

掘金译文地址《Twitch 是如何使用 PostgreSQL 的》,欢迎参加「掘金翻译计划」,翻译优质的技术文章。
Twitch has approximately 125 database hosts serving OLTP workloads in production, usually as part of a cluster. Approximately 4% run MySQL, 2% run Amazon Aurora, and the rest run PostgreSQL. We manage the provisioning, system image, replication and backup of several of the databases though most new clusters are RDS for PostgreSQL.
The most interesting cluster we manage is the original central database dating back to the origins of Twitch. In aggregate, that cluster averages over 300,000 transactions per second. We build and maintain our own specialized infrastructure to keep this stable, responsive, and capable of dealing with the varied use cases it supports.
We employ a multi-region topology, elastic cluster capacity provisioning, strategies for protection against buggy clients, fast master node failover, and zero down time credential rotation.
Topology
Up until late 2015, the entire cluster was running on hardware we owned in our primary datacenter along with the website and all other clients. Lured by the seductive ease of provisioning in AWS, the website was migrated. Since the i2.8xlarge instances in AWS are similar to our own hardware instances and are quick and easy to provision compared to hosts in our datacenter, and to keep write latency down, we soon migrated the master host and the primary read replica set into AWS.
In order to ease planned or emergency failover, there is a hot spare in another availability zone. Since migrating to AWS we’ve done a few planned failover events for things like system image upgrades and all of them were thankfully uneventful.
We wanted to be able to elastically provision read capacity so all read replicas are in an Auto Scaling Group (ASG) with a launch configuration and cloud-init which automatically joins the cluster. We built a small health check HTTP service which runs on the same host as the database which only returns a healthy status when the replica is available for reads and considered to not be experiencing excessive load. The ASG has an Elastic Load Balancer (ELB) attached which uses that health check to ensure it will not route queries to a host which is not ready. Clients which cannot use the ELB use a local HAProxy which routes to the set of available AWS replicas.
We still have a handful of client applications which remain in our datacenter. Most do not write data and are not sensitive to replication lag so we set up a bank of read replicas on our own hardware to reduce query latency inside that datacenter. In order to reduce bandwidth consumed by replicating from AWS into our datacenter, there are only two replication streams into hosts which are not used as a read replica. From there, the replication cascades from one of those replication relays to the live read replicas in that datacenter. The second host is a hot spare to that replication relay in case that host fails. This lets clients have a millisecond query come back in a millisecond rather than a millisecond plus a 30ms round trip between datacenters.
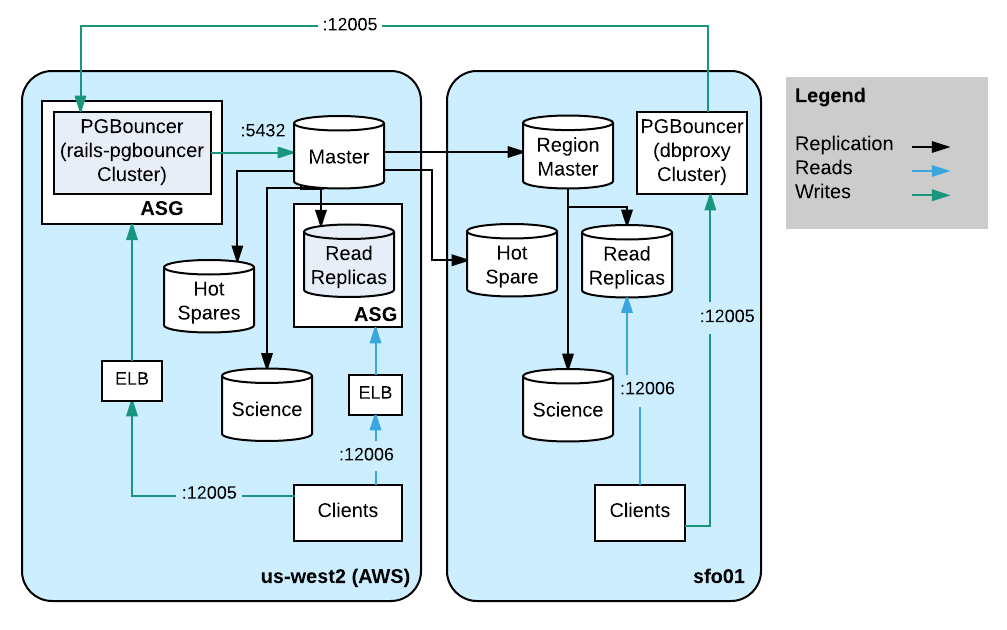
Data scientists, analysts, engineers and others here have occasional needs for ad-hoc queries. For example, to generate a histogram of vod uploads, each datacenter has a host which is not part of the live read set. Since they are not part of the read replicas, we can let them run expensive ad-hoc queries and reports which are not sensitive to somewhat stale data. We set `hot_standby_feedback = off` and `max_standby_streaming_delay = 6h` in postgresql.conf on these special nodes so that the replication source isn’t burdened and replication will not cancel queries because of multi-version concurrency control (MVCC). This idiom has been so useful we’ve repeated it in some of the newer database clusters.
Roles
Credentials
Each team has a set of credentials into the database. The credentials have some overlap in which relations and columns have read and write access grants. We need zero downtime credential rotation and want to reduce the chance of errors when granting read and write access to those roles. To handle this we create 3 roles, one as a kind of ‘group’ role which cannot login and two more roles which inherit permissions from the group role. Other than during a credential rotation, only one of the concrete roles is allowed to log in. For example, creating a new role could look like:
create role team nologin; -- create a team role
create role team_01 with encrypted password ‘md5…’; -- current active role
create role team_02 with encrypted password ‘md5…’ nologin; -- disabled role
grant team to team_01; -- gives team_01 the same rights as team
grant team to team_02; -- gives team_02 the same rights as teamFor zero downtime credential rotation, enable the next role, e.g.:
alter role team_02 login;Then, distribute that role and its password to all clients and finally disable the old role with:
alter role team_01 nologin;Expensive Query Protection
Over the years, we frequently shipped code which ran expensive queries, for example an aggregation or a sequence scan. When an expensive query ships the back-ends will start taking all CPU time which leads to a backup of clients and queries stop running in a timely manner or failing because of MVCC rules in a replica. To address this, we set a time limit per statement with an appropriate `statement_timeout` for every role.
Unlike grants, these parameters are not inherited so the value must be set for every active role.
alter user team_01 set statement_timeout = ‘1s’;
alter user team_02 set statement_timeout = ‘1s’;We can still put too much load on the cluster but with this setting, but this usually gives us enough capacity to so that unrelated queries will get a slow response rather than no response at all.
PGBouncer
Since each team needs access to the database, there are a lot of roles. The roles compete for a finite number of available PostgreSQL processes which means a bug in one client could block access to the other clients by consuming all available connections. To prevent this, we use PGBouncer to provide a virtual schema name which aliases the database schema. Each virtual schema in PGBouncer is given a limited number of connections and when clients connect to their virtual schema, they can only exhaust their own connection pool. For example, in the PGBouncer configuration file, you can find:
[databases]
site_sitedb = dbname=sitedb host=127.0.0.1 pool_size=70 port=5432
sso_sitedb = dbname=sitedb host=127.0.0.1 pool_size=8 port=5432Which gives the site role 70 connections into sitedb and the sso service gets 8 connections.
PGBouncer is running in transaction mode so that the back-end is freed as quickly as possible for another client. Go’s lib/pq uses anonymous prepared statements for queries with parameters which does not work with a default PGBouncer — the back-end will swap out between the prepare and execution. To address this, we have a fork of PGBouncer which detects an anonymous prepare and holds the back-end until the parameters are provided for execution. A recent version of github.com/lib/pq now has a way to use mainline PGBouncer by specifying `binary_parameters=yes` in the connection string. The `binary_parameters` argument is consumed by lib/pq and works by avoiding a second round trip with parameterized queries. Our client applications are being ported to use this instead of our fork.
Routing
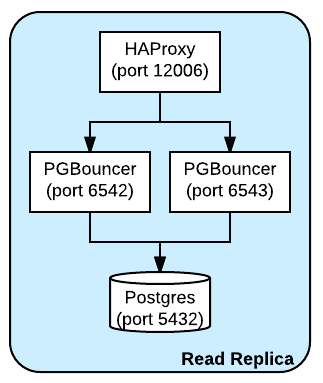
At one point, CPU was hitting 100% running PGBouncer as a single threaded application which causes connections to stall. We have a specialized initialization and configuration which runs 2 processes, each listening to a different port and then directing traffic to the PostgreSQL back-end. With 2 processes splitting the load, the CPU is still hot though no longer hits 100%. On the same host as every PGBouncer, HAProxy is also running and listening on a single port, proxying to both PGBouncer processes. This provides a single client endpoint per host and simplifies configuration.
For the read replicas, PGBouncer and HAProxy are running on the same host as PostgreSQL proxying to the localhost PostgreSQL.
There is a small cluster of hosts running a similar PGBouncer configuration except they all point to the master database host. The PGBouncer cluster is in an ASG which is easy to scale up and down, and an ELB points to members of the ASG which again has HAProxy listening on a single port and proxying to the PGBouncer processes running on localhost. With this setup, promoting a new master is a matter of changing this cluster’s configuration and restarting the PGBouncers. This makes master promotion essentially transparent to the clients other than a brief window of failing writes.

It’s better for clients to talk to a PGBouncer which is as close as possible to the back-end. At one point, there were two PGBouncer clusters in front of the master — one in AWS and one in our datacenter. There were significant performance issues with the protocol-aware proxy when the cluster was in a different region than the master, so we reverted to using HAProxy to communicate between the regions and only rely on the closer PGBouncer cluster.
Problems
The scheme described so far has been working well for Twitch though there are some problems.
MVCC
The multi version concurrency control (MVCC) story on PostgreSQL is a little weak. Because the way that storage works, and perhaps other reasons, replicas must exactly match the master on disk. We used to see a lot of errors with the message, `canceling statement due to conflict with recovery`, rather than getting a result set. This has not been much of an issue since aggressively limiting every role’s `statement_timeout` and setting `hot_standby_feedback = on` in the configuration.
Connections
The value of postgresql.conf’s `max_connections` is encoded in the replication stream so you cannot, for example, stream from a master with a higher max_connections value than a replica. In order to raise the value in a cluster, you have to set it for every replica (which requires a restart) and then do a fail-over to a master with the new value for `max_connections`.
Major Upgrades
Performing a PostgreSQL upgrade across major versions, 9.4 to 9.5 for example, requires a long downtime event or a logical replication stream rather than the built-in write ahead log (WAL) streaming if you have significant amount of data or load. Using a dump and load can take significant time just to move the bits. There is `pg_upgrade` which can either go into a potentially long downtime event or a quick downtime event and amortize the cost by reducing capacity until the storage is completely re-written.
In our last major upgrade, we built two parallel clusters, installed slony for logical replication, copied the data to the new cluster and kept the logical work queue for replay. There were weeks of planning and setup and copy took about a day. The downtime itself was only a minute though the work leading up to the event was time consuming.
Conclusion
Twitch uses many different technologies for our production data storage and analysis.
- We use Redis for cache and disk persisted key-value data.
- We have many DynamoDB tables for high write load data use cases.
- We stream data to Kinesis for migrating between databases.
- We store to S3 for event streams.
- We load to Redshift for data analytics.
- And when it comes to our OLTP use cases, we rely on PostgreSQL.
We do this because we have found PostgreSQL to be a performant and reliable SQL ACID relational database.
Twitch is hiring! Learn about life at Twitch and check out our open roles here.
