

Google 开发者大会 (Google Developer Days,简称 GDD) 是展示 Google 最新开发者产品和平台的全球盛会,旨在帮助你快速开发优质应用,发展和留住活跃用户群,充分利用各种工具获得更多收益。2018 Google 开发者大会于 9 月 20 日和 21 日于上海举办。👉Google 开发者大会 2018 掘金专题
2018 年 9 月 21 日 ,冯亦菲(Google Brain 软件工程师)带来一场《用 TensorFlow 高层 API 来构建机器学习模型》的演讲,本文将对演讲做一个回顾。
如何机器学习模型
- 首先获取数据集,并明确机器学习所要解决的问题;
- 接下来处理数据集,让我们的模型能够快速的理解形式;
- 紧接着搭建机器学习模型的结构,并且训练评估我们的模型;
- 最后,当模型达到我们预先设定的目标,就可以将其打包投入到生产环境中去。
机器学习问题
推测自然保护区类型

本例中的所使用的数据集为科罗拉多州森林植被数据集。该数据集记录了美国科罗拉多州不同地块的森林植被类型,每个样本包含了描述每块土地的若干特征,包括海拔、坡度、到水源的距离、遮阳情况和土壤类型,并且随同给出了地块的已知森林植被类型。数据集下载
数据样本
按照链接地址下载的原始数据集是以逗号分割、每行有55个整数列,如下图:

每一列所代表的含义如下图所示:

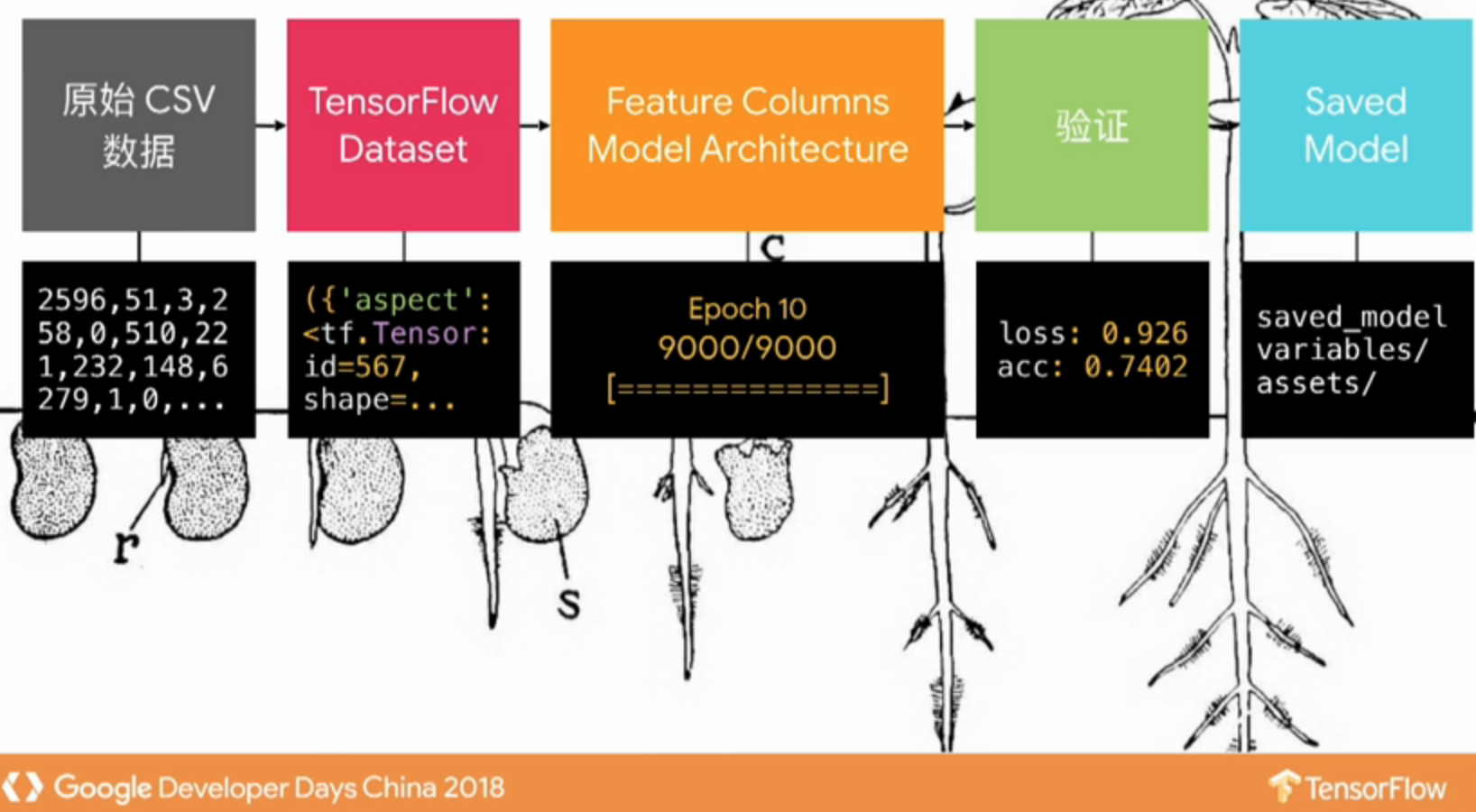
使用 TensorFlow构建模型
在了解我们所有的数据集之后,可以着手使用 TensorFlow 来构建我们的模型。
首先 import tensorflow
import tensorflow as tf
接下来,冯亦菲推荐使用 Eager Execution 立即执行
tf.enable_eager_execution()
eager 执行模型

- 快速调试即刻的运行错误并通过 Python 工具进行整合
- 借助易于使用的 Python 控制流支持动态模型
- 为自定义和高阶梯度提供强大支持
- 适用于几乎所有可用的 TensorFlow 运算
使用tensorflow 提供的 Dataset 加载数据.我们下载的数据格式为 .csv,所以我们用的是 CsvDataset。
dataset = tf.contrib.data.CsvDataset(
filenames = ['covtype.csv.train']
record_defaults = [tf.int32] * 55)
print(list(dataset.take(1)))
查看 dataset 中第一行数据。

解析原始数据集
col_names = ['elevation','aspect','slope'...]
//特征名称
def _parse_csv_row(*vals):
soil_type_t = tf.convert_to_tensor(vals[14:54])
//土壤类型是一个特征,而不是 40 个单独的特征
feat_vals = vals[:10] + (soil_type_t, vals[54])
//重新组成 12 个特征
features = dict(zip(col_names, feat_vals))
//给每个特征取一个名称
class_label = tf.argmax(vals[10:14], axis = 0)
//生成自然保护区标签,在原始数据集中它的一个长度为 4
return features, class_label
解析数据
dataset = dataset.map(_parse_csv_row).batch(64)
//利用解析函数解析,并以 64 为单位对训练集进行分组
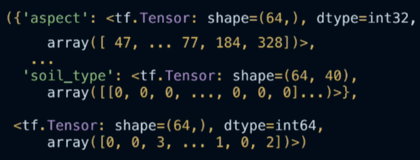
print(list(dataset.take(1)))
因为我们使用的是 Eager 执行模式,所以我们可以直接打印查看数据,如下图所示:
定义数据特征
使用 feature_column, 将原始数值变成模型可理解的数值。
# Cover_Type / integer / 1 to 7
cover_type = tf.keras.feature_column.
categorical_column_with_identity(
'cover_type', num_buckets=8
)
//把离散的类别,变成对模型有意义的连续的数值
cover_embedding = tf.kears.feature_column.
embedding_column(cover_type,dimension = 10)
numeric_features = [tf.keras.feature_column.
numeric_column(feat) for feat in numeric_cols]
soil_type = tf.keras.feature_column.
numeric_column(soil_type, shape = (40,))
columns = numeric_features + [
soil_type, cover_embedding]
feature_layer = tf.keras.feature_column.
FeatureLayer(columns)
构造模型
这里我们使用的是 keras API 来搭建我们的模型,通过 keras 可以像搭积木一样来构造模型。
model = tf.keras.Sequential([
feature_layer,
tf.keras.layers.Dense(256, activation = tf.nn.relu),
tf.keras.layers.Dense(16, activation = tf.nn.relu),
tf.keras.layers.Dense(8, activation = tf.nn.relu),
tf.keras.layers.Dense(4, activation = tf.nn.softmax)
])
model.fit(dataset,steps_per_epoch = NUM_TRAIN_EXAMPLES/64)
训练结果如下:

验证模型
加载验证数据
def load_data(*filenames):
dataset = tf.contrib.data.CsvDataset(
filenames,record_defaults)
dataset = dataset.map(_parse_csv_row)
dataset = dataset.batch(64)
return dataset
验证
test_data = load_data('covtype.csv.test')
loss, accury = model.evaluate(
test_data,
steps = 50
)
print(loss, accury)
损失值与准去率如下图所示:

输出模型
如果验证结果达到我们所设定的要求,可以利用 SavedModel 打包。
export_dir = tf.contrib.saved_model.
save_keras_model(model, 'keras_nn')
//重新训练已训练的模型
restored_model = tf.contrib.saved_model.
save_keras_model(export_dir)
Wide & Deep 模型
前面我们使用的是 keras 模型,下面我们使用 Wide & Deep 模型就实现。
model = tf.estimator.DNNLinearCombinedClassifier(
linear_feature_columns = [cover_type, soil_type],
dnn_feature_columns = numeric_features,
dnn_hidden_unites = [256, 16, 8]
n_classes = 4
)
//训练
model.train(
input_fn = lambda: load_data('covtype.csv.train'))
//验证
model.evaluate(
input_fn = lambda: load_data('covtype.csv.test'))
//输出
features_sample = list(dataset.take(1))[0][0]
input_receiver_fn = tf.estimator.export.
bulid_raw_serving_input_receiver_fn(
features_sample)
//重新训练已训练的模型
model.export_saved_model(
export_dir_base = 'wide_deep',
serving_input_receiver_fn = input_receiver_fn)
总结

 阅读更多 Google 开发者大会 2018 技术干货
阅读更多 Google 开发者大会 2018 技术干货
