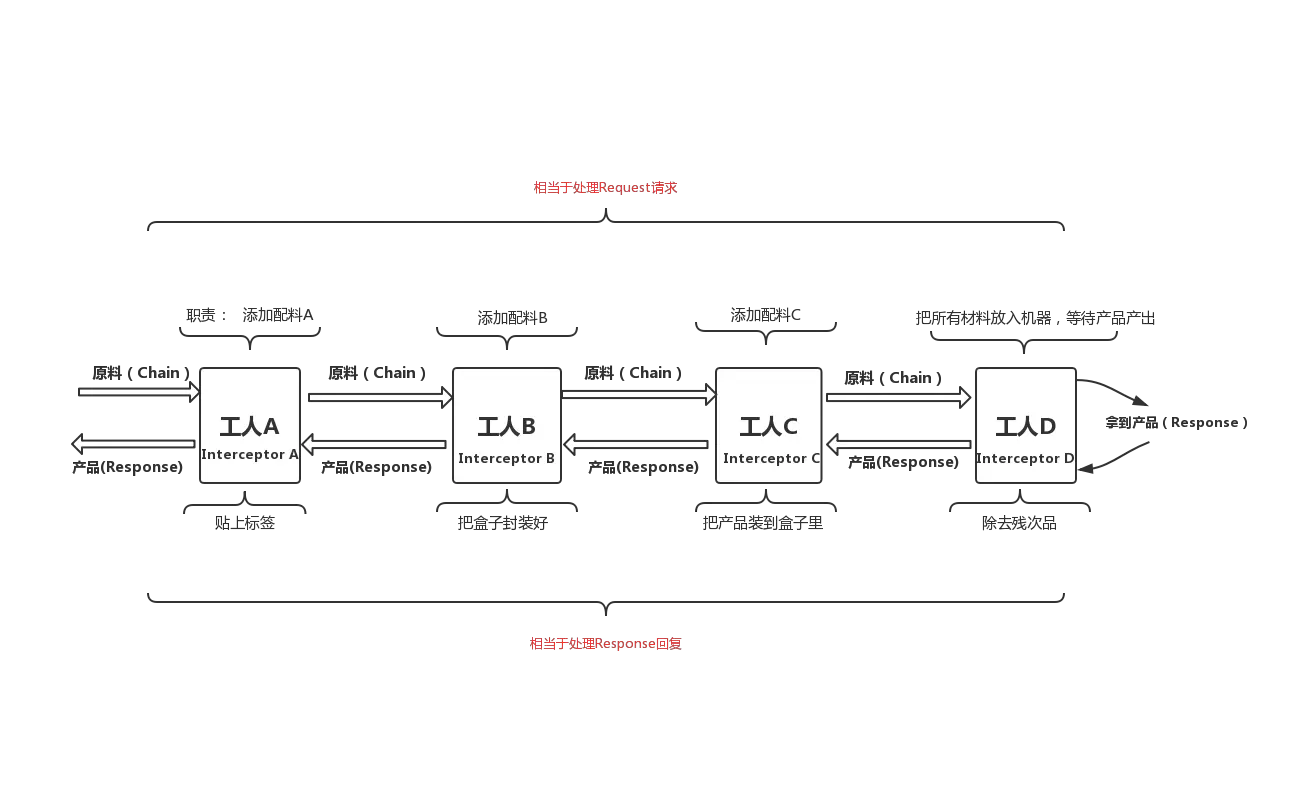
“包装了Request的Chain递归的从每个Interceptor手中走过去,最后请求网络得到的Response又会逆序的从每个Interceptor走回来,把Response返回到开发者手中”
我相信,通过这个例子,关于OkHttp的Interceptor以及它和Chain之间的关系在概念上应该能够理清楚了。
但是我仍然想讲讲每个Intercept的作用,以及在代码层面他们是如何依次被调用的。
那我们继续看看代码
Response getResponseWithInterceptorChain() throws IOException {
List<Interceptor> interceptors = new ArrayList<>();
//添加开发者应用层自定义的Interceptor
interceptors.addAll(client.interceptors());
//这个Interceptor是处理请求失败的重试,重定向
interceptors.add(retryAndFollowUpInterceptor);
//这个Interceptor工作是添加一些请求的头部或其他信息
//并对返回的Response做一些友好的处理(有一些信息你可能并不需要)
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//这个Interceptor的职责是判断缓存是否存在,读取缓存,更新缓存等等
interceptors.add(new CacheInterceptor(client.internalCache()));
//这个Interceptor的职责是建立客户端和服务器的连接
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
//添加开发者自定义的网络层拦截器
interceptors.addAll(client.networkInterceptors());
}
//这个Interceptor的职责是向服务器发送数据,
//并且接收服务器返回的Response
interceptors.add(new CallServerInterceptor(forWebSocket));
//一个包裹这request的chain
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
//把chain传递到第一个Interceptor手中
return chain.proceed(originalRequest);
}到这里,我们通过源码已经可以总结一些在开发中需要注意的问题了:
- Interceptor的执行的是顺序的,也就意味着当我们自己自定义Interceptor时是否应该注意添加的顺序呢?
- 在开发者自定义拦截器时,是有两种不同的拦截器可以自定义的。
接着,从上面最后两行代码讲起:
首先创建了一个指向RealInterceptorChain这个实现类的chain引用,然后调用了 proceed(request)方法。
RealInterceptorChain.java
public final class RealInterceptorChain implements Interceptor.Chain {
private final List<Interceptor> interceptors;
private final StreamAllocation streamAllocation;
private final HttpCodec httpCodec;
private final Connection connection;
private final int index;
private final Request request;
private int calls;
public RealInterceptorChain(List<Interceptor> interceptors, StreamAllocation streamAllocation,
HttpCodec httpCodec, Connection connection, int index, Request request) {
this.interceptors = interceptors;
this.connection = connection;
this.streamAllocation = streamAllocation;
this.httpCodec = httpCodec;
this.index = index;
this.request = request;
}
....
....
....
@Override
public Response proceed(Request request) throws IOException {
//直接调用了下面的proceed(.....)方法。
return proceed(request, streamAllocation, httpCodec, connection);
}
//这个方法用来获取list中下一个Interceptor,并调用它的intercept()方法
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
Connection connection) throws IOException {
if (index >= interceptors.size()) throw new AssertionError();
calls++;
....
....
....
// Call the next interceptor in the chain.
RealInterceptorChain next = new RealInterceptorChain(
interceptors, streamAllocation, httpCodec, connection, index + 1, request);
//从list中获取到第一个Interceptor
Interceptor interceptor = interceptors.get(index);
//然后调用这个Interceptor的intercept()方法,并等待返回Response
Response response = interceptor.intercept(next);
....
....
return response;
}从上文可知,如果没有开发者自定义的Interceptor时,首先调用的RetryAndFollowUpInterceptor,负责失败重连操作
RetryAndFollowUpInterceptor.java
...
...
//直接调用自身的intercept()方法
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
....
....
Response response = null;
boolean releaseConnection = true;
try {
//在这里通过继续调用RealInterceptorChain.proceed()这个方法
//在RealInterceptorChain的list中拿到下一个Interceptor
//然后继续调用Interceptor.intercept(),并等待返回Response
response = ((RealInterceptorChain) chain).proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
....
....
} catch (IOException e) {
....
....
} finally {
....
....
}
}
}
...
...嗯,到这里,Interceptor才算讲的差不多了,OKHttp也才算讲得差不多了,如果你想研究每个Interceptor的细节,欢迎自行阅读源码,现在在框架上,你不会再遇到什么难题了。这里篇幅太长,不能再继续讲了。
如果你还是好奇OKHttp到底是怎么发出请求?
我可以做一点简短的介绍:这个请求动作发生在CallServerInterceptor(也就是最后一个Interceptor)中,而且其中还涉及到Okio这个io框架,通过Okio封装了流的读写操作,可以更加方便,快速的访问、存储和处理数据。最终请求调用到了socket这个层次,然后获得Response。
总结
OKHttp中的这个Interceptor这个设计十分精彩,不仅分解了问题,降低了复杂度,还提高了拓展性,和可维护性,总之值得大家认真学习。
我记得有位前辈和我讲过,好的工程师不是代码写的快写的工整,而是代码的设计完美。很多时候,我们都在埋头写代码,却忘记了如何设计代码,如何在代码层面有效的分解难度,划分问题,即使在增加需求,项目的复杂度也保持不变,这是我们都应该思考的问题。
所有牛逼的工程师,都是一个牛逼的设计师。
共勉。
勘误
暂无
