

最近项目中遇到一些混淆相关的问题,由于之前对proguard了解不多,所以每次都是面向Stackoverflow的编程。copy别人的答案内心还可以接受,但是copy了之后不懂别人的逻辑是无法忍受的。首先不清楚别人的答案是不是一定符合自己的需求;其次,再遇到同类问题还是得抓瞎。于是下决心看了一下proguard的官方文档。很长,但是很详细,在这里整理一下笔记,分享给大家。
介绍
我们通常说的proguard包括四个功能,shrinker(压缩), optimizer(优化),obfuscator(混淆),preverifier(预校验)。
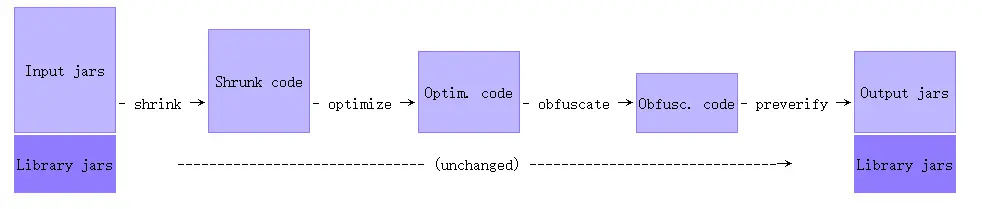
proguard process
- shrink: 检测并移除没有用到的类,变量,方法和属性;
- optimize: 优化代码,非入口节点类会加上
private/static/final, 没有用到的参数会被删除,一些方法可能会变成内联代码。 - obfuscate: 使用短又没有语义的名字重命名非入口类的类名,变量名,方法名。入口类的名字保持不变。
- preverify: 预校验代码是否符合Java1.6或者更高的规范(唯一一个与入口类不相关的步骤)
如果你的代码中用到了反射,那需要把反射调用的类,变量,方法也设置成入口节点。只需要加上
-keep就可以了。(下面会讲)除了proguard之外,还有一个DexGuard,是专门用来优化混淆Android应用的。它的功能包括资源混淆,字符串加密,类加密和dex文件分割等。它是在android编译的时候直接产生Dalvik字节码。(这个有兴趣的同学自行了解,这里不详述了)
用法
要执行proguard,可以直接执行命令:
java -jar proguard.jar options ...如果有Android SDK的同学可以在
{ANDROID_SDK_ROOT}/tools/proguard/lib/目录下找到proguard.jar这个jar包。或者,也可以在{ANDROID_SDK_ROOT}/tools/proguard/bin目录下直接使用脚本执行命令。
我们也可以把proguard的参数写到一个配置文件中,比如说proguard.cfg。那我们的命令可以这样写:
java -jar proguard.jar @proguard.cfg这个文件也就是我们在Android Studio中经常配置的混淆文件了。我们在编译正式包的时候打包脚本自动帮我们执行了这条命令。通过这个脚本可以避免重复输入参数。
当然,我们也可以配置文件与命令行参数混用,例如:
java -jar proguard.jar @proguard.cfg -verbose- 配置文件中
#放在行首,用来做注释; - 单词之间多余的空格或分隔符会被忽略;
- 如果文件名包含空格或者其它特殊符号,应当用单引号或者双引号括起来;
- 配置参数的顺序与混淆结果是没有关系的
输入/输出选项
这部分内容平常比较少用到,如果仅仅是做app开发的话,了解一下这一节即可。
@_filename_ -include 的简写
-include filename 需要读取的配置文件
-basedirectory directory 为所有引用的相对路径指定一个根路径
-injars classpath 指定输入的包,可以包括 jar, aar, war, ear, zip, apk或者文件目录。这些包或者目录下的class文件将被处理后写入到输出文件中。默认情况下非class文件会被原封不动的复制到输出文件中。
需要注意的是,默认情况下,一些编译器的临时的文件也会被写入到输出文件中。可以使用过滤选项过滤掉他们。过滤选选项后面有讲到。
-outjars classpath 指定输出文件,类型包括 jar, aar, war, ear, zip, apk和 目录。
不要让输出文件覆盖任何一个输入文件!
-libraryjars classpaath 指定输入文件引用的类库。这些类库不会被写入到输出文件中。每个库至少要有一个类被引用。
在查找类库的时候,proguard运行时的类库是不算在内的。需要指明的是应用在运行时依赖的类库。
简单用法:
-injars classes
-injars in1.jar
-injars in2.jar
-injars in3.jar
-libraryjars /lib/rt.jar(java/**,javax/**)
-outjars out.jar-skipnonpubliclibraryclasses 指定读取引用库文件的时候跳过非public类。这样做可以提高处理速度并节省内存。一般情况下非public在应用内是引用不到的,跳过它们也没什么关系。但是,在一些java类库中中出现了public类继承非public类的情况,这样就不能用这个选项了。这种情况下,会打印一个警告出来,提示找不到类。
-dontskipnonpubliclibraryclasses 跟上面的参数相对。版本4.5以上,这个是默认的选项。
-dontskipnonpubliclibraryclassmembers 指定不忽略库类库中的非public成员(成员变量和方法)。默认情况下,proguard在读取库文件的时候会自动忽略这些类的成员,因为这些非public成员不会被源代码引用到。但有时候他们是可以被引用到的。比如说,源代码中与库文件用同一个包名,那么源代码就可以访问包作用域的变量。在这些情况下,为了引用一致,不被混淆,就需要指定不跳过这些类。
-keepdirectories directory_filter 指定输出jar包中需要保留的目录名。为了减少输出文件的体积,默认情况下所有的目录都会被删除(个人这里不是很理解,猜测意思是默认所有目录都会被混淆吧)。但是如果你的代码中有需要从目录中寻找文件的逻辑,那你就需要保持目录名一致。这项配置后面不加过滤器的时候,所有目录都会被保留。加了过滤器之后,只有过滤器匹配的目录才会被保留。
-target version 指定处理的class文件中java的目标版本。版本号是1.0, 1.1, 1.2, 1.3, 1.4, 1.5(或者5), 1.6(或者6), 1.7(或者7),1.8(或者8)之中的一个。默认情况下,class文件的版本号是不会变的。
-forceprocessing 尽管输出文件已经是最新的,还是强制进行处理一次。
Keep配置
-keep [,modifier, ...] class_specification 指定类和类的成员变量是入口节点,保护它们不被移除混淆。例如,对一个可执行jar包来说,需要保护main的入口类;对一个类库来说需要保护它的所有public元素。例子:
-injars myapplication.jar
-outjars myapplication_out.jar
-libraryjars /lib/rt.jar
-printmapping myapplication.map
-keep public class mypackage.MyMain {
public static void main(java.lang.String[]);
}-keepclassmembers [,modifier] class_specification 保护的指定的成员变量不被移除、优化、混淆。例如,保护所有序列化的类的成员变量。
例子:
-keepnames class * implements java.io.Serializable
# 这指定了继承Serizalizable的类的如下成员不被移除混淆
-keepclassmembers class * implements java.io.Serializable {
static final long serialVersionUID;
private static final java.io.ObjectStreamField[] serialPersistentFields;
!static !transient ;
!private ;
!private ;
private void writeObject(java.io.ObjectOutputStream);
private void readObject(java.io.ObjectInputStream);
java.lang.Object writeReplace();
java.lang.Object readResolve();
}-keepclasseswithmembers [,modifier,...] class_specification 拥有指定成员的类将被保护,根据类成员确定一些将要被保护的类。例如保护所有含有main方法的类。
例子:
# 这种情况下含有main方法的类和mainf方法都不会被混淆。
-injars in.jar
-outjars out.jar
-libraryjars /lib/rt.jar
-printseeds
-keepclasseswithmembers public class * {
public static void main(java.lang.String[]);
}-keepnames class_specification 是 -keep,allowshrinking class_pecification 的简写。指定一些类名受到保护,前提是他们在shrink这一阶段没有被去掉。也就是说没有被入口节点直接或间接引用的类还是会被删除。仅在obfuscate阶段有效。
-keepclassmembernames class_specification 是-keepclasseswithmembers,allowshrinking class_specification的简写。与-keepclassmember相似。保护指定的类成员,前提是这些成员在shrink阶段没有被删除。仅在obfuscate阶段有效。
-keepclasseswithmembernames class_specification 是-keepclasseswithmembers,allowshrinking class_specification的简写。与-keepclasseswithmembers类似。保护指定的类,如果它们没有在shrink阶段被删除。仅在obfuscate阶段有效。
-printseeds [filename] 指定通过-keep配置匹配的类或者类成员的详细列表。列表可以打印到标准输出流或者文件里面。这个列表可以看到我们想要保护的类或者成员有没有被真正的保护到,尤其是那些使用通配符匹配的类。
代码压缩配置
-dontshrink 声明不压缩输入文件。默认情况下,除了-keep相关配置指定的类,所有其它没有被引用到的类都会被删除。每次optimizate操作之后,也会执行一次压缩操作,因为每次optimizate操作可能删除一部分不再需要的类。
-printusage [filename] 声明 打印出那些被删除的元素。这个列表可能打印到标准输出流或者一个文件中。仅在shrink阶段有效。
whyareyoukeeping class_specification 声明 打印为什么一个类或类的成员变量被保护。这对检查一个输出文件中的类的结果有帮助。
代码优化配置
-dontoptimize 声明不优化输入文件。默认情况下,优化选项是开启的,并且所有的优化都是在字节码层进行的。
-optimizations optimization_filter 更加细粒度地声明优化开启或者关闭。只在optimize这一阶段有效。这个选项的使用难度较高。
-optimizationpasses n 指定执行几次优化,默认情况下,只执行一次优化。执行多次优化可以提高优化的效果,但是,如果执行过一次优化之后没有效果,就会停止优化,剩下的设置次数不再执行。这个选项只在optimizate阶段有效
assumenosideeffects class_specification 指定一些方法被删除也没有影响(尽管这些方法可能有返回值),在optimize阶段,如果确定这些方法的返回值没有使用,那么就会删除这些方法的调用。proguard会自动的分析你的代码,但不会分析处理类库中的代码。例如,可以指定System.currentTimeMillis(),这样在optimize阶段就会删除所有的它的调用。还可以用它来删除打印Log的调用。这条配置选项只在optimizate阶段有用。
例子:
# 删除代码中Log相关的代码
-assumenosideeffects class android.util.Log {
public static boolean isLoggable(java.lang.String, int);
public static int v(...);
public static int i(...);
public static int w(...);
public static int d(...);
public static int e(...);
}使用这条配置有点危险,如果删除了一些预料之外的代码,很容易就会导致代码崩溃。所以,谨慎使用
-allowaccessmodification 这项配置是设置是否允许改变作用域的。使用这项配置之后可以提高优化的效果。**但是,如果你的代码是一个库的话,最好不要配置这个选项,因为它可能会导致一些private变量被改成public。
-mergeinterfacesaggressively 指定一些接口可能被合并,即使一些子类没有同时实现两个接口的方法。这种情况在java源码中是不允许存在的,但是在java字节码中是允许存在的。它的作用是通过合并接口减少类的数量,从而达到减少输出文件体积的效果。仅在optimize阶段有效。
这项配置对于一些虚拟机的65535方法数限制是有一定效果的。
混淆配置
-dontobfuscate 声明不混淆。默认情况下,混淆是开启的。除了keep配置中声明的类,其它的类或者类的成员混淆后会改成简短随机的名字。
-printmapping [filename] 指定输出新旧元素名的对照表的文件。映射表会被输出到标准输出流或者是一个指定的文件。
这个文件在追踪异常的时候是有用的,在
{android_sdk_home}/tools/proguard/lib目录下有一个retrace.jar文件。我们可以把混淆后的Stack Trace用这个工具处理一下,就会转变成容易阅读的类。所以,做app应用的同学每次发版本的时候都要把这个文件留下来,并标记清楚版本。这对线上版本的调试非常重要。
-applymapping filename 指定重用一个已经写好了的map文件作为新旧元素名的映射。元素名已经存在在mapping文件中的元素,按照映射表重命名;没有存在到mapping文件的元素,重新赋一个新的名字。mapping文件可能引用到输入文件中的类和类库中的类。这里只允许设置一个mapping文件。仅在obfuscate阶段有效。
-obfuscationdictionary filename 指定一个文本文件用来生成混淆后的名字。默认情况下,混淆后的名字一般为a,b,c这种。通过使用-obfuscationdictionary配置的字典文件,可以使用一些非英文字符做为类名。成员变量名、方法名。字典文件中的空格,标点符号,重复的词,还有以'#'开头的行都会被忽略。需要注意的是添加了字典并不会显著提高混淆的效果,只不过是更不利与人类的阅读。正常的编译器会自动处理他们,并且输出出来的jar包也可以轻易的换个字典再重新混淆一次。最有用的做法一般是选择已经在类文件中存在的字符串做字典,这样可以稍微压缩包的体积。
查找了字典文件的格式:一行一个单词,空行忽略,重复忽略
例如:
# 这里巧妙地使用java中的关键字作字典,混淆之后的代码更加不利于阅读
#
# This obfuscation dictionary contains reserved Java keywords. They can't
# be used in Java source files, but they can be used in compiled class files.
# Note that this hardly improves the obfuscation. Decent decompilers can
# automatically replace reserved keywords, and the effect can fairly simply be
# undone by obfuscating again with simpler names.
# Usage:
# java -jar proguard.jar ..... -obfuscationdictionary keywords.txt
#
do
if
for
int
new
try
byte
case
char
else
goto
long
this
void
break
catch
class
const
final
float
short
super
throw
while
double
import
native
public
return
static
switch
throws
boolean
default
extends
finally
package
private
abstract
continue
strictfp
volatile
interface
protected
transient
implements
instanceof
synchronized-classobfuscationdictionary filename 指定一个混淆类名的字典,字典的格式与-obfuscationdictionary相同
-packageobfuscationdictionary filename 指定一个混淆包名的字典,字典格式与-obfuscationdictionary相同
-overloadaggressively 混淆的时候大量使用重载,多个方法名使用同一个混淆名,但是他们的方法签名不同。这可以使包的体积减小一部分,也可以加大理解的难度。仅在混淆阶段有效。
注意,这项配置有一定的限制:
Sun的JDK1.2上会报异常
Sun JRE 1.4上重载一些方法之后会导致序列化失败
Sun JRE 1.5上pack200 tool重载一些类之后会报错
java.lang.reflect.Proxy类不能处理重载的方法
Google's Dalvik VM can't handle overloaded static fields(这句我不懂,重载静态变量是什么意思?有看懂的同学可以回复一下)
-useuniqueclassmembernames 指定相同的混淆名对应相同的方法名,不同的混淆名对应不同的方法名。如果不设置这个选项,同一个类中将会有很多方法映射到相同的方法名。这项配置会稍微增加输出文件中的代码,但是它能够保证保存下来的mapping文件能够在随后的增量混淆中继续被遵守,避免重新命名。比如说,两个接口拥有同名方法和相同的签名。如果没有这个配置,在第一次打包混淆之后,他们两个方法可能会被赋予不同的混淆名。如果说下一次添加代码的时候有一个类同时实现了两个接口,那么混淆的时候必然会将两个混淆后的方法名统一起来。这样就必须要改混淆文件其中一处的配置,也就不能保证前后两次混淆的mapping文件一致了。(如果你只想保留一份mapping文件迭代更新的话,这项配置比较有用)
-dontusemixedcaseclassnames 指定在混淆的时候不使用大小写混用的类名。默认情况下,混淆后的类名可能同时包含大写字母和小写字母。这样生成jar包并没有什么问题。只有在大小写不敏感的系统(例如windows)上解压时,才会涉及到这个问题。因为大小写不区分,可能会导致部分文件在解压的时候相互覆盖。如果有在windows系统上解压输出包的需求的话,可以加上这个配置。
-keeppackagenames [package_filter] 声明不混淆指定的包名。 配置的过滤器是逗号隔开的一组包名。包名可以包含?,,*通配符,并且可以在前面加!否定符。
-flatternpackagehierarchy [packagename] 所有重新命名的包都重新打包,并把所有的类移动到packagename包下面。如果没有指定packagename或者packagename为"",那么所有的类都会被移动到根目录下
-repackageclasses [package_name] 所有重新命名过的类都重新打包,并把他们移动到指定的packagename目录下。如果没有指定packagename,同样把他们放到根目录下面。这项配置会覆盖-flatternpackagehierarchy的配置。它可以代码体积更小,并且更加难以理解。这个与废弃的配置-defaultpackage作用相同。
如果需要从目录中读取资源文件,移动包的位置可能会导致异常。如果出现问题,就不要用这个配置了。
-keepattributes [attribute_filter] 指定受保护的属性,可以有一个或者多个-keepattributes配置项,每个配置项后面跟随的是Java虚拟机和proguard支持的attribute(具体支持的属性先看这里),两个属性之间用逗号分隔。属性名中可以包含*,**,?等通配符。也可以加!做前导符,将某个属性排除在外。当混淆一个类库的时候,至少要保持InnerClasses, Exceptions, Signature属性。为了跟踪异常信息,需要保留SourceFile, LineNumberTable两个属性。如果代码中有用到注解,需要把Annotion的属性保留下来。
例子:
-keepattributes SourceFile, LineNumberTable
-keepattributes *Annotation*
-keepattributes EnclosingMethod
# 可以直接写在一行
-keepattributes Exceptions, InnerClasses, Signature, Deprecated,
SourceFile, LineNumberTable, *Annotation*, EnclosingMethod-keepparameternames 指定被保护的方法的参数类型和参数名不被混淆。这项配置在混淆一些类库的时候特别有用,因为根据IDE提示的参数名和参数类型,开发者可以根据他们的语义获得一些信息,这样的类库更友好。
-renamesourcefileattribute [string] 指定一个字符串常量设置到源文件的类的属性当中。这样就可以在-keepattributes配置中使用。(这条我理解的也不是很清楚)
-adaptclassstrings [classfilter] 指定字符串常量如果与类名相同,也需要被混淆。如果没有加classfilter,所有的符合要求的字符串常量都会被混淆;如果带有classfilter,只有在匹配的类中的字符串常量才会受此影响。例如,在你的代码中有大量的类名对应的字符串的hard-code,并且不想保留他们的本名,那就可以利用这项配置完成。这项配置只在混淆阶段有效,但是在压缩/优化阶段,涉及到的类会自动保留下来。
adaptresourcefilenames [file_filter] 如果资源文件与某类名同,那么混淆后资源文件被命名为与之对应的类的混淆名。不加file_filter的情况下,所有资源文件都受此影响;加了file_filter的情况下,只有匹配到的类受此影响。
adaptresourcefilecontents [file_filter] 指定资源文件的中的类名随混淆后的名字更新。根据被混淆的名字的前后映射关系,更新文件中对应的包名和类名。同样,如果不配置file_filter,所有的资源文件都会受此影响;配置了filter之后,只有对应的资源文件才受此影响。
文件的读写都是按照系统默认的字符集。如果有特殊的字符集的需求,可以修改java的执行参数,或者直接修改java虚拟机的配置文件。
注意,这项配置最好只能影响到字符文件。如果影响到一些二进制文件会产生意外影响。所以,设置
filter的时候,要设置的足够 '严格'
预校验配置
-dontpreverify 声明不预校验即将执行的类。默认情况下,在类文件的编译版本为java micro 版本或者大于1.6版本时,预校验是开启的。目标文件针对java6的情况下,预校验是可选的;针对java7的情况下,预校验是必须的,除非目标运行平台是Android平台,设置它可以节省一点点时间。
目标为Java Micro版本的情况下,预校验是必须的。如果你声明了这项配置,你还需要加上下面一条配置。
-microedition 声明目标平台是java micro版本。预校验会根据这项配置加载合适的StackMap,而不是用标准的StackMap。
普通配置
-verbose 声明在处理过程中输出更多信息。添加这项配置之后,如果处理过程中出现异常,会输出整个StackTrace而不是一条简单的异常说明。
-dontnote [class_filter] 声明不输出那些潜在的错误和缺失,比如说错别字或者重要的配置缺失。配置中的class_filter是一串正则表达式,混淆过程中不会输出被匹配到的类相关的内容。
-dontwarn [class_filter] 声明不输出那些未找到的引用和一些错误,但续混淆。配置中的class_filter是一串正则表达式,被匹配到的类名相关的警告都不会被输出出来。
慎用!
-ignorewarnings 输出所有找不到引用和一些其它错误的警告,但是继续执行处理过程。不处理警告有些危险,所以在清楚配置的具体作用的时候再使用。
-printconfiguration [filename] 输出整个处理过程中的所有配置参数,包括文件中的参数和命令行中的参数。可以不加文件名在标准输出流中输出,也可以指定文件名输出到文件中。它在调试的时候比较有用。
-dump [filename] 声明输出整个处理之后的jar文件的类结构,可以输出到标准输出流或者一个文件中。
下面这些说明对应了之前每个参数后面的过滤器
Class Paths
它对应上文中的所有class_path,他是用来指定输入输出文件的路径的。它可以有多个路径用分隔符隔开。
我们也可以使用过滤器来过滤需要输出的文件。过滤器的格式如下:
classpathentry([[[[[[aarfilter;]apkfilter;]zipfilter;]earfilter;]warfilter;]jarfilter;]filefilter)[]中包含的内容是可选的意思。这样看有些麻烦,直接上个例子:
-injars in1.jar
# 输入文件中排除了META-IF/MANIFEST.MF文件
-injars in2.jar(!META-INF/MANIFEST.MF)
-injars in3.jar(!META-INF/MANIFEST.MF)
-outjars out.jar# 这个的意思是只引入`java`,`javax`包中的类
-libraryjars rt.jar(java/**.class,javax/**.class)File Names
proguard支持绝对路径和相对路径。相对路径按照下面顺序被解释:
- 如果设置了base directory,首先按照它来定位;
- 其次,按照配置文件所在的路径定位;
- 最后,按照工作路径(working directory,也就是执行这条命令的路径)来解释。(这个不可能没有!)
名称中可以包含java系统属性,用<>包围。例如:
-libraryjars /lib/rt.jar # 可能代表/usr/local/java/jdk/jre/lib/rt.jar如果路径名中带有特殊字符,可以使用单引号或者双引号括起来。
File Filters
就像普通的匹配器一样,可以使用通配符来过滤文件名。
- ? 代表文件名中的一个字符
- * 代表文件名中的一部分,不包括文件分隔符
- ** 代表文件名中的一部分,包括文件分隔符
- ! 放在文件名前面表示将某文件排除在外
Filters
匹配的规则与File Filters相似。只是过滤的范围更加广泛。
Keep配置整理
-keep与-keepnames的关系一开始理解的时候有些混乱。但是它们背后是有一定规则的,下面的表格展示了它们的联系与不同
| 保留 | 防止被移除或者被重命名 | 防止被重命名 |
|---|---|---|
| 类和类成员 | -keep | -keepnames |
| 仅类成员 | -keepmembers | -keepmembernames |
| 如果拥有某成员,保留类和类成员 | -keepclasseswithmembers | -keepclasseswithmembernames |
如果不确定自己该用哪个的话,就用-keep吧,它能保证匹配的类在压缩这一阶段不被移除,并且在混淆阶段不会被重新命名。
- 如果只声明保护一个类,并没有指定受保护的成员。proguard只会保护它的类名和它的无参构造函数。其它成员依旧会被压缩、优化、混淆。
- 如果声明保护一个方法,proguard会把它当作程序的入口点,方法名不会变,但它里面的代码依旧会被优化、混淆。
Keep配置的修饰符
includedescriptorclasses
它是用来声明描述目标成员的元素也应当被保护。它在保护native方法时特别有效。因为它可以同时保证参数类型,返回类型不被混淆。保证最终的方法签名保持一致。
例子:
-keepclasseswithmembernames,includedescriptorclasses class * {
native ;
}-keepclasseswithmembernames是保护符合条件的含有native方法的类。附加的includedescriptorclasses是保证参数和返回类型的类同样不被混淆。这样就可以做到这些类的方法签名与调试时完全一致。
allowshrinking
修饰-keep, 声明一个元素可以被移除,即使它已经声明了被保护。意味着它有可能在压缩阶段被删除,但是它又是必须的入口,所以它有可能不参与优化和混淆阶段。
(这里我也看不太懂,压缩阶段不是依赖keep声明的入口节点吗?)
allowoptimization
修饰-keep, 声明一个元素可以被优化,即使它已经声明被保护。这意味着该元素参与优化阶段,但是不参与压缩和混淆阶段。特殊用途的时候使用。
allowobfuscation
与前几个类似,修饰-keep,只参与混淆阶段,但是不参与压缩和优化阶段。
类的匹配
Class Specification是指一个类和类成员的模板。它一般跟在各种-keep配置或者assumenosideeffects配置之后,只有匹配到的类和类成员会受到影响。
Class Specification的形式与java的类的形式很像,只是而外加了几个通配符。如果想要清晰的看它的形式,最好看例子。但这里还是给出了通用的模型:
[@annotationtype] [[!]public|final|abstract|@ ...] [!]interface|class|enum classname
[extends|implements [@annotationtype] classname]
[{
[@annotationtype] [[!]public|private|protected|static|volatile|transient ...] |
(fieldtype fieldname);
[@annotationtype] [[!]public|private|protected|static|synchronized|native|abstract|strictfp ...] |
(argumenttype,...) |
classname(argumenttype,...) |
(returntype methodname(argumenttype,...));
[@annotationtype] [[!]public|private|protected|static ... ] *;
...
}]
[]代表可选可不选;···代表还有更多选项可以配置;|分隔的部分代表多选一;()括起来的部分代表是一个整体,不能分割。
- class 关键字可以匹配class类或interface类,但是
interface关键字只能匹配interface类,enum关键字只能匹配enum类。在interface或enum关键字前加一个!,可以表示非这种类型的类。 -
classname 必须写全名,比如
java.lang.String。内部类用$间隔,例如,java.lang.Thread$State。类名可以用含有下面这些通配符的正则表达式匹配:- ? 匹配类名中的一个字符,不包括文件分隔符。例如,
mypackage.Test?可以匹配mypackage.Test1,mypackage.Test2,但不能匹配mypackage.Test12。 - * 匹配类名中的0到多个字符但不包括文件分隔符。例如,
mypackage.*Test*可以匹配到mypackage.Test和mypackage.YourTestApplication但是不能匹配mypackage.mysubpackage.MyTest。一种常用的写法mypackage.*就是匹配mypackage下的所有子文件。 - ** 可以匹配类名中的所有字符,可能包含多个分隔符。例如,
**.Test就是匹配所有目录下的Test类,mypackage.**就是匹配mypackage及其子目录下的所有类。
- ? 匹配类名中的一个字符,不包括文件分隔符。例如,
- extend与implements 关键字是用来限制类的范围的。他们目前是等价的,用来匹配某些类的子类。需要注意的是,这个指定的类并不包括在匹配结果中,如果想要该类也被匹配到,就需要额外声明一项配置。
- @ 符号匹配那些注解标志的类或类成员,它的通配符形式与classname的形式一样。
-
成员变量和成员方法的匹配形式与java非常像,只是方法的参数不带参数名。此外,他们还可以使用通配符:
变量名和方法名可以使用的通配符:
- 匹配一个类的所有构造函数
- 匹配一个类中的所有成员变量
- 匹配一个类中的所有方法
- * 匹配类中的所有成员
列表。 - ? 匹配一个字符
- * 匹配0到多个字符
注意上述通配符并不能设置返回类型,并且只有方法带有参数
修饰符中可以使用以下通配符匹配: - % 匹配java中的初始类型(int, boolean, long, float,double等)
- ?
- *
- ** (这三个不解释了,同上)
- *** 匹配所有类型,包括初始类型和非初始类型,数组和非数组。
- ... 匹配任意参数列表
需要注意的是?, *, **不能够匹配初始类型和数组。***可以匹配到数组。例子:
上面的例子可以匹配到** get*()java.lang.Object getObject(),但是不能匹配float getFloat()或者java.lang.Object[] getObjects()。
-
构造函数也可以使用简单类名或全类名来指定。就像java中的构造函数一样有参数列表但是没有返回类型。
-
类或者类成员的修饰符也是匹配类的限制条件。通过修饰符限制,可以缩小匹配的范围。修饰符组合也是可以的,就像java中的
public static一样,但是不能冲突, 比如public private。
混淆相关的点就这些了,下面的例子中是Android应用混淆的默认文件。它放在{android_sdk_home}/tools/proguard/proguard-android.txt文件中,其它的可以参考的例子在{android_sdk_home}/tools/proguard/examples/目录下。
# This is a configuration file for ProGuard.
# http://proguard.sourceforge.net/index.html#manual/usage.html
-dontusemixedcaseclassnames
-dontskipnonpubliclibraryclasses
-verbose
# Optimization is turned off by default. Dex does not like code run
# through the ProGuard optimize and preverify steps (and performs some
# of these optimizations on its own).
-dontoptimize
-dontpreverify
# Note that if you want to enable optimization, you cannot just
# include optimization flags in your own project configuration file;
# instead you will need to point to the
# "proguard-android-optimize.txt" file instead of this one from your
# project.properties file.
-keepattributes *Annotation*
-keep public class com.google.vending.licensing.ILicensingService
-keep public class com.android.vending.licensing.ILicensingService
# For native methods, see http://proguard.sourceforge.net/manual/examples.html#native
-keepclasseswithmembernames class * {
native ;
}
# keep setters in Views so that animations can still work.
# see http://proguard.sourceforge.net/manual/examples.html#beans
-keepclassmembers public class * extends android.view.View {
void set*(***);
*** get*();
}
# We want to keep methods in Activity that could be used in the XML attribute onClick
-keepclassmembers class * extends android.app.Activity {
public void *(android.view.View);
}
# For enumeration classes, see http://proguard.sourceforge.net/manual/examples.html#enumerations
-keepclassmembers enum * {
public static **[] values();
public static ** valueOf(java.lang.String);
}
-keepclassmembers class * implements android.os.Parcelable {
public static final android.os.Parcelable$Creator CREATOR;
}
-keepclassmembers class **.R$* {
public static ;
}
# The support library contains references to newer platform versions.
# Don't warn about those in case this app is linking against an older
# platform version. We know about them, and they are safe.
-dontwarn android.support.**本人也是初步了解proguard,有什么理解不对的地方还大家多多指教。
