

Introduction
本文收录在paper项目中,papers项目旨在学习和总结分布式系统相关的论文;同时本文也是DSTORE项目的必备知识,DSTORE的目标是自己动手实现一个分布式KV存储引擎。
本文为raft系列文章第三篇,本系列其他文章为
本文的组织结构如下
- Log compaction
- Client interaction
- Evaluation
Log compaction
Raft的日志会随着处理客户端请求数量的增多而不断增大,在实际系统中,日志不可能会无限地增长,原因如下:
- 占用的存储空间随着日志增多而增加
- 日志越多,server当掉重启时需要回放的时间就越长
因此,需要定期地清理日志,Raft采用最简单的快照方法。对系统当前做快照时,会把当前状态持久化到存储中,然后到快照点的日志项都可以被删除。
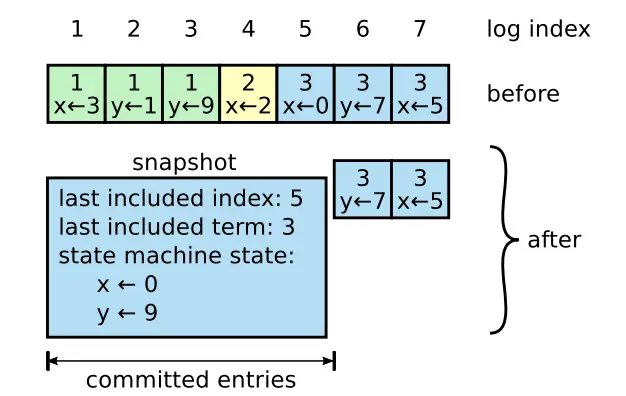
Raft算法中每个server单独地做快照,即把当前状态机的状态写入到存储中(状态机中的状态都是已提交的log entry回放出来的)。除了状态机的状态外,Raft快照中还需要一些元数据信息,包括如下:
- 快照中包含的最后一个log entry的index和term,记录这些信息的目的是为了使得
AppendEntriesRPC的一致性检查能通过,因为,在复制紧跟着快照后的log entry时,AppendEntriesRPC带上需要复制的log entry前一个log entry的(index, iterm),即快照的最后一个log entry的(index,term),因此,快照中需要记录最后一个log entry的(index,term) - 为了支持集群成员变更,快照中保存的元数据还会存储集群最新的配置信息。
当server完成快照后,可以删除快照最后一个log entry及其之前所有的log entry,以及之前的快照。
虽然每个server是独立地做快照的,但是也有可能存在需要leader向follower发送整个快照的情况,例如,一个follower的日志处于leader的最近一次快照之前,恰好leader做完快照之后把其快照中的log entry都删除了,这时,leader就无法通过发送log entry来同步了,只能通过发送完整快照。
leader通过InstallSnapshot RPC来完成发送快照的功能,follower收到此RPC后,根据不同情况会有不同的处理:
当follower中缺失快照中的日志时
- follower会删除掉其上所有日志,并清空状态机
当follower中拥有快照中所有的日志时
- follower会删掉快照所覆盖的log entry,但快照后所有日志都保留。备注:这里论文中没有提是否还是从leader接受快照,个人觉得follower可以自己做快照,并拒绝掉leader发快照的RPC请求
对于Raft快照,关于性能需要考虑的点有:
- server何时做快照,太频繁地做快照会浪费磁盘I/O;太不频繁会导致server当掉后回放时间增加,可能的方案为当日志大小到一定空间时,开始快照。备注:如果所有server做快照的阈值空间都是一样的,那么快照点也不一定相同,因为,当server检测到日志超过大小,到其真正开始做快照中间还存在时间间隔,每个server的间隔可能不一样
- 写快照花费的时间很长,不能让其影响正常的操作。可以采用copy-on-write操作,例如linux的fork
Client Interaction
Raft的client会把所有的请求发到leader上执行,在client刚启动时,会随机选择集群中的一个server
- 如果选择的server是leader,那么client会把请求发到该server上
- 如果选择的server不是leader,该server会把leader的地址告诉给client,后续client会把请求发给该leader
- 如果此时没有leader,那么client会timeout,client会重试其他server,直到找到leader
Raft的目标使得client是linerizable的,即每个操作几乎是瞬间的,在其调用到返回结果的某个时间点,执行其执行一次。由于需要client的请求正好执行一次,这就需要client的配合,当leader挂掉之后,client需要重试其请求,因为有可能leader挂掉之前请求还没有成功执行。但是,也有可能leader挂掉之前,client的请求已经执行完成了,这时候就需要新leader能识别出该请求已经执行过,并返回之前执行的结果。可以通过为client的每个请求分配唯一的编号,当leader检测到请求没有执行过时,则执行它;如果执行过,则返回之前的结果。
只读的请求可以不写log就能执行,但是它有可能返回过期的数据,有如下场景:
- 老的leader挂掉了,但它自身还认为自己是leader,于是client发读请求到该server时,可能获得的是老数据
Raft通过如下方法避免上述问题:
- leader需要自己知道哪些log entry是已经提交的,在正常情况下,leader一直是有已提交过的log entry的,但是,在leader刚当选的时候,需要当场获取,可以通过提交一个空的log entry来获取已提交过的log entry(备注:个人理解是为了避免commiting from previous leader那种情况)
- leader在执行只读请求时,需要确定自己是否还是leader,通过和大多数的server发送heartbeat消息,来确定自己是leader,然后再决定是否执行该请求
Evaluation
Raft的性能测试配置如下:
- broadcast time = 15ms
- 5 servers
- 图中的时间范围是electionTimeout的随机范围
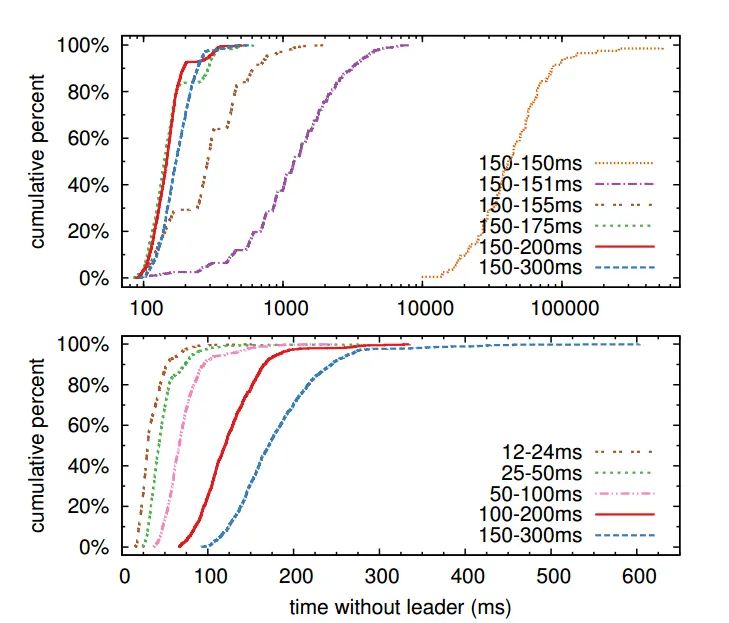
从上图的第一幅图,可以看出:
- 5ms的随机范围,可以将downtime减少到平均283ms
- 50ms的随机范围,可以将最坏的downtime减少到513ms
从第二幅图,可以看出:
- 可以通过减少electionTimeout来减少downtime
- 过小的electionTimeout可能会造成leader的心跳没有发给其他server前,其他server就开始选举了,造成不必要的leader的切换,一般建议范围为[150ms-300ms]
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。

