

为什么要学习排序
一旦建立一个重要的数据库后,就可能根据某些需求对数据进行不同方式的排序:
比如闹钟功能,按时间远近排序出 闹钟列表,联系人列表按字母A-Z排序,城市列表按省市县的类别排序等等。
排序非常重要而且非常耗时,幸好 人们已经总结出一系列的排序供我们学习,使用。
如何排序?
NBA总决赛正在如火如荼的进行,老詹也正朝着他的第5个总亚军前进着。假设骑士队队员在运动场上排列成一队,如图所示,所有队员已经站好,准备热身,现在需要按身高从低到高 为队员们排队(最矮的站在左边),给他们照一张集体照,应该怎么排队呢?
在排序这件事情上,人与计算机程序相比有以下优势:我可以同时看到所有的队员,并且可以立刻找出最高的一个,毫不费力得测量和比较每一个人的身高。而且队员们不一定要固守特定的空间,他们可以相互推推攘攘就腾出了位置,还能互相前后站立,经过一些具体的调整,毫不费力地给队员们排好队

计算机程序员却不能像人这样通览所有的数据,它只能根据计算机的“比较”操作,在同一时间内对两个队员进行比较,算法 将”比较”的行为视为一个反复出现的问题,在人类看来是非常简单的事情,但程序算法 却只能一步一步得解决具体问题 和遵循一些简单的规则。
算法的本质就是拆分问题,按照最简单的规则,把问题拆分为一步一步交给计算机执行。
看上去这么简单,对吗:
重复这两步循环执行,直到全部有序为止。
不要轻视算法,因每种算法具体实现的细节有所不同。
BUBBLE 冒泡排序
冒泡排序算法运行起来非常慢,但概念上它是排序算法中最简单的,适合刚开始研究算法技术时的入门。
首先由一组无序的数字:
我录制了一段冒泡排序的执行过程(需要1-2秒的缓冲):
耐心观看完后,我们可以总结出冒泡排序的规则:
- 比较两个数字
- 如果左边的数字大,则交换两个数字的位置
- 向右移动一个位置,比较下两个数字
沿着这个顺序比较下去,一直比较到最右端,虽然没有把所有的数字排好序,但是,数字中最大的那一个已经排放在最右边了,这个是一轮比较下来 可以确定的结果。
下一轮,我们继续从最左边开始。
这也是这个算法被称为冒泡排序的原因:因为在算法执行的时候,最大的数据项 总是 “冒泡”到数组的顶端【数组的排列规则,从左到右0-N】。
效果这么棒,如何开始我们的第一行代码呢?
首先封装一个BUBLE数组对象
class ArrayBub
{
private long[] a;
private int nElems;
public ArrayBub(int max){
a =new long[max];
nElems=0;
}
public void insert(long value){
a[nElems] = value;
nElems++;
}
public void display(){
for(int j=0 ; j1;out--){
for(in=0;ina[in+1] ){
swap(in,in+1);
}
}
}
}
private void swap(int one,int two){
long temp =a[one]
a[one] = a[two];
a[two] = temp;
}
}
接着测试我们的代码:
class BubbleSortAPP{
public static void main(String args){
int maxSize=100; //数组的长度
ArrayBub arr; //声明我们封装的Bub数组对象
arr=new ArrayBub(maxSize); //初始化数组
arr.insert(77); //插入10个数据
arr.insert(22);
arr.insert(44);
arr.insert(66);
arr.insert(88);
arr.insert(11);
arr.insert(33);
arr.insert(77);
arr.insert(77);
arr.insert(77);
arr.display(); //展示数据
arr.bubbleSort(); //对数组中的数据 执行排序操作
arr.display(); //展示排序后的数据
} //end main()
}//end class BubbleSortAPP核心代码 bubbleSort()方法只有四行(大括号可以缩进):
for(out=nElems-1;out>1;out--){
for(in=0;ina[in+1] ){
swap(in,in+1);
}
}
}
这个算法的思路是要将最小的数据项放在数组的最开始(数组下标为0),并将最大的数据项放在ishuzu的最后(数组下标为nElems-1),外层循环的计数器out,从数组最后开始,即out=nElems-1,每经过一次循环out减1,下标大于out的数据项都已经排好序了,变量out在没完成一次内部循环(计数器为in)后就左移一位,因此算法就不再处理那些已经排好序的数据了。
内循环计数器in从数组的最开始算起,in=0,没弯沉过一次内部循环循环体加1,当它等于out时 结束一次循环,在内存for循环中,数组下标为 in 和in+1的两个数据项比较,如果下标为 in 的数据项大于下标为in+1的数据项,则交换两个数据项。
不变性
在许多算法中,有些条件在算法执行时,是不变的,这些条件称为不变性。认识不变性对理解算法是游泳的,在一定的情况下对调试也有用,可以反复得检查不变性是否为真,如果不是得话 就标记出错。
在上述的bubbleSort.java中,不变性是指 out 右边的所有数据项为有序,在算法的整个运行过程中,这个条件始终为真。(在第一轮排序开始前,尚未排序,而out开始时在数据项的最右边,它已经是最右了,没有数据项在out的右边)
冒泡排序的效率
通过 考察10个数据项,第一轮比较了9次第二轮比较了8次,以此类推 9+8+7+6+5+4+3+2+1=45
小学隔壁家的孩子,高斯同学就已经归纳出这种序列的求和公式:N*(N-1)/2 ;
再运用大学高等数学的 “等价无穷小”定理,在N无限大的情况下, 2和 -1可以忽略不计,从而推导出算法作了N²次比较,而交换次数是小于比较次数的,而且如果数据是随机的,那么大概有一半数据需要交换,交换的次数也是N²,所以我们认为冒泡排序的运行需要O(N²)时间级别,从我录制的gfit原理图来看,冒泡排序的速度是很慢的,
无论何时,只要看到循环嵌套在另一个循环里,就可以怀疑这个算法的运行时间为O(N²)级,
SELECT 选择排序
选择排序改进了冒泡排序,将必要的交换次数从O(N²)减少到O(N)。看上去非常棒了,不幸的时候比较次数仍保持为 O(N²),不要遗憾,选择排序仍然为大量的排序做出了一个非常重要的改进:
因为izhexie大量的记录 需要在内存中移动,这就使得交换的时间和比较的时间相比,交换的时间更为重要(一般来说,在Java语言中不是这种情况,Java中只是改变了引用位置,而内存中世纪对象的位置并没有发生改变)
理解一下选择排序的原理
一组数据,
选择排序的原理,
* 使用选择排序算法对老詹的队友们排序,*
在选择排序中,不再比较两个相邻的队员,因此,需要记录下某个指定队员的高;可以用记事本记下队员的身高,同时还需要准备好一条紫红色的毛巾(不是搞基)。
进行选择排序 就是把所有的队员扫描一遍,从中选择出最矮的一个队员,最矮的这个队员和站在队列最左端的队员交换位置,即占到0号位置,现在最左端的队员是有序的了,不再需要交换位置。注意,在这个算法中有序的队员都排在队列的最左边(数组中较小的下标值),而冒泡排序则是优先排列在队列的右边。
排序从最左边开始,记录本上写下最左端球员的身高,并且在他的脖子上挂上红色毛巾,于是开始用下一个球员的身高和记录本上记录的值比较,如果下一个球员更矮,则在本子上划掉第一个球员的身高,记录第二个队员的身高,同时把红色毛巾从第一个球员的脖子上拿下来,挂在第二个队员的脖子上,继续沿着队列走下去,
一轮下来,毛巾就会落在最矮的队员面前,接着,唯一拥有红毛巾的队员和队列最左边的队员交换位置,现在已经对一个队员排好序了,这期间做了N-1次比较,淡只进行了一次交换。
嗯,老詹对你的建议很满意。
选择排序的代码实现
class ArraySelect{
private long[] a;
private int nElems;
public ArraySelect(int max){
a = new long[max];
nElems = 0;
}
public void insert(long value){
a[nElems] = value;
nElems++;
}
public void display(){
for(int j=0; j
接着测试我们的选择排序吧:
class SelectSortApp{
public static void main(String[] args){
int maxSize = 100;
ArraySel arr;
arr = new ArraySel(maxSize)
arr.insert(88);
arr.insert(81);
arr.insert(33);
arr.insert(87);
arr.insert(38);
arr.insert(22);
arr.insert(11);
arr.insert(44);
arr.insert(77);
arr.insert(99);
arr.display();
arr.selectionSort();
arr.display();
}//end main()
}//end class
不变性
在此例程序中,下标小于或等于out的位置 数据项总是有序的。
选择排序的效率
此例当中,对于10个数据项,需要45次比较,而10个数据项只需要10次交换,扩大数量级,对于100个数据项,需要4950次比较,但只有100次交换,运用高等数学“等价无穷小”定理,N值越大,比较次数是主要的,所以结论是选择排序和冒泡排序一样 都是O(N²)的效率,但选择排序无疑更快,因为它交换的次数更少。
所以,不要小瞧选择排序。
INSERT 插入排序
在大多数情况下,插入排序比冒泡排序,选择排序要好的多。虽然插入排序仍然需要O(N²)的时间,但是在一般的情况下,它要比冒泡排序快一倍,比选择排序快一点,尽管它比冒泡排序算法和选择排序算法都更麻烦一些,但它也并不复杂,它经常被用在教复杂的排序算法的最后阶段,例如快速排序。
插入排序原理
一段数据:
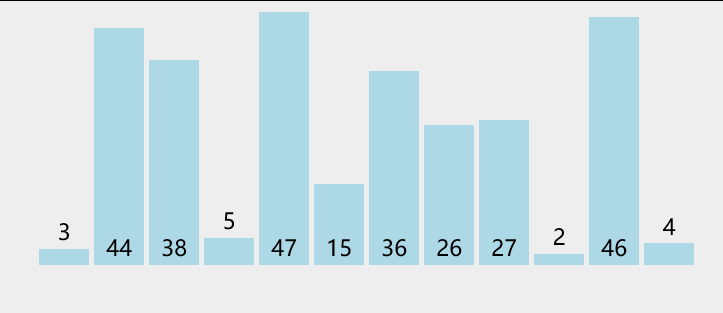
我录制了一段原理展示:
用插入排序提醒老詹吧
插入排序之前,队员随机站好。从排序过程的中间开始,可以更好地理解插入排序,这时队列已经排好了一半。
局部有序
此时,队友中间有一个作为标记的队员,还是用紫红色毛巾作标记吧,这个作为标记的队员的左边的所有队员已经是局部有序了。这意味着这一部分人之间是按顺序排列的:每个人比他左边的人都搞,然而这些队员在队列中最终的位置还没有确定,因为,当没有被排过序的队员要插入到他们中间的时候,他们的位置还要变动。
注意,局部有序在冒泡排序和选择排序中是不会出现的。在这两个算法中,一组数据项在某个时刻是完全有序的:在插入排序中,一组数据仅仅是局部有序的。
被标记的队员
作为标记的队员,称为“被标记的队员”,他和他右边所有的队员都是未排序的
如图:

下面价格要做的是在局部的 有序组中适当的位置 插入被标记的队员,然而要做到这一点,需要把部分已排序的队员右移腾出空间,为了提供移动所需的空间,就先让被标记的队员出列(在程序中,这个出列的行为,是该数据项被存储在一个临时变量中)
现在移动已经排过序的队员来腾出空间,将局部有序中最高的队员移动到原来被标记队员所在位置,次高的队员移动到原来最高的队员所在位置,以此类推。
局部有序的部分里多了一个队员,而未排序的部分少了一个队员,作为标记的球员,向右移动一个位置,所以他仍然放在未排序部分的最左边的队员勉强,重复这个过程,直到所有未排序的队员都被插入到局部有序队列中的合适位置。
插入排序的核心代码:
public void insertionSort(){
int in,out;
for(out=left+1;out0&&a[in-1]>=temp){
a[in] = a[in-1];
--in;
}
a[in] =temp;
}
}
插入排序的完整代码改日补上
在外层的for循环中,out变量从1开始,向右移动,它标记了未排序部分的最左端的数据,而在内层的while循环中,in变量从out变量开始,向左移动,直到temp变量小于 in 所指的数组数据项,或者它已经不能再往左移动,while 循环的每一轮循环都向右移动了一个已排序的数据项。
插入排序中的不变性
在每轮结束时,在标记的位置项插入后,比outer变量下标号小的数据项都是有序的
插入排序的效率(有趣)
这个算法需要多少次比较和复制呢?在第一轮排序中,它最多比较一次,在第二轮最多比较两次,以此类推
1+2+3+…+N-1=N*(N-1)/2 次比较;
复制的次数,大致等于比较的次数,然而,一次复制与一次交换的时间耗费不同,相对于 随机顺序的数据这个算法比冒泡排序快一倍,比选择排序略快,
在任意情况下,插入排序的时间复杂度也为O(N²)。
有趣的是
对于已经有序或者基本有序的数据来说,插入排序要好得多,当数据有序的时候,while循环的条件总是false吗所以它成为了外层循环中的一个简单语句,执行N-1此,算法运行只需要O(N)的时间。这对一个基本有序的文件进行排序是一个简单而有效的方法。
然而,对于逆序排列的数据,每次比较和移动都会执行,在这种情况下,插入排序 并不比冒泡排序快。
MERGE 归并排序
直接上手归并排序?NO!
我们首先得了解递归的知识:
1. 限于篇幅和时间,点击这里了解递归
2. 以后会自己写一篇递归相关的博文,敬请关注
感受归并排序
一组随机数据:
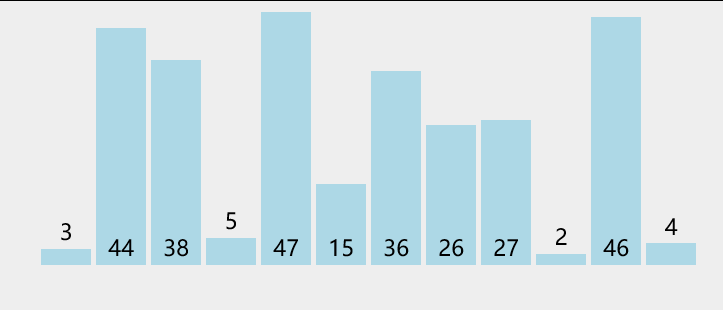
归并排序流程:
详解归并排序
1. 归并排序有那么厉害吗?
冒泡排序,插入排序和选择排序要用O(N²),而归并排序只要O(N*log
N)
如果数据项N=10000,那么N²就是100000000,而N*logN只是40000,如果为这么多数据排序,
选择归并排序的话需要40秒,
选择插入排序?需要将近28个小时!
2. 归并排序优点
容易实现,比快排容易理解
3. 归并排序的缺点
它需要在存储器中有另一个大小等于被排序的数据项 长度的数组,如果初始数组几乎占满整个存储器,那么归并排序不会执行,但是如果有足够的内存,归并排序是一个很好的选择。
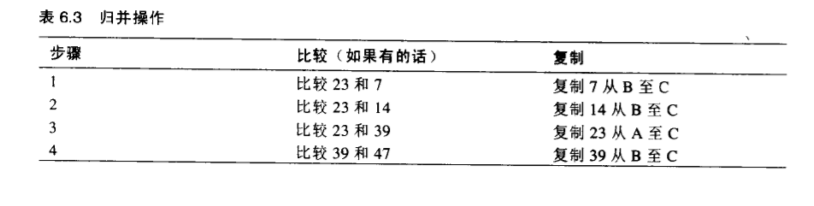
归并有两个有序数组
归并算法的中心 是归并两个 已经有序的数组,归并两个有序数组 A和B,就生成了第三个数组C,数组C包含数组A和B的所有数据项,并且使他们有序的排列在数组C中,
学习的步骤: 首先理解归并的过程,再去理解它是如何在排序中使用的。
假设有两个有序数组,不要求有相同的大小,假设数组A有4个数据,B有6个数据,它们被归并到数组C中,C初始化的时候就拥有10个存储空间
如图:
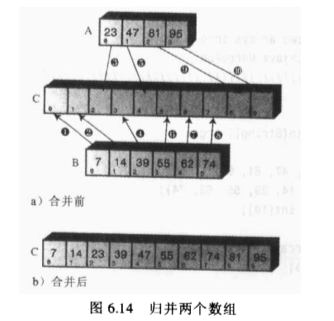
在这个图中,带圈的数组显示了把数组A和B中的数据项转移到数组C中的顺序
接着下图表示了必要的比较,由此来决定复制那个数据项到表C中,再每一次比较之后,较小的数据项被复制到数组A中

由于数组B在第八步以后是空的,所以不需要再去比较了,只要把数组A中所有剩余的数据项复制到数组C即可。
我们直接上代码 解释一下归并的代码:
注意,这只是理解归并排序的序曲,并不是归并的程序
class MergeApp{
public static void main(String[] args){
int[] arrayA = {23,47,81,95};
int[] arrayB = {7,14,39,55,62,74};
int[] arrayC = new int[10];
merge(arrayA,4,arrayB,6,arrayC);
display(arrayC,10);
}
public static void merge(int[] arrayA,int sizeA,
int[] arrayB,int sizeB,
int[] arrayC){
int aDex=0,bDex=0,cDex=0;
while(aDex
在main()中创建数组 arrayA,arrayB,和数组arrayC;然后调用merge()方法把数组A,B归并到数组C中。
merge()方法有三个while循环,第一个whie循环是沿着数组arrayA和arrayB走,比较它们的循环,并且复制它们中较小的数据项到arrayC。
第二个和第三while循环处理的是类似的情况,即,当两个数组arrayB,arrayA中任意一个为空,就把剩下的一个数组归并到arrayC中。
通过归并进行排序
归并排序的思想是把一个数组分成两半,排序每一半,然后用merge()方法把数组的两半归并成一个有序的数组。
那么问题来了,如何为每一部分排序呢?答案是递归:把每一半都分成两个四分之一,对每个四分之一部分排序,然后把 它们归并成一个有序的一半。
类似的,每一对八分之一 归并成一个有序的四分之一部分,每一对十六分之一部分归并成一个有序的八分之一部分,依次类推,反复地分割数组,直到得到的字数组只含有一个数据项。这就是归并的基本条件:假设只有一个数据项的数组是有序的。
前面已经看到,递归方法在每次调用自身方法的时候,通常某个参数的大小会减小,而且方法每次返回时,参数值又恢复到以前,在mergeSort()方法中,每一次这个方法调用自身的时候 都会被分成两部份,而且,每一次返回时都会把两个较小的数组合并成一个更大数组。
当mergeSort()发现两个只有一个数据项的数组时,它就返回,把这两个数据项归并到一个有两个数据项的有序数组中,每个生成的一对两个数据项的数组又被合并成一个有4个数据项的有序数组,这个过程一直持续下去,数组越来越大直到整个数组有序,当初始的数组大小 是二的乘方的时候,最容易看明白:
【归并越来越大的数组】
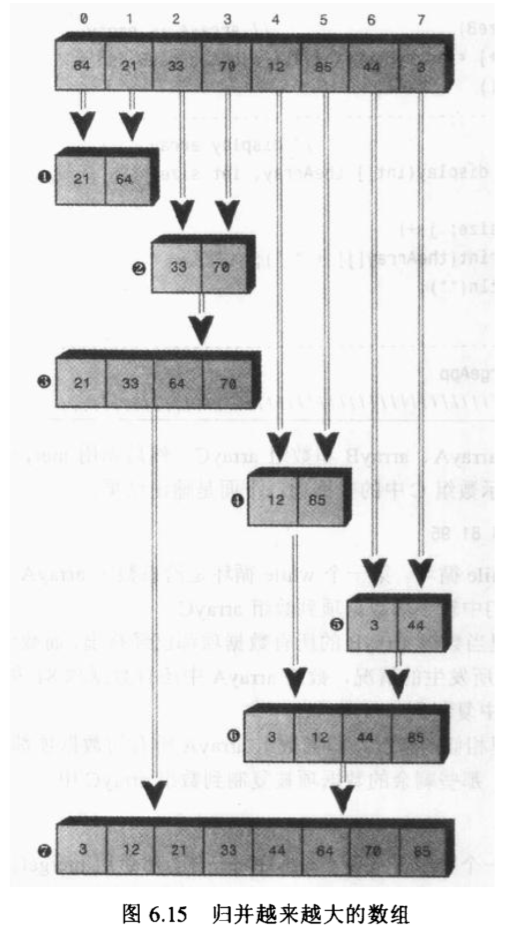
首先一定确保自己理解前面所讲的“归并”的概念。
从上往下看,整幅图就非常直白了,
当数组的小不是2的乘方,也容易理解 图:
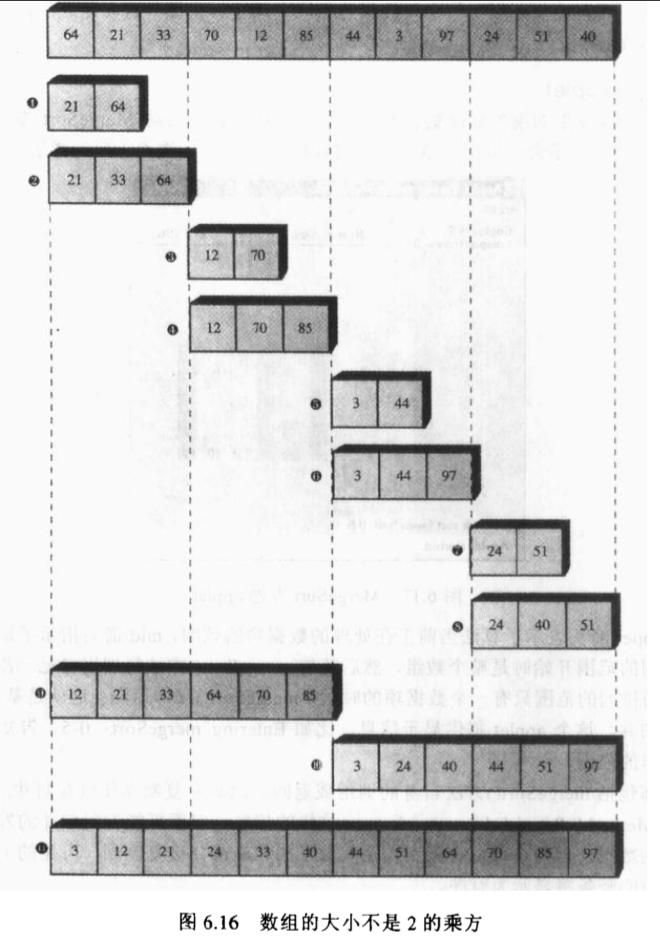
那么所有的这些子数组都存放在存储器的什么地方?
在这个算法中,创建了一个和初始数组一样大小的工作空间数组,这些子数组存储在这个工作空间数组中,也就是之前说的“原始数组中的子数组被复制到工作空间数组对应的空间上”。在每一次归并之后,工作数组的内容 就被复制回原来的数组中。
注意力集中
马上就会看到完整的mergeSort程序,首先,关掉手机,关掉音乐,屏蔽一切打扰,把注意力集中到执行归并排序的方法。下面就是它的程序代码:
private void recMergeSort(long[] workSpace,int lowerBound,
int upperBound){
if(lowerBound ==upperBound)
return;
else{
int mid=(lowerBound+upperBound)
recMergeSort(workSpace,lowerBound,mid);
recMergeSort(workSpace,mid+1,upperBoud);
merge(workSpace,lowerBound,mid+1,upperBound);
}
}end recMergeSort
正如上面看到的一样,除了基本条件外,这个方法只有四条语句,一句是计算中间位置的,还有两个递归,调用recMergeSort(每一个对应数组的一半),最后一句是merge(),用它来归并两个有序的部分。当这个范围只包含一个数组数据项(lowerBound==upperBound)的时候符合基本条件,立即返回。
在我们的mergeSort.java中,mergeSort实际上只用来创建数组workSpace[],然后调用递归的程序recMergeSort()来执行排序,workSpace数组的创建不放在recMergeSort()的原因?因为递归操作重复创建数组,效率太低。
下面显示完整的归并排序:
class DArray{
private long[] theArray;
private int nElems;
public DArray(int max){
theArray=new long[max];
nElems=0;
}
public void insert(long value){
theArray[nElems] =value;
nElems++;
}
public void display(){
for(int j=0;j
class MergeSortApp
{
public static void main(String[] args)
{
int maxSize=100; //定义数组的长度
DArray arr;
arr=new DArray(maxSize); //创建数组
arr.insert(94);
arr.insert(64);
arr.insert(33);
arr.insert(65);
arr.insert(65);
arr.insert(55);
arr.insert(77);
arr.insert(11);
arr.insert(38);
arr.insert(99);
arr.insert(25);
arr.insert(15);
arr.display();
arr.mergeSort();
arr.display();
}//end main();
}//end class MergeSortApp
如果在recMergeSort()方法中添加一些额外输出语句,就可以观察排序过程中的执行过程。请自行书写。
归并排序的效率
正如前面提到的那样归并排序的运行时间O(N*logN),
QUICK 快速排序
毫无疑问,快速排序是最流行的排序算法,在大多数情况下,快速排序都是最快的,执行时间为O(N*logN)级
先了解划分算法
划分是快速排序的根本机制,加上划分本身也是一个有用的操作,所以在讲解快速排序之前,我们先要了解划分算法。
划分数据就是把数据分为两组,使所有关键字大于特定值的数据在一组,使所有关键字小于特定值的数据项在另一组。
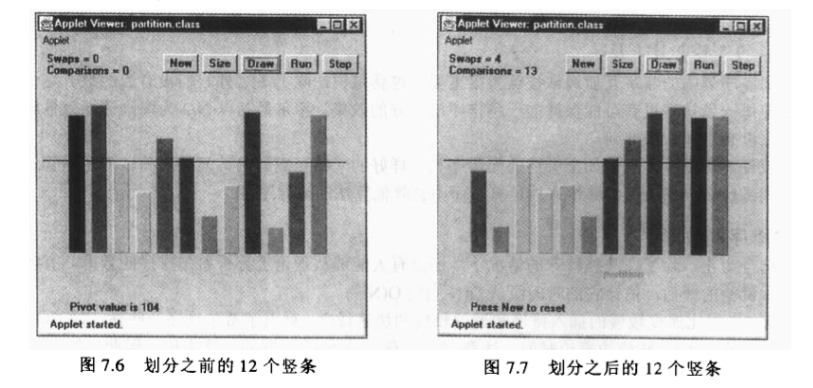
很容易想象数据的划分结果:比如将学生分成平均成绩高于3.5和低于3.5的两组,
另外,在算法中,通常称这个特定的值为枢纽pivot;
划分是如何执行的呢?
划分过程的partition.java
class ArrayPar{
private long[] theArray;
private int nElems;
public ArrayPar(int max){
theArray=new long[max];
nElems=0;
}
public void insert(long value){
theArray[nElems] =value;
nElems++;
}
public int size(){
return nElems;
}
public void display(){
System.out.print("A=");
for(int j=0;jleft &&theArray[--rightPtr]>pivot)
;
if(leftPtr>=rightPtr)
break;
else
swap(leftPtr,rightPtr);
}
return leftPtr;
}
public void swap(int dex1,int dex2)
{
long temp;
temp=theArray[dex1];
theArray[dex1]=theArray[dex2];
theArray[dex2]=temp;
}
}
接着在main函数中执行
class PartitionApp
{
public static void main(String[] args)
{
int maxSize =16;
ArrayPar arr;
arr=new ArrayPar(maxSize);
for(int j=0;j
划分算法
划分算法由两个指针开始工作,分别为leftPtr和rightPtr,这里的指针只是代表数据项,而不是C++中说的指针。
实际上,leftPtr初始化时是在第一个数据项的左边一位,rightPtr是在最后一个数据项的右边一位,这是因为zai它们工作之前,它们都要分别的加一和减一。
1. 停止和交换
当leftPtr遇到比枢纽小的数据项时,它继续右移,因为这个数据项的位置已经处在数组的正确的位置。
但是,当遇到比枢纽大的数据项时,它就停下来。
类似的,当rightPtr遇到大于枢纽的数据项,继续左移,当发现比枢纽小的数据项,它停下来。
两个内层的while循环,一个用于leftPtr,一个用于rightPtr。
只有当指针推出while循环的时候,它才停止移动,下面是一段代码,描述了一个不再适当位置的数据项,是如何被执行的:
while(theArray[++leftPtr]
;
while(theArray[++rightPtr]>pivot)
;
swap(leftPtr,rightPtr);
第一个while循环发现比枢纽大的数据项时推出,第二个循环在发现比枢纽小的数据项时推出。当这两个循环都推出之后,leftPtr,和rightPtr,指针都指向两个错误位置的数据项,所以要交换位置。
ok,似乎明白了点什么。
当两个指针相遇的时候,整个数组划分完毕,breat跳出!
2. 处理异常数据
为什么会发生异常?
如果所有的数据都小于枢纽,leftPtr变量将会便利整个数组,徒劳地寻找大于数据的数据项,然后跑出数组的最右端,产生数组越界异常。类似的情况也会发生在rightPtr上。
为了避免数组越界异常,
要在第一个循环中加上leftPtr
while(theArray[++leftPtr]pivot)
;
while循环中的代码相当精巧,
3. 划分算法的效率
划分算法的运行时间为O(N)
快速排序
1. 基本的快速排序算法
public void recQuickSort(int left,int right)
{
if(right-left<=0)
return;
esle
{
int partition=partitionIt(left,right);
recQuickSort(left,partition-1);
recQuickSort(partition+1,right);
}
}
正如大家所看,有三个基本步骤:
1. 把数组或者子数组划分成左边和右边
2. 调用自身对左边的一组排序
3. 调用自身对右边的一组排序。
每一次划分,所有左边的子数组的数据项都小于右边字数组的数据项,只要对左边数组和右边数组分别排序,整个数组就是有序的了。
如何对子数组进行排序呢? 通过递归调用排序算法自身就可以。
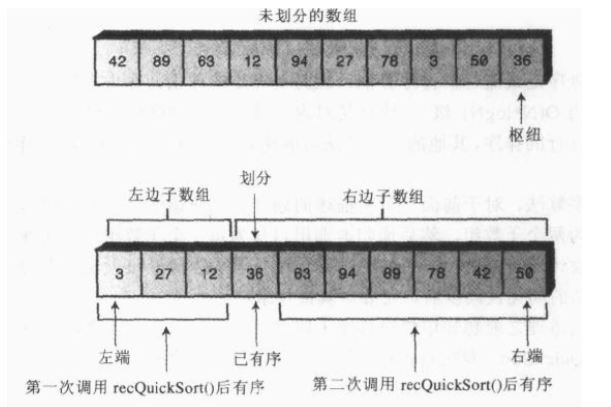
如果不是理想状态,数组包含两个或者更多的数据项,算法就需要调用partitionIt()方法对这个数组进行划分。方法返回枢纽的下标值,它指向右边较大的 子数组最左端的数据项,划分标记给 出两个子数组
如图所示:
2. 快速排序性能极差的情况:性能为O(N²)
对100个逆序的数据排序,会发现数据极其缓慢,而且需要划分更多更大的数组,这是为什么?
问题出在枢纽的选择上。理想状态下,应该选择数据项中的中值 作为枢纽,也就是说,应该有一半的数据项大于枢纽,一半的数据项小于枢纽,这会使数组被划分成两个大小相等子数组。可是如果没有选择好枢纽,那么快排的结果,就是划分为一大一小两个子数组进行排序,这样会降低算法的效率,因为较大的子数组要被划分更多次。
极端情况是,逆序排列的数据,一个子数组只有一个数据项,另一个字数组含有N-1个数据项,而且对于N-1的分割,所有的子数组都是1 和X-1的结果,很明显,划分所带来的好处没有了,算法的效率降低到O(N²)
快排以O(N²)运行的时候,除了慢还有另外一个潜在问题,当划分的次数增加,递归方法的调用也增加了,每一次调用都在申请工作栈,极端情况,可以能回内存溢出,导致程序挂掉。
所以,选择一个恰当的枢纽值,是实现快速排序的重点。
3. 三数取中法
人们已经设计出很多更好的枢纽选择方法,方法都是为了避免枢纽选择最大或者最小的值。
有一种这种的方法,我翻译为“三数取中法”(median-of-three) 如图:
三数取中法除了选择枢纽更为有效之外,还有一个额外的好处:可以在第二个内部while循环中取消rightPtr>left的测试,略微提高了算法的执行速度。
你心里一定很疑惑,这是怎样实现的呢?
因为在选择的过程中使用三数取中的方法不仅选择了枢纽,而且还对三个数据进行了排序,当三个数据项已经排好序,并且已经选择中值数据项作为枢纽后,此时就可以保证数组最左端的数据项小于等于枢纽,最右端的数据项大于等于枢纽,
三数取中法的另一个好处就是,对左端,中间,以及右端的数据排序之后,划分过程就不再考虑这三个数据项了,划分可以从left+1和right-1开始,因为left和right已经被有效的划分了。
不理解划分? 请倒回去看划分算法部分
这样,三数取中的划分方法不但避免了 执行效率低至O(N²)的可能,而且也提高了划分算法内部循环的执行速度。
完整的快速排序代码:
class ArrayIns
{
private long[] theArray;
private int nElems;
public ArrayIns(int max)
{
theArray=new ArrayIns(max);
nElems=0;
}
public void insert(long value)
{
theArray[nElesm]=value;
nElems++;
}
public void display()
{
System.out.print("A=");
for(int j=0;jtheArray[center])
swap(left,center);
if(theArray[left]>theArray[right])
swap(left,right);
if(theArray[center]>theArray[right])
swap(center,right);
swap(center,right-1);
return theArray(right-1);
}
public void swap(int dex1,int dex2)
{
long temp;
temp=theArray[dex1];
theArray[dex1]=theArray[dex2];
theArray[dex2]=temp;
}
public int partitionIt(int left,int right,long pivot)
{
int leftPtr=left;
int rightPtr=right-1;
while(true)
{
while(theArray[++leftPtr]pivot)
;
if(leftPtr>=rightPtr)
break;
else
swap(leftPtr,rightPtr);
}
swap(leftPtr,right-1);
return leftPtr;
}
public void manualSort(inr left,int right)
{
int size=right-left+1;
if(size<=1)
return;
if(size==2)
{
if(theArray[left]>theArray[right])
swap(left,right);
return
}else
{
if(theArray[left]>theArray[right-1])
swap(left,right-1);
if(theArray[left]>theArray[right])
swap(left,right);
if(theArray[right-1]>theArray[right])
swap(right-1,right);
}
}
}
接着我们在main函数中执行
class QuickSortApp
{
public static void main(String args)
{
int maxSize=16;
ArrayIns arr;
arr=new ArrayIns(maxSize);
for(int j=0;j
用插入排序取代三数取中法
如果使用三数取中法,则必须遵循快速排序中数据不能执行少于等于三个数据的规则,但这显然不是最好的划分方法。
好在我们还有插入排序:
处理小划分的另一个选择是使用插入排序,不用再去限制3,可以把界限定位10,20,或者任意数字。实验不同的枢纽点来提高执行效率。在这种算法下,最好的枢纽值取决于计算机,操作系统,编译器等,Knuth建议这种情况下的枢纽使用9。
class ArrayIns
{
private long[] theArray;
private int nElems;
public ArrayIns(int max)
{
theArray=new ArrayIns(max);
nElems=0;
}
public void insert(long value)
{
theArray[nElesm]=value;
nElems++;
}
public void display()
{
System.out.print("A=");
for(int j=0;jtheArray[center])
swap(left,center);
if(theArray[left]>theArray[right])
swap(left,right);
if(theArray[center]>theArray[right])
swap(center,right);
swap(center,right-1);
return theArray(right-1);
}
public void swap(int dex1,int dex2)
{
long temp;
temp=theArray[dex1];
theArray[dex1]=theArray[dex2];
theArray[dex2]=temp;
}
public int partitionIt(int left,int right,long pivot)
{
int leftPtr=left;
int rightPtr=right-1;
while(true)
{
while(theArray[++leftPtr]pivot)
;
if(leftPtr>=rightPtr)
break;
else
swap(leftPtr,rightPtr);
}
swap(leftPtr,right-1);
return leftPtr;
}
public void insertionSort(){
int in,out;
for(out=left+1;out0&&theArray[in-1]>=temp)
{
theArray[in] = a[in-1];
--in;
}
theArray[in] =temp;
}
}
}
class Quick2SortApp
{
public static void main(String args)
{
int maxSize=16;
ArrayIns arr;
arr=new ArrayIns(maxSize);
for(int j=0;j
这个特别的算法中,对小的子数组使用插入排序被证实为最快的方法,但不绝对比三数取中的枢纽法 快,总的来说没有明显的节省时间。
很多专家还提倡使用:
对数组整个使用快速排序,不考虑界限划分的排序。当快速排序结束时,数组基本有序,然后对整个数组进行插入排序,插入排序对基本有序的数组 执行效率高。
代码有待勘察,改日补上
快速排序的效率
快速排序的时间复杂度为O(N*logN)
参考并感谢
