

大数据平台日志存储分析系统是在大数据平台下,针对业务系统产生的日志记录进行存储和分析。日志数据来自ElasticSearch存储的日志历史数据,并将需要存储和分析的日志数据从ElasticSearch中读取到Kafka中。Kafka的消费者在侦听到数据消息进入后,以流方式获取数据写入到HBase中。存储在HBase中的数据则是为日志数据的检索与分析提供服务。Web前端通过调用后端API检索HBase中的数据,并进行透视表的可视化展现,展现后的数据支持CSV导出功能。
本解决方案包括的系统功能为:
- 读取Kafka消息,存储到HBase
- 检索HBase数据,提供API
- 显示内容的CSV导出
技术方案
确定该技术方案的前置条件包括:
- 推送到Kafka的消息已经准备就绪
- HBase的数据结构已经确定
- 日志检索条件固定
- 后端API已经确定,Web前端会调用该API
- Web前端开发已经就绪
技术架构
整个技术架构如下图所示: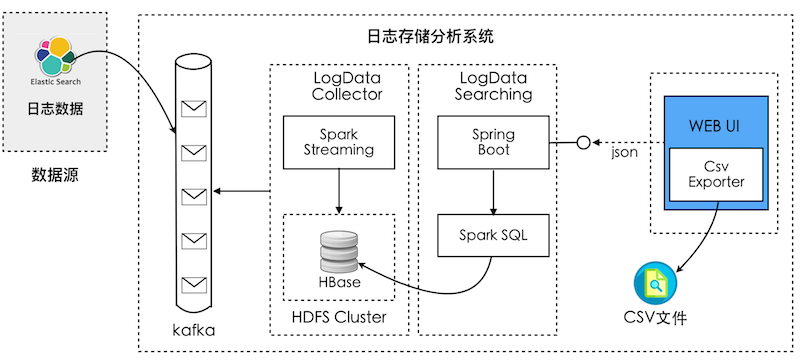
系统分为三个模块:
- LogData Collector:通过Spark Streaming订阅Kafka的Topic,收集业务需要的日志数据,然后写入到HBase中。HBase搭建在HDFS的集群中。
- LogData Searching:这是一个Spring Boot服务,通过
@RestController暴露API接口给前端。其内部则集成Spark,利用Spark SQL查询HBase数据库。 - Web UI前端:负责调用LogData Searching服务,并将数据呈现到UI上,并在前端实现显示数据的导出。
说明:导出功能可能有一个变化,倘若前端是分页显示,而导出的数据是符合检索条件的全量数据,则需要在导出时调用LogData Searching服务,获得导出所需的数据,而非前端已经显示的数据。
