

"Tensor2Tensor: 组织世界上的模型和数据"。本场演讲嘉宾是Laurence Moroney。

回顾Tensorflow
首先回顾一下Tensorflow:

Tensorflow可以运行在任何地方。tf.data可以帮你构建出高效的数据输入管道,tf.layers和tf.keras.Model可以快速帮你构建出神经网络,而td.estimator和DistributionStrategy可以帮你快速构建分布式训练。
Tensor2Tensor
但是,对于前沿AI来说,这些是不够的。例如在图像识别、文本翻译和文本分析等领域,很多人并没有足够的知识和经验来掌握这些最佳实践,他们很难享受到最新的AI研究成果。Tensor2Tensor就是为了给社区一个良好的共享平台而来的。
Tensor2Tensor顺带着一些数据集和模型及其超参数发布:
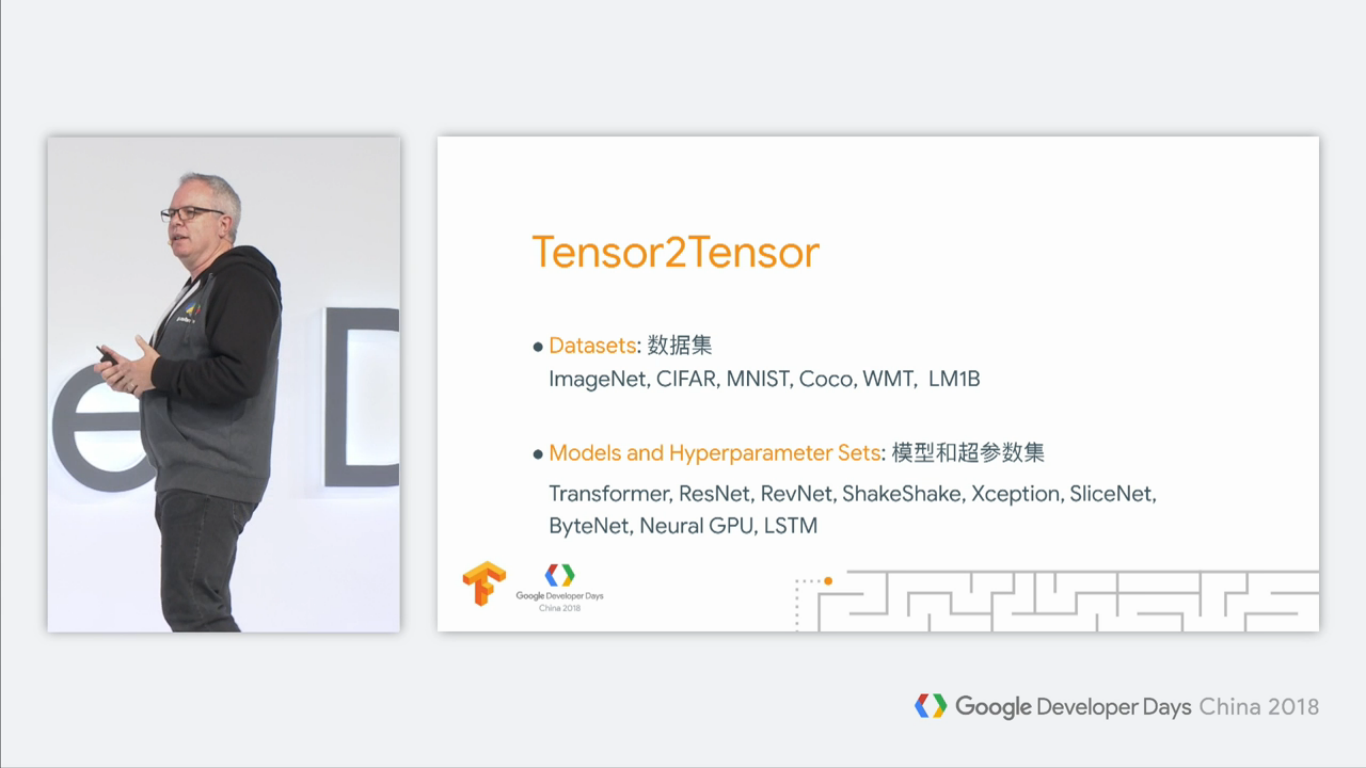
我们通过各种调研和研究,发现这些超参数的设置对于对应的模型和数据集,性能是最好的。如果没有Tensor2Tensor,大家只能通过自己调整参数,不断地试验,效率十分低下。这就是Tensor2Tensor的设计初衷。
为了更够更好地开箱即用,Tensor2Tensor给大家准备好了配套的工具,比如超参数集的设置,GPU或者TPU的分布式训练,这些在Tensor2Tensor里面都有提供。
Tensor2Tensor开源
Tensor2Tensor完全开源在GitHub:

Tensor2Tensor紧跟学术前沿
Tensor2Tensor紧跟学术前沿。
有一个很有趣的例子,有一个人在推特上发推:
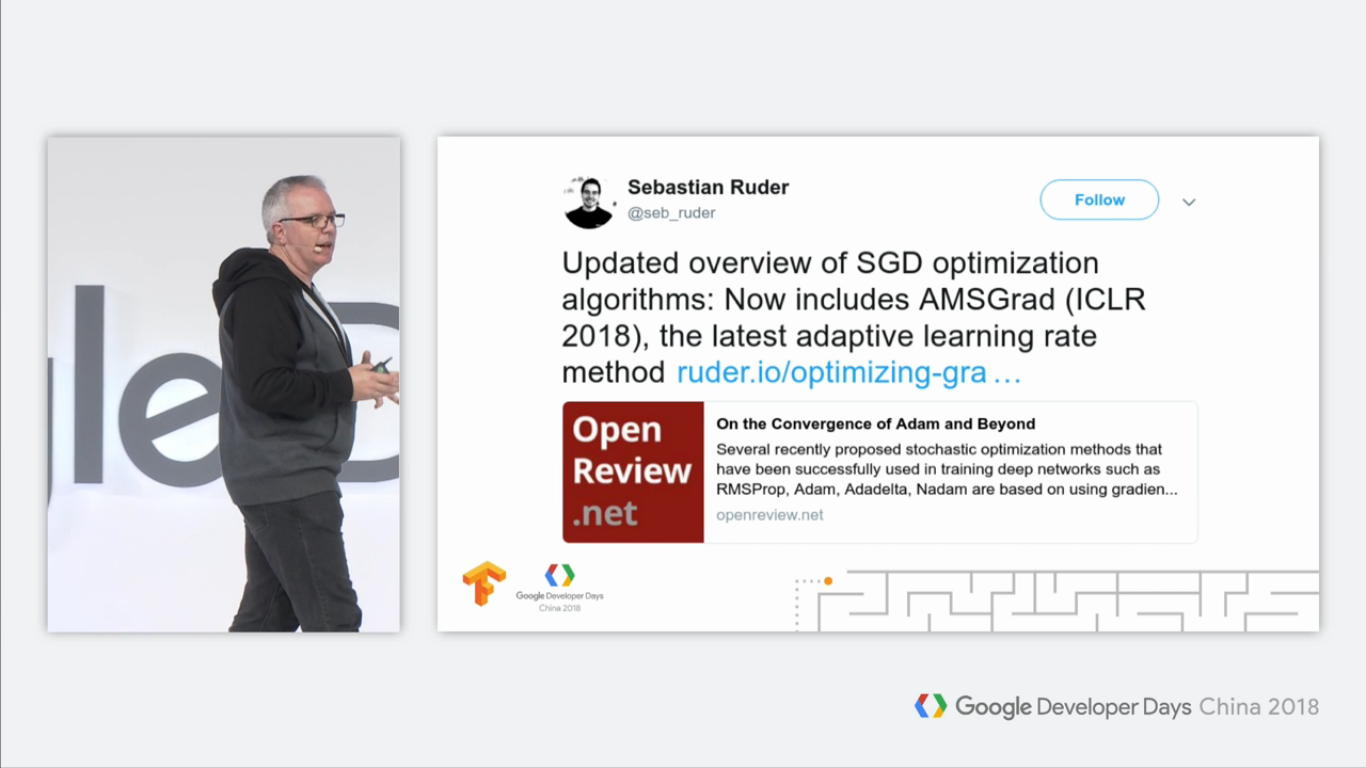
这个推主的意思是: AMSGrad算法是目前最新的SGD优化算法。
然后,另一个用户回复到:
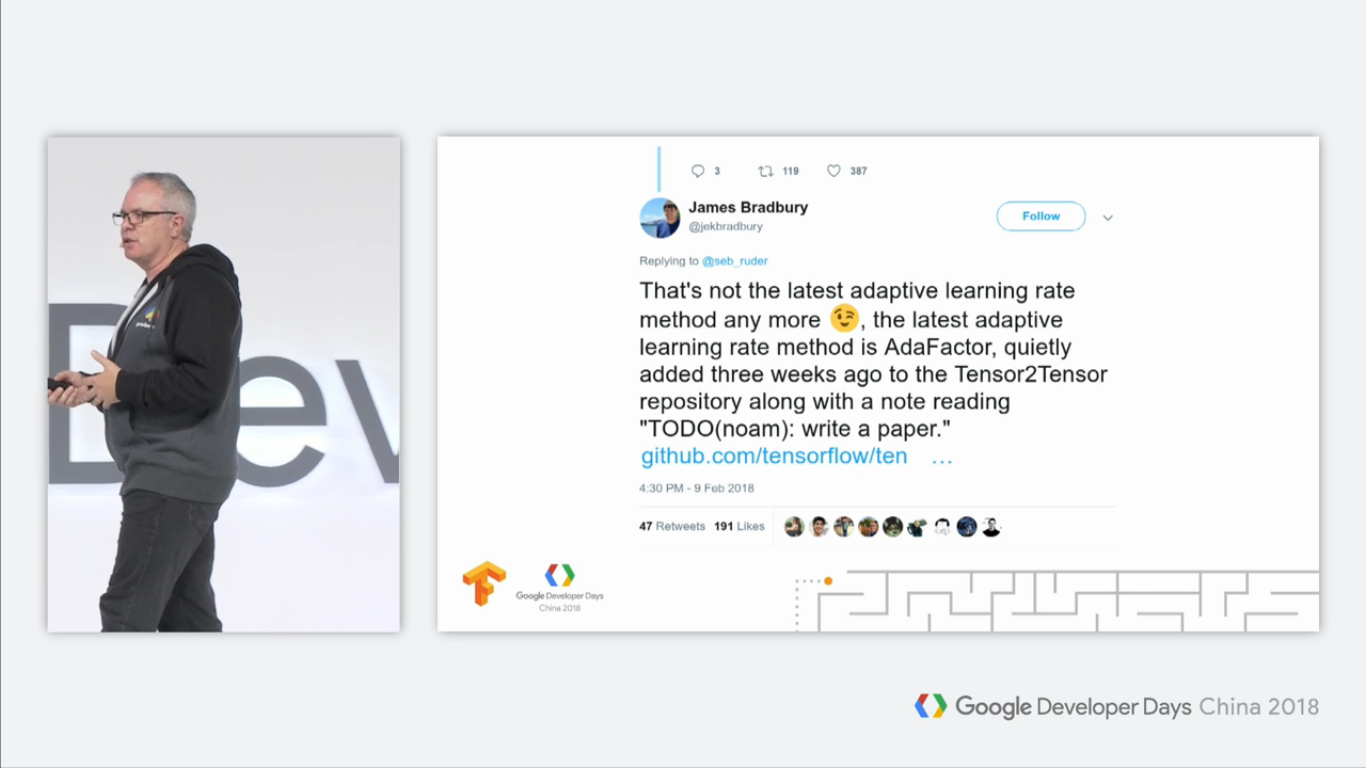
意思是:这不再是最新的SGD优化算法了,最新的是三个星期前就被实现进Tensor2Tensor里面的AdaFactor算法。
然后,这个人很快就被Google录用了。笑:-D
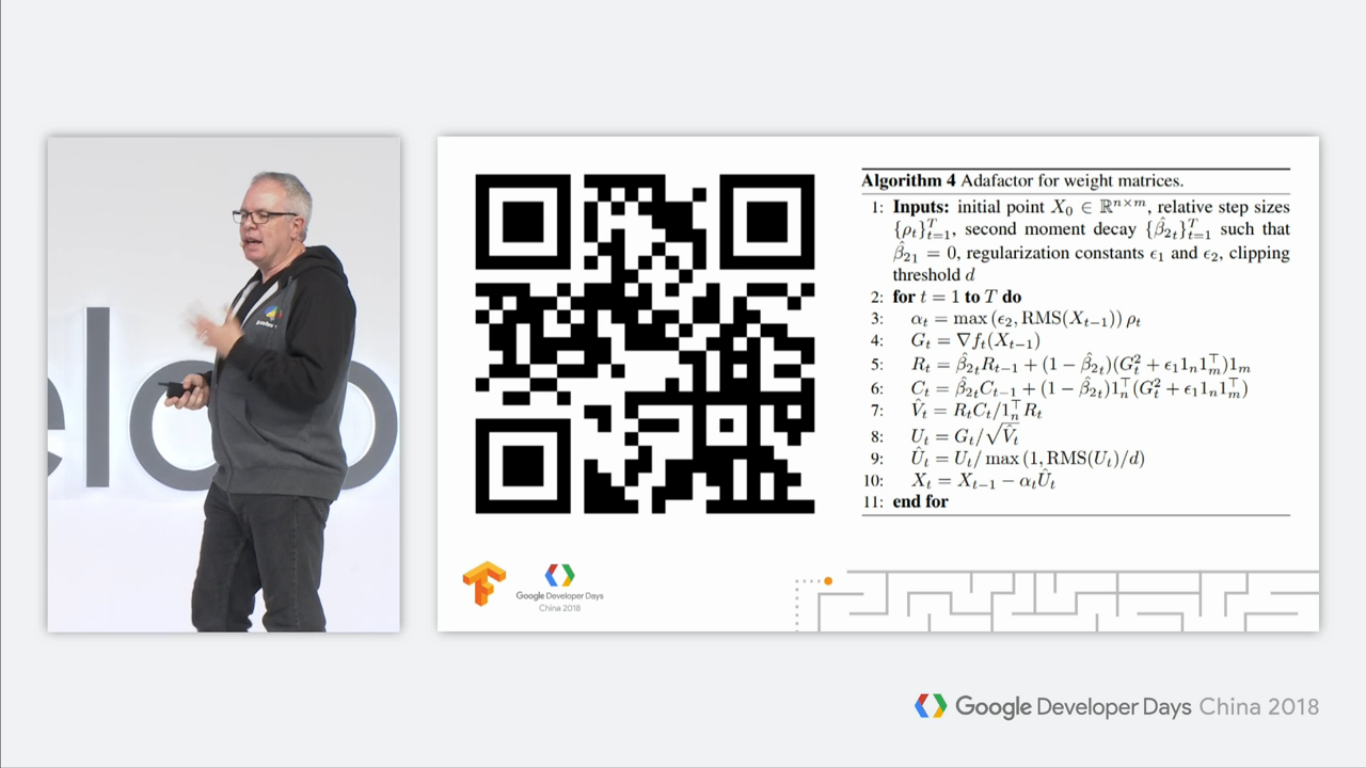
当然,Laurence还放了一张AdaFactor算法的伪代码截图,有兴趣的同学可以深入了解一下:
另外,Tensor2Tensor也实现了Transformer模型:
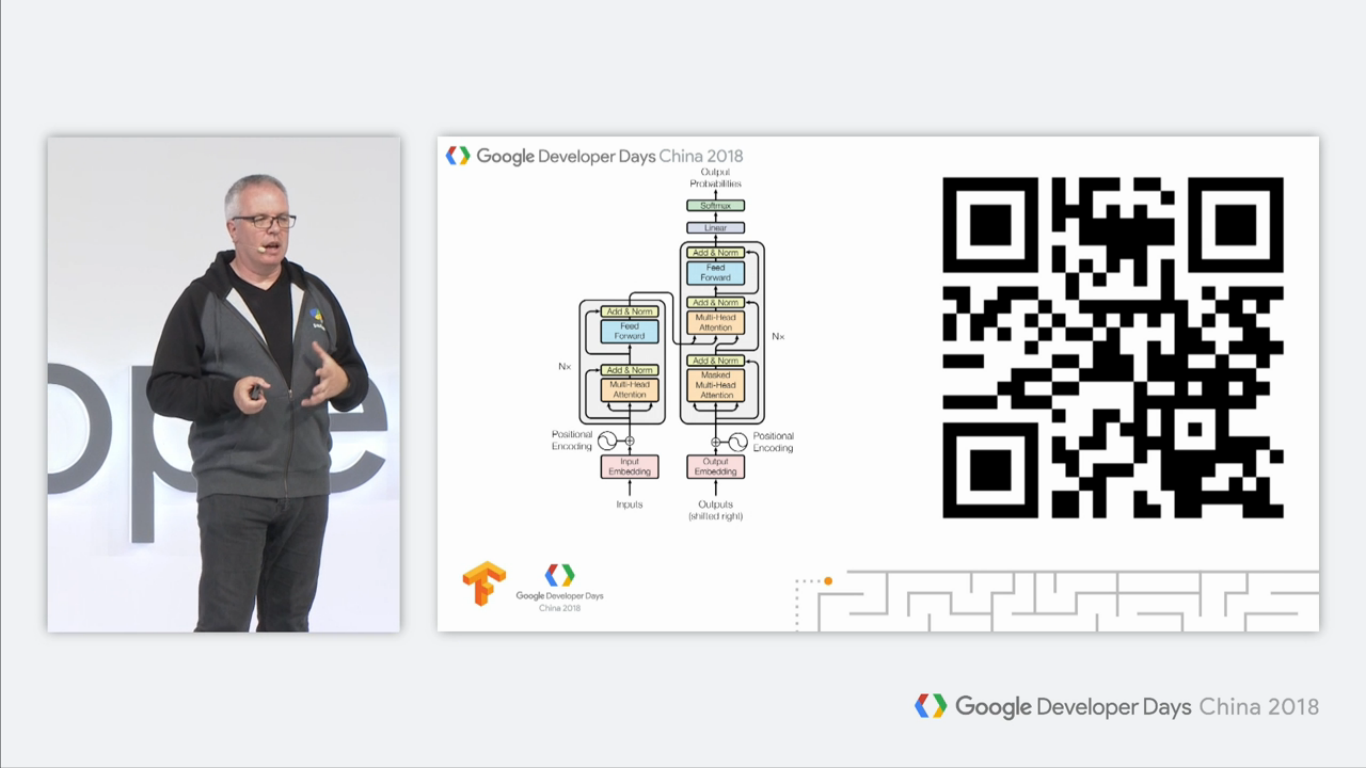
Transformer模型是Google 2017年的论文《Attention is all you need》提出的全新的模型,抛弃传统的CNN和RNN,仅仅使用注意力机制,就到了最当时最顶尖的水平。这个模型广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要和语音识别等等方向。
目前,有很多人参与到我们的Tensor2Tensor项目中来:
我们十分鼓励研究人员使用Tensor2Tensor来帮助他们的研究。
Meet t2t-trainer
接下来让我们了解一下 t2t-trainer,这是Tensor2Tensor提供的一个工具,这个工具可以让不理解代码的人员也能用机器学习来完成一些事情。
使用Tensor2Tensor,你只需要定义少量的几个参数,就可以完成你的任务。
pip install tensor2tensor & t2t-trainer \
--problem=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
这里主要有以下三个参数:
- --problem:问题或者任务
- --model:选用的模型
- --hparams_set:超参数集
超参数集很好解释,对于模型中的超参数,我们改变某些参数,就可以构建一套新的超参数集。
以下是几个很常见的例子。
文本摘要
文本摘要任务是从一段长文本中提取出关键信息。
你可以这样做:
pip install tensor2tensor & t2t-trainer \
--problem=summarize_cnn_dailymail32k \
--model=transformer \
--hparams_set=transformer_big \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
仅仅这样几行命令,训练结束后你就可以获得一个相当不错的文本摘要模型!
图像分类
你仅需这样几行命令:
pip install tensor2tensor & t2t-trainer \
--problem=image_cifar10 \
--model=shake_shake \
--hparams_set=shake_shake_big \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
这里选用的模型和参数集所训练出来的模型,在一年前是效果最好的模型!
翻译
要实现一个en-de(英语-德语)的翻译模型,你只需要:
pip install tensor2tensor & t2t-trainer \
--problem=translate_ende_wmt32k \
--model=transformer \
--hparams_set=transformer_big \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
达到的效果:
>29 BLEU,当前的最佳效果!
语音识别
如果你想实现一个语音识别模型,你只需要以下几行命令:
pip install tensor2tensor & t2t-trainer \
--problem=librispeech \
--model=tranformer \
--hparams_set=transformer_librispeech \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
达到的效果:
<7.5 WER,这近乎是最佳结果!
图像生成
pip install tensor2tensor & t2t-trainer \
--problem=librispeech \
--model=tranformer \
--hparams_set=transformer_librispeech \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
达到的效果:
~2.92 bits/dim,当前最佳
规模化
对于大量的数据,想要在普通笔记本上面训练是不太现实的。我们需要规模化的训练。比如使用GPU甚至云端的机器集群。 Tensor2Tensor可以很好地支持这种规模化的训练。
在多GPU的环境下,你只需要:
t2t-trainer \
--worker_gpu=8 \
--problem=translate_ende_wmt32k \
--model=transformer \
--hparams_set=transformer_big \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
仅仅增加了一行--worker_gpu=8,你的模型就可以在8个GPU的机器上并行训练!
在Cloud TPU环境里,你只需要:
t2t-trainer \
--use_tpu --cloud_tpu_name=$TPU_NAME \
--problem=translate_ende_wmt32k \
--model=transformer \
--hparams_set=transformer_big \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
在具有超参数调整的Cloud ML引擎里,你只需要:
t2t-trainer \
--cloud_mlengine --worker_gpu=8 \
--autotune --autotune_maximize \
--autotune_objective='metrics/neg_log_perplexity' \
--autotune_max_trails=100 \
--autotune_parallel_trials=20 \
--hparams_range=transformer_base_range \
--problem=translate_ende_wmt32k \
--model=transformer \
--hparams_set=transformer_big \
--generate_data \
--data_dir=$DATA_DIR \
--output_dir=$TRAIN_DIR \
--train_steps=$TRAIN_STEPS \
--eval_steps=$EVAL_STEPS
想要更多控制?
Tensor2Tensor提供了很多十分方便的工具,但是如果我想要更加精细的控制,该怎么做呢?
Datasets 数据集
首先,很多人想要控制的就是数据集。比如很多人不想用Tensor2Tensor里面的数据集,而仅仅使用其中的一部分,那么我该怎么做呢?
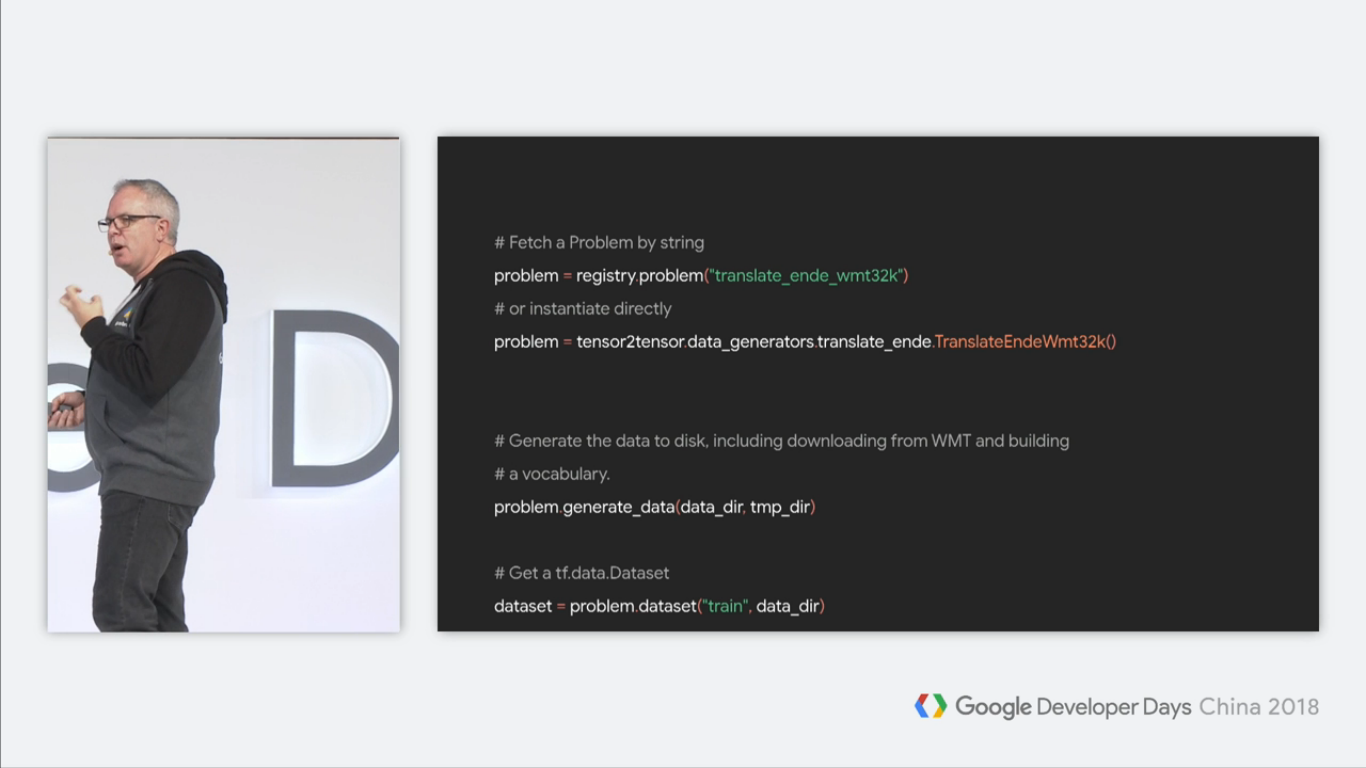
首先,我们创建出对应的problem,然后指定一个数据目录data_dir,然后生成数据。
现在,我们有了这个数据,那么你就可以进行你想要的任何操作,这样就实现了数据集的更精细的控制。
用Keras实现模型
还有一部分人想用Keras layers来实现模型。
Tensor2Tensor已经实现了很多模型,如果有人想在这基础之上,构建更好地模型,它们需要这样做(举个例子):
# 选择超参数
hparams = registry.hparams('bytenet_base')
# 实例化模型
model = tensor2tensor.models.byte_net.ByteNet(hparams,mode='train')
# 调用模型
features = {'inputs':embedded_inputs,'targets':embedded_targets}
outputs,_ = model(feature)
首先获取超参数,并且构建出模型,然后通过调用,就可以获得输出。
演讲者说的内容和标题似乎有点牵强,这里没有看出来和keras有什么直接关系。
实现自己的数据集和模型
要实现自己的数据集和模型,你可以这样做:
- 继承
Problem或者它的子类来创建自定义的数据集 - 继承
T2TModel来实现自己的模型
总结
目前,我们的Tensor2Tensor包含以下内容:
- Datasets 数据集
- Models 模型
- Scripts 脚本
接下来,主要从以下方面改进我们的工作:


